"데모 하나 올렸을 뿐인데" 요금이 폭탄이 됐다
Claude Code한테 "사용자가 문장을 넣으면 AI가 다듬어서 돌려주는 페이지 만들어줘"라고 시켰다. 몇 분 만에 /api/generate 엔드포인트가 생겼다. 이 엔드포인트는 안에서 내 OpenAI 키로 GPT를 호출하고, 결과를 사용자에게 돌려준다. 잘 동작한다. 트위터에 링크를 올렸다.
문제는 이 엔드포인트가 인터넷에 그대로 열려 있고, 아무 제한이 없다는 데 있다. 누군가 개발자 도구로 요청 한 번을 캡처하면, 그걸 그대로 반복하는 스크립트를 짜는 데 5분이면 충분하다. 그 스크립트가 초당 수십 번씩 /api/generate를 두드리면, 그 뒤에서는 내 키로 유료 API 호출이 초당 수십 번씩 일어난다. 월말에 도착하는 건 자랑스러운 트래픽 그래프가 아니라 네 자리, 다섯 자리 청구서다.
여기서 빠져 있는 한 가지가 레이트 리밋(rate limit), 우리말로 요청 속도 제한이다. 한 줄로 요약하면 이렇다. "한 명이 정해진 시간 안에 보낼 수 있는 요청 수에 상한을 두고, 그걸 넘으면 거절한다." 이번 글은 이 개념이 왜 보안이자 동시에 비용 문제인지, 그리고 바이브 코딩으로 만든 앱 어디에 어떻게 거는지를 다룬다.
놀이기구 앞 직원이 하는 일
인기 있는 놀이기구 앞에는 줄을 통제하는 직원이 있다. 이 사람이 하는 일은 단순하다. 한 번에 탈 수 있는 인원을 세고, 정원이 차면 다음 회차까지 손을 들어 막는다. 기구 자체의 안전을 위해서이기도 하고, 한 무리가 새치기로 몰려들어 뒷사람 차례를 다 잡아먹지 못하게 하기 위해서이기도 하다.
레이트 리밋이 딱 이 직원 역할이다. 서버 앞에 서서 "이 사람은 방금 1분 사이에 벌써 60번 요청했으니, 이번엔 잠깐 기다리라고 돌려보내자"를 판단한다. 놀이기구를 완전히 잠그는 게 아니다. 정상 속도로 오는 사람은 다 태우되, 비정상적으로 빠르게 밀려드는 요청만 골라 잠시 세워두는 것이다.
이 직원이 없으면 어떤 일이 벌어지는지는 이미 봤다. 스크립트 하나가 줄 전체를 점거하고, 정작 진짜 사용자는 서비스가 느려지거나 멈춘 화면을 보게 된다. 그리고 그 뒤에서 요금이 쌓인다.
왜 필요한가: 요금, 보안, 그리고 남는 자리
레이트 리밋이 막아주는 문제는 크게 세 갈래다.
첫째는 앞에서 본 요금이다. 내 서버가 그냥 텍스트를 돌려주는 정도라면 트래픽이 몰려도 서버 비용이 조금 오르는 선에서 끝난다. 그런데 요청 하나하나가 유료 LLM 호출로 이어진다면 이야기가 완전히 달라진다. 요청 수가 곧 돈이다. 인증도 제한도 없는 LLM 엔드포인트는 사실상 내 결제 카드번호를 인터넷에 적어두는 것과 다르지 않다.
둘째는 보안이다. 로그인이나 비밀번호 재설정 같은 엔드포인트를 생각해보자. 공격자는 "admin / password123" 같은 조합을 수십만 개씩 순서대로 넣어보며 뚫릴 때까지 시도한다. 이걸 무차별 대입(brute-force)이라고 한다. 비밀번호를 아무리 복잡하게 걸어둬도, 시도 횟수에 제한이 없으면 컴퓨터는 그냥 계속 두드린다. "한 IP에서 5분에 로그인 10번까지"라는 제한 하나가 이 공격의 성립 자체를 막는다.
셋째는 자리 뺏김이다. 봇이 내 데이터를 통째로 긁어가려고(scraping) 초당 수백 번씩 API를 훑거나, 그냥 서버를 마비시키려는 대량 요청(DDoS)이 들어오면, 서버 자원이 그쪽으로 쏠린다. 그 사이 진짜 사용자의 요청은 뒤로 밀리고 응답이 느려진다. 레이트 리밋은 한 명이 자원을 독점하지 못하게 막아서, 나머지 모두의 서비스 품질을 지켜준다.
