두 달 동안 아무도 정체를 몰랐다
OpenRouter라는 서비스가 있다. 개발자가 클로드, GPT, 제미나이처럼 여러 회사의 AI 모델을 각각 계약하지 않고 한 창구에서 골라 쓸 수 있게 중개해주는 곳이다. 편의점에서 여러 브랜드 음료를 한 냉장고에 놓고 파는 것과 비슷하다. 이곳은 어떤 모델이 실제로 얼마나 불려 나갔는지 호출량 순위도 공개한다. 개발자들이 말이 아니라 지갑과 작업으로 투표한 결과라, 어떤 벤치마크 점수보다 정직한 인기 지표로 통한다.
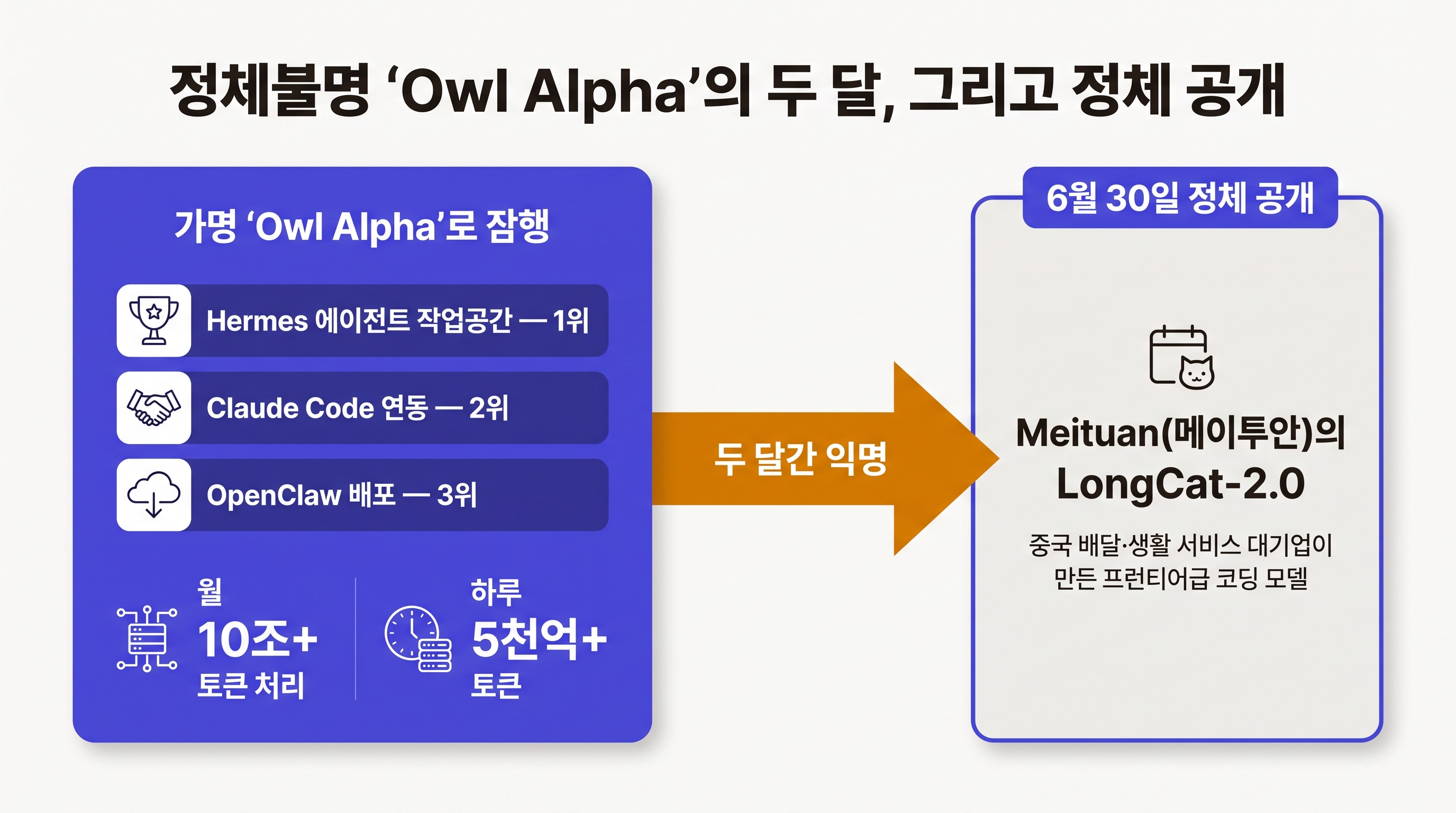
지난 두 달, 그 순위 꼭대기 근처를 'Owl Alpha'라는 이름 모를 모델이 지키고 있었다. 어느 회사가 만들었는지, 크기가 얼마인지, 무엇으로 훈련했는지 아무 설명이 없었다. 그런데도 에이전트 작업 공간인 Hermes에서 1위, Claude Code 연동에서 2위, OpenClaw 배포에서 3위에 올랐다. 월 10조 개가 넘는 토큰을 처리했고, 하루로 치면 5천억 개가 넘는다. 토큰은 AI가 글을 읽고 쓸 때 다루는 최소 단위인데, 이 정도 물량이면 취미로 한번 써본 수준이 아니라 수많은 개발자가 실제 업무에 붙여 매일 돌리고 있었다는 뜻이다.
