회원가입을 만들었는데, 이 정보는 어디에 저장하지?
Cursor로 로그인 화면을 만들었다. 이메일과 비밀번호를 입력하는 폼까지는 그럴듯하게 나왔다. 그런데 가입 버튼을 누르면 그 정보가 어디로 가는 걸까. 브라우저를 닫으면 다 날아가는 건 아닌지. 다시 로그인할 때 아까 가입한 사람인지 어떻게 확인하는 건지.
답은 데이터베이스다. 줄여서 DB. 사용자 정보, 게시글, 설정값처럼 "저장해뒀다가 나중에 다시 꺼내야 하는 것"을 담아두는 곳이다.
"그냥 파일에 저장하면 안 되나?" 싶을 수도 있다. JSON 파일에 써놓으면 되지 않냐고. 사용자가 혼자면 그래도 된다. 하지만 10명이 동시에 가입하면 어떻게 될까. 한 명이 파일을 쓰는 도중에 다른 사람도 쓰려고 하면 데이터가 꼬인다. 특정 사용자만 빠르게 찾고 싶을 때도 파일 전체를 뒤져야 한다. 데이터베이스는 이 문제를 해결한다. 동시에 여러 사람이 읽고 써도 안전하고, 원하는 데이터만 골라서 빠르게 꺼내준다.
SQL 데이터베이스: 엑셀에 가까운 구조
데이터베이스는 크게 두 종류로 나뉜다. 먼저 SQL(관계형) 데이터베이스.
엑셀 스프레드시트를 떠올려보자. 열(column)이 이름, 이메일, 가입일로 정해져 있고 한 행(row)이 사용자 한 명이다. 새 사용자가 오면 행을 추가한다. 모든 사용자가 같은 형식으로 저장된다.
사용자 시트
| id | 이름 | 이메일 | 가입일 |
|----|--------|------------------|------------|
| 1 | 김민수 | min@example.com | 2026-02-01 |
| 2 | 이지은 | ji@example.com | 2026-02-03 |
SQL의 강점은 시트끼리 "관계"를 맺을 수 있다는 점이다. 게시글 시트에 "작성자_id"라는 열을 두면 사용자 시트의 id와 연결된다. "김민수가 쓴 글 전부 보여줘"가 한 줄이면 끝난다.
SELECT * FROM 게시글 WHERE 작성자_id = 1;
엑셀에서 VLOOKUP으로 다른 시트를 참조하는 것과 비슷하다. 다만 DB는 이걸 수백만 건 데이터에서도 순식간에 해낸다.
대표적인 SQL 데이터베이스는 PostgreSQL과 MySQL이다. 바이브 코더가 만나게 될 호스팅 DB 대부분이 이 둘 중 하나를 기반으로 돌아간다.
NoSQL 데이터베이스: 서류 봉투에 가까운 구조
NoSQL(비관계형) 데이터베이스는 접근이 다르다. 서류 봉투를 떠올려보자. 봉투마다 들어있는 내용이 달라도 된다. 어떤 봉투에는 이름과 이메일만 있고, 다른 봉투에는 전화번호와 프로필 사진 URL까지 들어있어도 상관없다.
// 봉투 1
{
"이름": "김민수",
"이메일": "min@example.com"
}
// 봉투 2
{
"이름": "이지은",
"이메일": "ji@example.com",
"전화번호": "010-1234-5678",
"프로필사진": "https://..."
}
이 유연함이 장점이자 단점이다. 데이터 구조가 수시로 바뀌는 앱에서는 편하지만 "모든 사용자의 이메일 목록"처럼 정형화된 조회에는 SQL이 훨씬 효율적이다.
대표적인 NoSQL로는 MongoDB와 Firebase의 Firestore가 있다.