거절도 예의 있게: 429와 Retry-After
제한을 넘긴 요청을 서버가 그냥 무시하고 연결을 끊으면, 정상 사용자가 실수로 걸렸을 때 무슨 일이 일어난 건지 알 수가 없다. 그래서 웹에는 이 상황을 위한 표준 응답이 정해져 있다. HTTP 상태 코드 429 Too Many Requests다. "당신 요청이 너무 많아서 지금은 안 받는다"는 뜻을 기계가 알아들을 수 있는 형태로 돌려주는 것이다.
여기에 Retry-After라는 헤더를 함께 붙이면 더 친절해진다. 이 헤더는 "몇 초 뒤에 다시 오면 받아주겠다"를 숫자로 알려준다. 예의 바르게 만든 클라이언트나 라이브러리는 이 값을 읽고 그 시간만큼 기다렸다가 자동으로 재시도한다. 참고로 우리가 Claude API나 OpenAI를 호출할 때 가끔 만나는 429가 바로 이것이다. 이번엔 반대로, 내가 남에게 429를 돌려주는 쪽이 되는 셈이다.
// 제한을 넘긴 요청에 돌려주는 응답
res.status(429)
.set('Retry-After', '60')
.json({ error: '요청이 너무 많습니다. 잠시 후 다시 시도하세요.' })
무엇을 기준으로 셀 것인가
"한 명"을 어떻게 정의하느냐가 생각보다 중요하다. 기준을 잘못 잡으면 제한이 헐겁거나, 엉뚱한 사람을 막는다.
가장 흔한 건 IP 주소 기준이다. 로그인이 필요 없는 공개 엔드포인트에서는 이것 말고 딱히 셀 것이 없다. 구현이 간단하다는 장점도 있다. 다만 허점이 있다. 회사나 학교, 카페처럼 여러 사람이 같은 공인 IP를 공유하는 경우, 그 안의 한 명이 제한에 걸리면 나머지도 같이 막힌다. 반대로 공격자는 IP를 수시로 바꿔가며(프록시나 봇넷을 써서) 제한을 피하기도 한다.
로그인이 있는 서비스라면 사용자 계정 기준이 더 정확하다. IP가 바뀌어도 같은 계정이면 같은 통에 담아 센다. 공개 API를 제공한다면 API 키 기준으로 세고, 요금제에 따라 상한을 다르게 두기도 한다. 무료 키는 분당 60번, 유료 키는 분당 1000번 하는 식이다.
실전에서는 이걸 섞어 쓴다. 로그인 엔드포인트는 IP로 막고(계정이 없는 상태니까), LLM 호출 엔드포인트는 로그인한 사용자 계정으로 막는 식이다. 그리고 비싼 엔드포인트일수록 상한을 낮게 잡는다. 단순 조회는 넉넉하게, GPT를 호출하는 요청은 빡빡하게.
어떻게 세는가: 통에 담는 네 가지 방식
세부 구현은 라이브러리가 알아서 해주니 수학까지 알 필요는 없다. 다만 방식마다 성격이 달라서, 이름과 감만 잡아두면 도구를 고를 때 도움이 된다.
가장 단순한 건 고정 창(fixed window)이다. "매 1분마다 100번까지"처럼 시간을 딱딱 끊어 세고, 다음 분이 되면 카운터를 0으로 리셋한다. 만들기 쉽지만 경계에서 구멍이 생긴다. 0시 59초에 100번, 1시 00초에 또 100번을 몰아치면, 실제로는 2초 사이에 200번이 통과한다.
이 구멍을 메운 게 슬라이딩 창(sliding window)이다. "지금 이 순간부터 직전 60초"를 계속 움직이며 센다. 창이 시계처럼 끊기지 않고 미끄러지듯 따라오니, 경계에서 몰아치는 꼼수가 통하지 않는다. 대신 계산이 조금 더 복잡해서 보통 Redis 같은 저장소의 도움을 받는다.