정체는 6월 30일에 드러났다. 중국의 배달 및 생활 서비스 대기업 메이투안이 자사 모델 LongCat-2.0을 공개하면서, 그동안 Owl Alpha라는 가명으로 조용히 성적을 쌓아온 게 바로 이 모델이라고 밝혔다. 배달 앱 회사가 프런티어급 코딩 모델을 만들었다는 사실도 놀랍지만, 진짜 이야기는 그 모델을 무엇으로 훈련했는가에 있었다.
왜 이름을 숨기고 시작했나
먼저 이 '스텔스 공개' 전략부터 짚어야 한다. 보통 새 모델은 요란한 발표와 함께 나온다. 성능 표를 잔뜩 붙이고, 자사 모델이 무엇을 이겼는지 강조한다. 메이투안은 정반대로 갔다. 이름도 회사도 밝히지 않은 채 모델을 시장에 풀어놓고, 개발자들이 진짜로 계속 쓰는지부터 지켜봤다.
이 방식이 영리한 이유는 간단하다. 벤치마크 점수는 얼마든지 특정 시험에 맞춰 부풀릴 수 있지만, 개발자가 자기 돈과 시간을 들여 두 달을 계속 쓰는 건 조작하기 어렵다. 브랜드 후광도 없었다. 'OpenAI가 만들었다니까 한번 써보자' 같은 편향 없이, 순수하게 결과물만 보고 남은 사용자들이었다. 그렇게 쌓인 실사용 기록은 나중에 정식으로 이름을 밝혔을 때 그 어떤 마케팅 문구보다 강한 근거가 됐다. "이미 두 달간 여러분이 써온 그 모델입니다"라는 한 문장이 성능 표 백 줄을 대신한 셈이다.