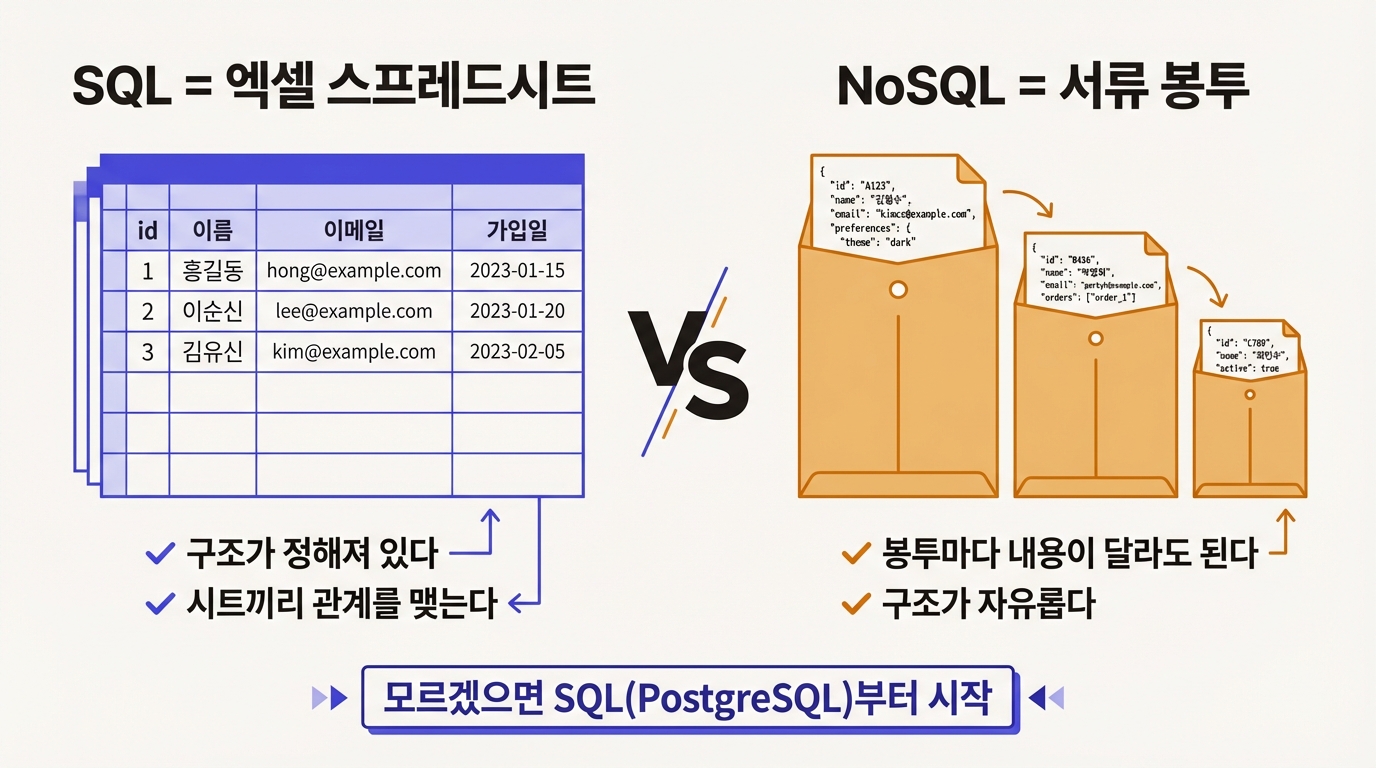
모르겠으면 SQL이다
바이브 코더가 만드는 사이드 프로젝트 대부분은 SQL로 충분하다. 사용자, 게시글, 댓글, 주문. 이런 데이터는 구조가 명확하고 서로 관계가 있다. SQL이 잘하는 영역이다.
NoSQL이 더 나은 상황도 있긴 하다. 채팅 메시지처럼 구조가 단순하면서 양이 폭발적으로 늘어나는 경우, 또는 IoT 센서 데이터처럼 기기마다 보내는 필드가 다른 경우. 하지만 처음 만드는 앱이라면 SQL부터 시작하는 게 맞다. 나중에 NoSQL을 추가하는 건 어렵지 않지만, NoSQL로 시작했다가 관계형 데이터가 필요해지면 구조를 뜯어고쳐야 한다.