토큰 버킷(token bucket)은 통에 토큰을 일정 속도로 채워 넣는 방식이다. 초당 10개씩 토큰이 떨어지고, 요청 하나가 토큰 하나를 쓴다. 통이 비면 거절한다. 핵심은 통에 담아둘 수 있는 최대치가 있다는 점이다. 한동안 요청이 뜸했다면 토큰이 통에 쌓여 있으니, 갑자기 몰리는 정상적인 순간 트래픽(버스트)은 너그럽게 받아준다. 평소 속도는 제한하되 잠깐의 몰림은 허용하는, 균형 잡힌 방식이라 널리 쓰인다.
새는 물통(leaky bucket)은 반대로 통에서 물이 일정 속도로만 빠져나가게 한다. 요청이 아무리 몰려도 처리는 정해진 속도로만 흘러나가고, 통이 넘치면 버려진다. 트래픽을 고르게 다듬는 데 쓴다. 넷 중에 뭘 고를지 고민할 필요는 거의 없다. 대부분의 라이브러리와 서비스가 합리적인 기본값을 정해두고 있고, 초보 단계에서는 그걸 그대로 쓰면 된다.
어느 층에 걸 것인가
레이트 리밋은 요청이 지나가는 길목 어디에나 걸 수 있다. 크게 세 층으로 나뉜다.
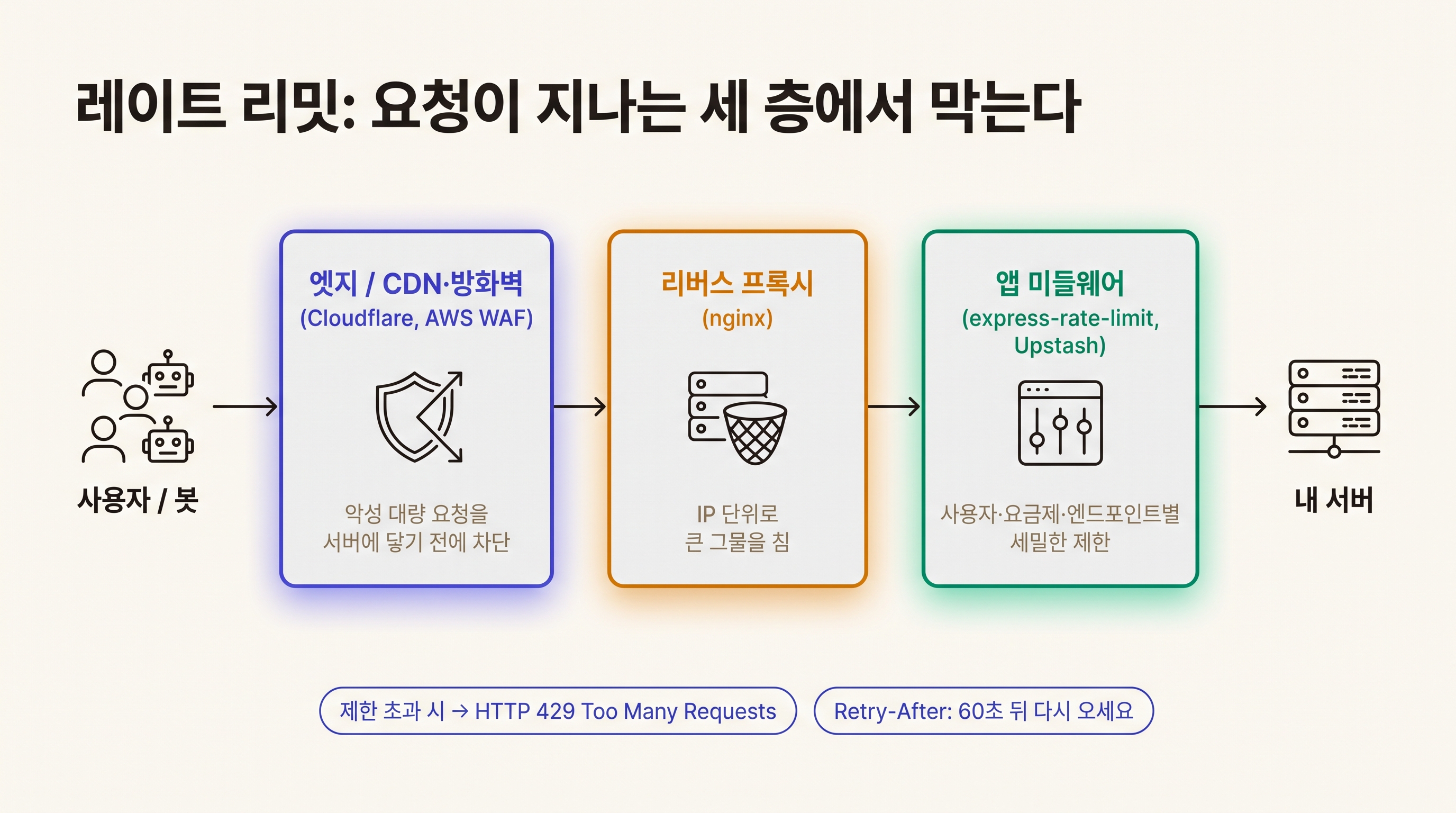
가장 바깥은 엣지, 즉 CDN이나 방화벽 층이다. Cloudflare의 레이트 리밋 규칙이 대표적이다. "이 경로에 같은 IP가 1분에 10번 넘게 오면 차단하거나 자동 인증(challenge)을 띄워라" 같은 규칙을 대시보드에서 몇 번의 클릭으로 만든다. 이 층의 최대 장점은 악성 트래픽을 내 서버에 닿기도 전에 걸러준다는 것이다. 대량 요청 공격은 애초에 내 서버까지 오지 않는 게 최선이라, 이 층에서 막는 게 가장 효율적이다. AWS를 쓴다면 AWS WAF가 같은 역할을 한다.
가운데는 리버스 프록시나 웹 서버 층이다. nginx 같은 서버에서 "어떤 IP든 이 경로는 초당 50번까지"처럼 큰 그물을 쳐둔다. 여러 앱 앞에 공통으로 두기 좋고 빠르다.
가장 안쪽은 앱 코드, 즉 미들웨어 층이다. 바이브 코더가 실제로 가장 많이 손대게 될 곳이다. 이 층은 서버가 사용자 정보를 다 알고 있어서 "누구인지", "어떤 요금제인지", "어떤 엔드포인트인지"를 따져 세밀하게 제한할 수 있다. LLM 엔드포인트만 콕 집어 빡빡하게 거는 것도 여기서 한다.