1조 6천억이라는 숫자, 그리고 실제로 깨어나는 부분
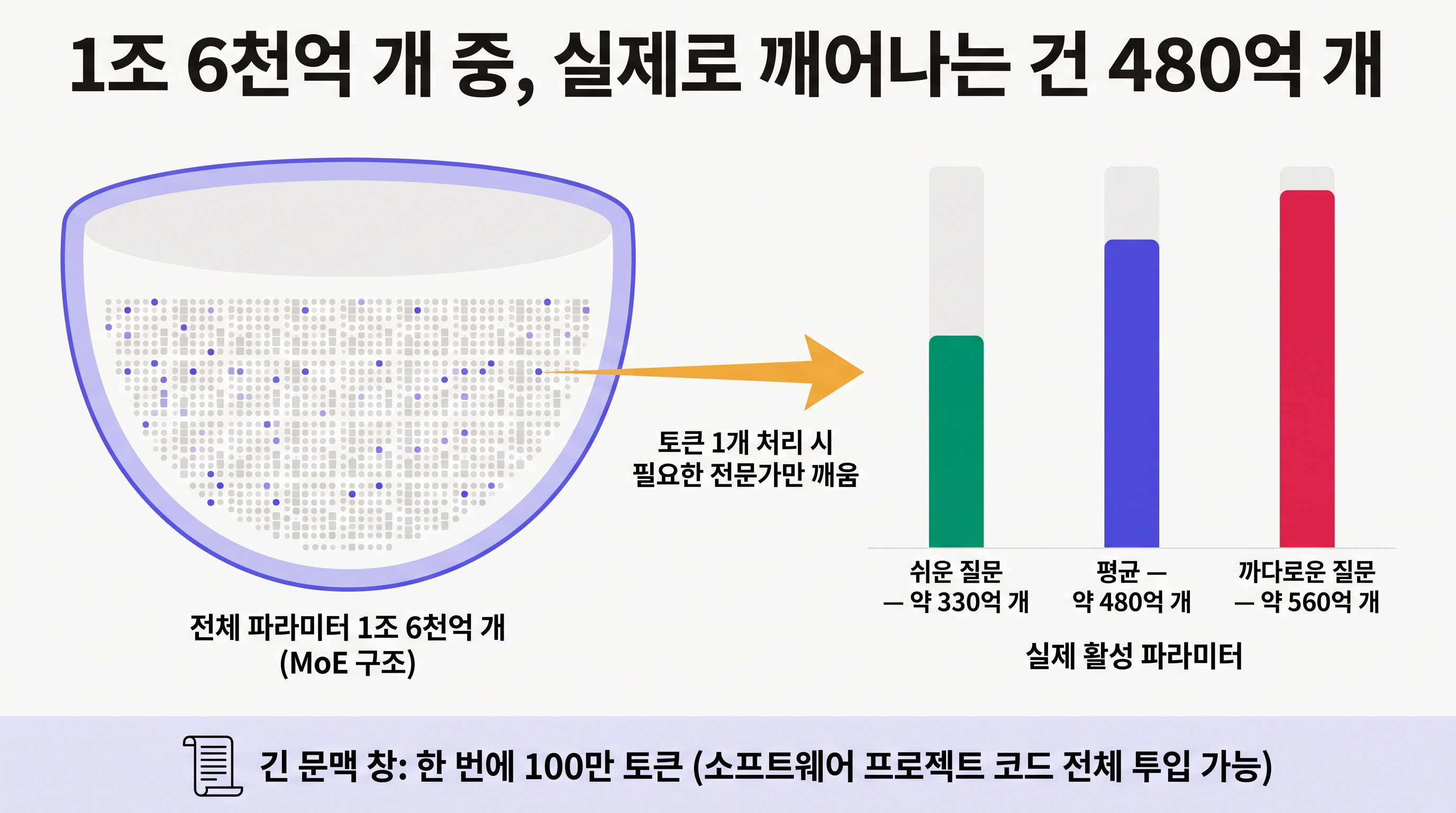
LongCat-2.0은 전체 파라미터가 1조 6천억 개다. 파라미터는 모델이 학습을 통해 조정하는 내부 숫자들로, 대략 모델이 지식을 담아두는 그릇의 크기쯤 된다. 숫자만 보면 어마어마하지만, 여기엔 함정이 하나 숨어 있다. 이 모델은 MoE 구조이기 때문이다.