뭘 골라야 할지 모르겠으면 PostgreSQL. 이것만 기억하면 된다.
호스팅 DB: 남의 컴퓨터에 있는 엑셀
데이터베이스를 내 컴퓨터에 직접 설치해서 돌릴 수도 있다. 하지만 24시간 컴퓨터를 켜놓아야 하고, 보안 패치도 내가 해야 하고, 백업도 신경 써야 한다. 호스팅 DB는 이걸 전부 대신 해준다. 남의 컴퓨터에 있는 엑셀인 셈이다. 인터넷만 되면 어디서든 접속할 수 있고, 관리는 업체 몫이다.
바이브 코더가 실제로 고를 수 있는 선택지 네 가지를 정리했다.
Supabase: DB가 처음이면 여기부터
Supabase는 PostgreSQL에 인증, 파일 저장, 실시간 구독까지 얹어놓은 올인원 플랫폼이다. DB만 달랑 주는 게 아니라 로그인, 이미지 업로드, 실시간 동기화까지 한 곳에서 된다.
첫 번째 선택지로 추천하는 이유는 진입 장벽이다. 웹 대시보드에서 테이블을 만들고 데이터를 넣는 과정이 거의 엑셀 수준이다. SQL을 몰라도 클릭으로 테이블을 설계할 수 있다. "Supabase + Next.js" 조합 가이드가 인터넷에 넘쳐나니까 막히면 검색으로 해결된다는 것도 크다.
무료 플랜 기준이다.
- 데이터베이스 저장소: 500MB
- 대역폭: 월 2GB
- 인증 사용자: 월 5만 명
- 파일 저장: 1GB
- Edge Functions: 월 50만 호출
한 가지 주의할 점. 7일간 요청이 없으면 프로젝트가 자동으로 멈춘다. 무료 플랜의 가장 큰 제약이다. 혼자 만들어보는 단계에서는 문제없지만 실제 사용자를 받으려면 유료 플랜(월 $25)이 필요하다.
Neon: DB만 깔끔하게 쓰고 싶다면
Neon도 PostgreSQL 기반이다. Supabase와 뭐가 다르냐면, Neon은 DB 자체에 집중한다. 인증이나 파일 저장 같은 부가 기능 없이 순수하게 좋은 PostgreSQL을 서버리스로 제공한다.
눈에 띄는 기능이 두 가지 있다. 첫째, 요청이 없으면 DB가 알아서 꺼지고 요청이 오면 다시 켜진다(scale-to-zero). 무료 플랜에서도 작동해서 비용 걱정이 없다. 둘째, 데이터베이스 브랜칭이 된다. Git에서 브랜치를 따듯 DB를 복제해서 실험하고, 괜찮으면 합칠 수 있다.
무료 플랜 기준이다.
- 데이터베이스 저장소: 프로젝트당 512MB
- 컴퓨트: 월 100 CU-hours (0.25 CU 기준 약 400시간 연속 가동 가능)
- 프로젝트: 최대 100개
- 대역폭: 5GB
올인원이 필요하면 Supabase, DB만 쓰고 나머지는 직접 붙이겠다면 Neon이다. Vercel과 궁합이 좋아서 Vercel에 배포한 Next.js 앱의 DB로 Neon을 쓰는 조합이 흔하다.
MongoDB Atlas: NoSQL이 필요할 때
MongoDB는 대표적인 NoSQL(문서형) 데이터베이스다. 위에서 말한 서류 봉투 구조. Atlas는 MongoDB를 호스팅해주는 서비스다.
JSON과 구조가 비슷하니까 JavaScript 개발자에게 친숙하다. 테이블 구조를 먼저 정의할 필요 없이 JSON 객체를 그냥 넣으면 된다.
무료 플랜(M0) 기준이다.