Node.js와 Express로 만들었다면 express-rate-limit이 가장 손쉽다.
import rateLimit from 'express-rate-limit'
// LLM 호출 엔드포인트: 로그인 사용자당 1시간에 100번까지
const aiLimiter = rateLimit({
windowMs: 60 * 60 * 1000, // 1시간
limit: 100,
standardHeaders: true, // 429 + RateLimit 헤더 자동 처리
keyGenerator: (req) => req.user?.id ?? req.ip, // 로그인이면 계정, 아니면 IP
})
app.post('/api/generate', aiLimiter, generateHandler)
한 가지 함정이 있다. 이런 라이브러리는 기본적으로 카운터를 서버 메모리에 저장한다. 서버가 한 대일 때는 괜찮지만, Vercel이나 Cloudflare Workers처럼 요청마다 여러 곳에서 코드가 실행되는 환경에서는 각 인스턴스가 따로 세기 때문에 제한이 헐거워진다. 이럴 때는 Upstash의 @upstash/ratelimit처럼 카운터를 Redis에 모아두는 도구를 쓴다. 서버가 몇 대로 흩어져 돌든 한 곳에서 숫자를 세니 제한이 정확하게 걸린다.
정리
레이트 리밋은 거창한 보안 기술이 아니라, 서버 앞에 세워두는 줄 통제 직원이다. 한 명이 정해진 속도보다 빠르게 밀려들면 "잠깐 기다리라"며 429로 돌려보내는 것, 그게 전부다. 그런데 이 직원 하나가 세 가지를 동시에 지킨다. 유료 API로 새어나갈 요금을 막고, 로그인 무차별 대입을 무력화하고, 한 사람이 자원을 독점해 나머지가 느려지는 일을 방지한다.
바이브 코딩으로 앱을 배포할 때 순서는 분명하다. 먼저 Cloudflare나 Vercel이 제공하는 기본 보호를 켜서 큰 그물을 친다. 그다음 내 코드에서 특히 위험한 두 종류의 엔드포인트, 즉 유료 LLM을 호출하는 곳과 로그인처럼 인증을 다루는 곳에 사용자 기준 제한을 따로 건다. 인터넷에 공개된 엔드포인트가 내 카드로 결제를 대신 해준다는 사실을 잊지 않는 것, 거기서부터 시작하면 된다.