MoE는 Mixture of Experts, 우리말로 옮기면 전문가 혼합 방식이다. 하나의 거대한 두뇌가 모든 질문에 통째로 반응하는 대신, 안에 작은 전문가 여러 명을 두고 질문 종류에 따라 필요한 전문가만 골라 깨우는 구조다. 종합병원에 비유하면, 환자가 올 때마다 모든 과 의사가 우르르 달려드는 게 아니라 접수처가 증상을 보고 해당 과로만 보내는 것과 같다. LongCat-2.0은 전체 1조 6천억 개 중에서 토큰 하나를 처리할 때 실제로는 약 480억 개만 깨운다. 질문이 쉬우면 330억 개 근처로 줄고 까다로우면 560억 개까지 늘어나는 식으로, 문제 난이도에 맞춰 동원하는 인력을 조절한다.
이 구조가 중요한 이유는 비용이다. 1조 6천억 개를 전부 계산에 동원하면 답 한 번 내는 데 드는 연산과 전기가 감당이 안 된다. 필요한 부분만 켜니까 덩치가 주는 지식은 유지하면서도 실제 돌아갈 때는 가볍고 빠르다. 여기에 한 번에 100만 토큰까지 읽을 수 있는 긴 문맥 창을 갖췄다. 100만 토큰이면 웬만한 소프트웨어 프로젝트의 코드 전체를 한꺼번에 집어넣고 "이 구조 안에서 이 버그를 고쳐줘"라고 시킬 수 있는 분량이다. 코드베이스를 잘게 잘라 넣으며 맥락이 끊기는 일이 줄어드니, 대형 프로젝트를 다루는 개발자에게는 체감이 크다.
진짜 뉴스는 성능이 아니라 '무엇으로 만들었나'였다
여기까지는 요즘 나오는 좋은 오픈소스 모델의 흔한 스펙이다. 메이투안 공개가 업계를 술렁이게 한 대목은 따로 있다. 이 모델을 처음부터 끝까지 중국산 칩만으로 훈련하고 서비스했다는 주장이다.
배경을 알아야 이 문장의 무게가 보인다. 지금까지 큰 AI 모델은 사실상 예외 없이 엔비디아 GPU로 훈련해왔다. 그런데 미국은 몇 년째 첨단 AI 칩의 중국 수출을 막는 수출통제를 걸어두고 있다. 최신 엔비디아 칩을 중국이 대량으로 사기 어렵게 만들어, AI 경쟁에서 앞서가려는 조치다. 그동안 나온 중국 모델들도 상당수는 제재 이전에 확보했거나 우회로로 들여온 엔비디아 칩에 기대왔다. 그래서 "중국이 자국 칩으로 프런티어 모델을 만들 수 있느냐"는 질문은 오래 열려 있던 물음이었다.
LongCat-2.0은 그 질문에 실물로 답했다. 메이투안은 5만 개가 넘는 중국산 가속기로 35조 개가 넘는 토큰을 학습시켰다고 밝혔다. 가속기란 AI 계산을 전담하는 전용 칩을 통칭하는 말이고, 그중에서도 특정 작업에 특화해 설계한 칩을 ASIC이라 부른다. 범용으로 이것저것 다 하는 GPU와 달리, ASIC은 정해진 계산만 빠르고 효율적으로 처리하도록 회로 자체를 그 용도에 맞춰 굳혀 만든다.
다만 정직하게 짚을 대목이 있다. 메이투안은 어느 회사의 무슨 칩을 썼는지 끝내 밝히지 않았다. 업계에서는 화웨이의 어센드 계열을 유력하게 보지만 확인된 사실은 아니다. 그래서 지금 확실하게 말할 수 있는 건 딱 여기까지다. 메이투안이 국산 칩만으로 훈련과 추론을 다 했다고 공개적으로 주장했고, 정작 그 칩이 무엇인지는 밝히지 않았다는 것. 검증은 아직 남아 있다.
모델을 '시작'하는 것보다 '끝내는' 게 어렵다
칩 이야기에서 흔히 놓치는 지점이 있다. 진짜 어려운 건 훈련을 시작하는 게 아니라 끝까지 멈추지 않고 완주하는 일이다.