- 저장소: 512MB
- 공유 클러스터(전용 서버 아님)
- 연결 수: 500
- 만료 없음, 카드 등록 불필요
512MB면 사이드 프로젝트에는 넉넉하다. 다만 Prisma 같은 인기 ORM과의 호환이 SQL 계열만큼 매끄럽지 않다는 점은 알아두자.
SQL이 맞는지 NoSQL이 맞는지 확신이 없다면 SQL부터 시작하는 게 낫다. MongoDB는 "문서형 DB가 필요하다"는 확신이 있을 때 고르면 된다.
Firebase(Firestore): Google 생태계 안에서
Firebase는 Google이 운영하는 앱 개발 플랫폼이고, Firestore가 그 안의 NoSQL 데이터베이스다. 실시간 데이터 동기화가 기본이라 채팅 앱 같은 데 잘 맞고, Flutter나 React Native로 모바일 앱을 만들 때 붙이기 편하다.
무료 플랜(Spark) 기준이다.
- 저장소: 1GB
- 일일 읽기: 5만 건
- 일일 쓰기: 2만 건
- 일일 삭제: 2만 건
여기서 하나 조심할 게 있다. Firestore는 읽기 횟수로 과금한다. 목록 화면에서 게시글 20개를 보여주면 그게 읽기 20건이다. 무한 스크롤을 달아놓으면 사용자 한 명이 스크롤 몇 번 하는 것만으로 수백 건이 나간다. 무료 한도(일 5만 건)를 모르고 쓰다가 갑자기 앱이 먹통이 되는 경우가 꽤 있다.
웹앱 사이드 프로젝트라면 Supabase나 Neon이 더 단순하다. Firebase는 모바일 앱을 만들거나 Google 서비스(FCM 푸시 알림 등)를 많이 쓸 때 진가를 발휘한다.
PlanetScale은 어디 갔나
바이브 코딩 강좌에서 PlanetScale을 추천하는 글을 본 적 있을 수 있다. 2024년 3월에 무료 플랜이 없어졌다. 최저 유료 플랜이 월 $39니까 사이드 프로젝트에는 맞지 않는다. 예전 가이드에서 PlanetScale을 쓰라고 했다면 Neon이나 Supabase로 갈아타면 된다.
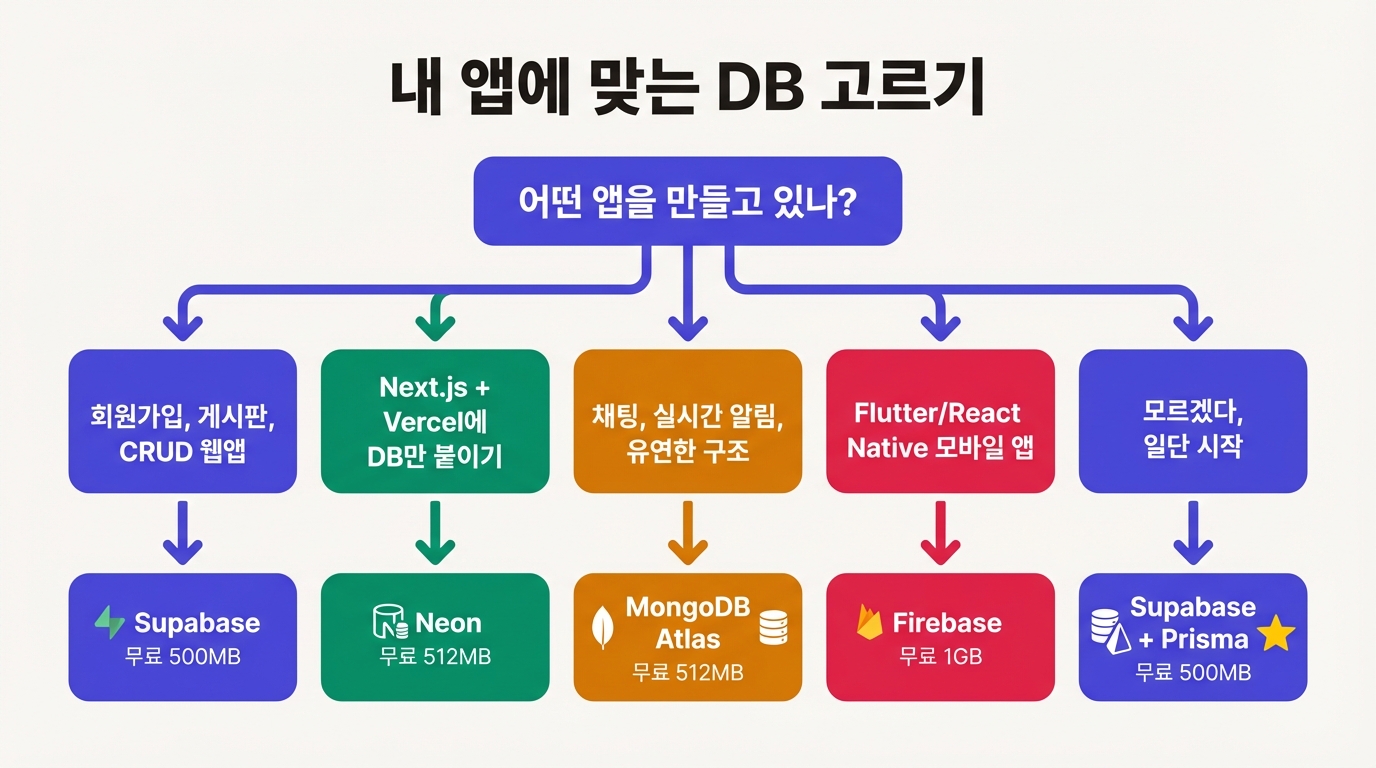
상황별로 고르면 이렇다
표만 늘어놓는 것보다 이게 더 쓸모가 있다.