5만 개짜리 칩이 몇 주에서 몇 달을 쉬지 않고 한 덩어리처럼 맞물려 돌아가야 하는데, 이 규모에서는 사소한 문제가 재앙이 된다. 칩 하나가 계산을 아주 미세하게 다르게 하거나, 칩끼리 데이터를 주고받는 통신에 잠깐 장애가 생기거나, 학습 도중 숫자가 널뛰기 시작하면 그동안 쌓은 학습이 통째로 어긋난다. 그러면 마지막으로 멀쩡했던 지점까지 되돌려 다시 돌려야 하는데, 이 되돌리기가 잦아질수록 시간과 전기가 눈덩이처럼 불어난다. 엔비디아 생태계는 이런 문제를 다루는 소프트웨어와 노하우가 십수 년간 다져져 있다. 처음 쓰는 국산 칩 위에서 이 모든 걸 안정적으로 붙잡아두는 건 완전히 다른 난이도의 일이다.
메이투안은 이 대목을 특히 강조했다. 35조 토큰짜리 훈련을 큰 되돌리기나 회복 불가능한 사고 없이 완주했다는 것이다. 통신 장애, 메모리 압박, 수치 안정성, 계산 결과의 일관성, 대규모 분산 복구 같은 문제를 실제로 풀어냈다는 이야기다. 사실이라면 이건 단순히 칩 성능이 좋다는 자랑을 넘어선다. 칩 한 종류가 아니라, 그 칩 위에서 초대형 학습을 끝까지 운영하는 엔지니어링 역량 전체가 어느 선까지 올라왔다는 신호이기 때문이다. 물론 이 역시 메이투안의 자체 발표이고, 외부의 독립 재현은 아직 나오지 않았다.
성능은 어느 정도인가, 과장 없이

그렇다면 이 모델, 실력은 진짜로 얼마나 될까. 정직하게 보는 게 낫다. 최상위는 아니지만 최상위 바로 아래라는 게 지금까지의 그림이다.
코딩 실력을 재는 대표 시험인 SWE-bench Pro에서 LongCat-2.0은 59.5점을 받았다. 이 시험은 실제 오픈소스 프로젝트에서 가져온 버그를 모델이 스스로 고치게 하고 정답 여부를 채점한다. 같은 시험에서 GPT-5.5가 58.6점이니 근소하게 앞선다. 다만 클로드 Opus 4.8의 69.2점과는 아직 뚜렷한 격차가 있다. 여기서 냉정할 필요가 있다. GPT-5.5를 앞선 0.9점 차이는 이 정도 규모의 시험에서는 측정 오차 안에 들어가는 수준이라, "GPT를 이겼다"고 못 박기엔 이르다. 에이전트 작업을 재는 FORTE에서는 73.2점으로, GPT-5.5의 77.8점에는 못 미쳤다.
정리하면 이렇다. 최고 자리를 뺏은 모델은 아니다. 하지만 최상위 독점 모델 바로 아래 그룹에, 그것도 누구나 가져다 쓸 수 있는 열린 모델로 들어섰다. 두 달간 개발자들이 정체도 모른 채 매일 붙여 쓴 사실 자체가, 벤치마크 몇 점보다 실전에서 쓸 만하다는 증거에 가깝다.
'열린 모델'이라는 말도 한 번 풀어둘 필요가 있다. GPT나 클로드는 회사가 서버 안에 모델을 가둬두고, 사용자는 정해진 창구로 질문을 넣고 답만 받아온다. 모델 자체를 손에 쥘 수는 없다. 반대로 LongCat-2.0은 모델의 가중치, 그러니까 학습으로 빚어낸 내부 숫자 뭉치 전체를 관대한 라이선스로 풀었다. 회사가 이 파일을 통째로 내려받아 자기 서버에 올려 돌리고, 필요하면 자사 데이터로 다시 다듬어 입맛에 맞게 고칠 수 있다는 뜻이다. 민감한 코드를 외부 API로 내보내기 꺼리는 기업, 요금을 예측 가능하게 묶어두고 싶은 팀에는 이 차이가 결정적이다. 성능이 최상위 바로 아래인데 열려 있기까지 하다면, 계산기를 두드리는 쪽에서는 선택지가 하나 더 늘어난 게 아니라 판단 기준 자체가 바뀐다.