"회원가입이 있는 웹앱, 게시판, CRUD" Supabase. 인증이 내장이라 별도 로그인 시스템을 만들 필요가 없다. Next.js와 조합하면 튜토리얼도 넘치고 막힐 일이 적다.
"Vercel에 올린 Next.js 앱에 DB만 붙이고 싶다" Neon. Vercel 통합이 잘 돼 있고 DB만 깔끔하게 쓸 수 있다. 인증은 NextAuth나 Clerk 같은 서비스를 따로 붙이면 된다.
"채팅, 실시간 알림, 데이터 구조가 자주 바뀌는 앱" MongoDB Atlas 또는 Firebase. 다만 둘 다 NoSQL이라 관계형 데이터를 다루기엔 불편하다.
"Flutter, React Native 모바일 앱" Firebase. Google 생태계 안에서 인증, 푸시 알림, 분석까지 한 번에 해결된다.
"뭔지 모르겠고 일단 시작하고 싶다" Supabase + Prisma. 이 조합이 지금 커뮤니티에서 가장 레퍼런스가 많다.
ORM: JavaScript로 말하면 SQL로 통역해준다
데이터베이스와 대화하려면 SQL이라는 언어를 써야 한다. JavaScript로 앱을 만들고 있는데 데이터를 가져올 때마다 SQL을 직접 쓰는 건 번거롭다. 언어가 두 개인 셈이니까.
ORM(Object-Relational Mapping)은 통역사다. JavaScript 코드로 "이메일이 이건 사용자 찾아줘"라고 쓰면 ORM이 SQL로 바꿔서 DB에 전달한다.
// Prisma로 사용자 조회
const user = await prisma.user.findUnique({
where: { email: "min@example.com" }
});
// 내부적으로는 이렇게 변환된다
// SELECT * FROM users WHERE email = 'min@example.com';
바이브 코더가 고를 수 있는 ORM은 사실상 두 가지다.
Prisma. 스키마 파일에 테이블 구조를 적으면 타입이 자동 생성된다. 에디터에서 자동완성이 되니까 "이 테이블에 어떤 필드가 있었지?" 하고 기억할 필요가 없다. 문서가 잘 돼 있고 사용자가 많아서 구글링하면 대부분 답이 나온다. 처음이라면 Prisma다.