값으로 승부를 걸었다
여기에 가격표가 결정타다. LongCat-2.0의 표준 요금은 입력 100만 토큰당 0.75달러, 출력 100만 토큰당 2.95달러다. 지금은 출시 기념으로 각각 0.30달러와 1.20달러까지 내렸고, 한 번 읽은 문맥을 다시 넣을 때 드는 비용은 아예 받지 않는다.
비교해보면 격차가 확연하다. GPT-5.5는 입력 5달러, 출력 30달러다. 클로드 Sonnet 5의 도입가가 입력 2달러, 출력 10달러인 것과 견줘도 몇 배 싸다. 출력이 특히 중요한데, 코딩 에이전트는 긴 코드를 계속 뱉어내느라 출력 토큰을 많이 쓴다. 출력이 10분의 1 값이면 하루 종일 코드를 짜게 시키는 작업에서 요금 차이가 눈덩이처럼 벌어진다. 실력이 최상위 바로 아래인데 값은 한참 아래라면, 손이 가는 게 당연하다. 두 달간 조용히 순위를 끌어올린 힘의 상당 부분이 여기 있었다고 봐야 한다.
다만 지금 값이 계속 갈 거라고 단정하긴 이르다. 절반 넘게 깎인 지금 요금은 출시 기념 할인이고, 할인이 끝나도 표준 요금 자체가 경쟁사보다 낮긴 하지만, 초대형 모델을 돌리는 실제 원가를 이 값이 감당하는지는 밖에서 알기 어렵다. 시장을 먼저 차지하려 원가를 밑도는 값을 부르는 건 이 바닥에서 드문 일이 아니다. 열린 모델이라 정 아쉬우면 직접 내려받아 돌리는 길이 열려 있다는 점이 그나마 사용자 쪽의 보험이 된다.
왜 하필 배달 회사였나
마지막으로 남는 물음. 검색이나 클라우드 회사도 아니고, 왜 배달 앱 회사가 이걸 해냈을까.
곱씹어보면 뜻밖도 아니다. 메이투안은 수억 명의 주문과 라이더 동선, 매장 재고를 실시간으로 처리해온 회사다. 수만 대 서버를 흔들림 없이 굴리는 대규모 인프라 운영과 엔지니어 인력이 이미 안에 쌓여 있었다. 초대형 모델 훈련에서 정작 발목을 잡는 게 앞서 본 '끝까지 안정적으로 돌리기'라면, 물류와 배차라는 거대한 실시간 시스템을 매일 돌려온 회사가 그 근육을 이미 갖고 있던 셈이다.
그리고 여기에 곱씹을 만한 시사점이 있다. 미국의 정책도, 해외 투자자도 프런티어 AI가 나올 곳으로 검색 엔진과 클라우드 대기업, 전문 AI 스타트업을 주로 지켜봤다. 그 시야 밖에 있던 배달 회사가, 규제망이 촘촘히 감시하지 않던 자리에서 국산 칩으로 프런티어급 모델을 완주해 내놓았다. 이건 단순히 모델 하나가 잘 나왔다는 이야기가 아니라, '어디서 이런 게 나오는지'에 대한 기존 지도가 틀렸을 수 있다는 신호다. 수출통제는 특정 칩이 국경을 넘는 걸 막을 수는 있어도, 그 칩 없이도 굴러가는 시스템이 예상 밖의 회사에서 조립되는 것까지 막지는 못한다는 사실을, LongCat-2.0은 실물로 보여줬다.
물론 칩의 정체도, 훈련 안정성 주장도, 벤치마크의 재현도 아직 외부 검증을 기다리고 있다. 지금 확실한 건 하나다. 두 달간 이름 없이 개발자 순위를 지켜온 모델이 있었고, 그 뒤에는 엔비디아가 없었다.