Drizzle. SQL을 거의 그대로 TypeScript로 옮긴 느낌이다. Prisma보다 가볍고(약 7KB vs 수 MB) 빠르다. 서버리스 환경에서 콜드 스타트를 줄이고 싶거나 SQL에 이미 익숙하다면 좋은 선택이다. 다만 처음 세팅이 Prisma만큼 직관적이지는 않다.
모르겠으면 Prisma부터 시작하면 된다. Drizzle이 필요해지는 시점은 서버리스 배포에서 성능을 깎아야 할 때인데, 그때쯤이면 어느 걸 고를지 스스로 판단할 수 있을 거다.
무료 티어 비교
| 서비스 | DB 유형 | 저장소 | 핵심 제약 |
|---|---|---|---|
| Supabase | PostgreSQL | 500MB | 인증/스토리지 내장, 7일 비활성시 자동 멈춤 |
| Neon | PostgreSQL | 512MB | 서버리스, DB 브랜칭, scale-to-zero |
| MongoDB Atlas | MongoDB | 512MB | NoSQL, 만료 없음, 공유 클러스터 |
| Firebase | Firestore | 1GB | 읽기 5만/일 한도, Google 생태계 |
바이브 코더가 자주 하는 실수
연결 문자열을 코드에 직접 박아넣는다. DB 비밀번호가 포함된 연결 문자열을 소스 코드에 하드코딩하면 GitHub에 올리는 순간 전 세계에 공개된다. .env 파일에 넣고 .gitignore에 .env를 추가해야 한다. GitHub에 올라간 DB 비밀번호를 봇이 자동으로 긁어가서 데이터를 통째로 날리는 일이 실제로 일어난다. 실수하면 진짜 큰일 나는 부분이다.
로컬 DB와 클라우드 DB를 헷갈린다. 개발할 때 내 컴퓨터에 깔린 DB 주소를 배포 환경에서도 그대로 쓰면 당연히 안 된다. 배포할 때는 호스팅 DB의 연결 문자열을 환경변수로 넣어야 한다. 이전 글에서 다룬 "로컬에서는 되는데 배포하면 안 돼요"의 DB 버전이다.
무료 한도를 확인 안 한다. Firebase의 읽기 5만 건 제한, Supabase의 7일 자동 멈춤을 모르고 쓰다가 어느 날 앱이 먹통이 되면 당황스럽다. 가입하면 Pricing 페이지를 한 번은 읽어봐야 한다.
테이블 구조 바꾸기를 무서워한다. 한번 만들면 못 바꾸는 줄 아는 사람이 있다. 개발 중에는 마음껏 바꿔도 된다. Prisma의 npx prisma db push는 스키마 변경을 DB에 바로 밀어넣는다. 사용자 데이터가 쌓인 후에야 신중해져야 하고, 개발 단계에서는 자유롭게 실험해도 된다.
10분이면 DB가 연결된다
여기까지 읽었으면 감이 잡혔을 거다. 가장 빠르게 시작하는 순서를 정리하면 이렇다.
- supabase.com에서 GitHub 계정으로 가입한다
- 새 프로젝트를 만든다 (리전은 Northeast Asia가 한국에서 가장 빠르다)
- 웹 대시보드에서 테이블을 만든다. 엑셀에 열을 추가하는 것과 같다
- Settings > Database에서 연결 문자열을 복사한다
.env에DATABASE_URL=복사한_문자열을 넣는다npx prisma init후 스키마를 정의하고npx prisma db push
10분이면 끝난다. 처음에는 사용자 테이블 하나만 만들어도 충분하다. "이렇게 데이터가 저장되는 거구나" 하는 감각을 잡는 게 먼저다. 서비스를 잘못 골랐다 싶으면 ORM이 있으니 옮기면 된다. Prisma 스키마는 그대로 두고 연결 문자열만 바꾸면 다른 PostgreSQL 서비스로 이동할 수 있다. 처음부터 완벽하게 골라야 하는 게 아니다.