품질, 속도, 조직: 한 주에 세 축이 동시에 움직였다
2월 12일, OpenAI가 코딩 전용 모델 Codex-Spark를 내놓았다. 닷새 뒤인 17일, Anthropic이 Claude Sonnet 4.6을 공개했다. 같은 날 Amazon이 내부 개발자 80%에게 AI 코딩 도구를 주 1회 이상 쓰라는 방침을 세웠다는 보도가 나왔다.
일주일 사이에 대형 뉴스 세 건. 우연이 아니다.
2025년 Stack Overflow 조사에서 개발자 84%가 AI 코딩 도구를 쓰고 있거나 쓸 계획이라 답했다. 올해 초 그 수치가 92%로 뛰었다. "한번 써볼까?" 단계가 끝나고 "안 쓰면 뒤처진다" 단계에 접어든 셈이다. Anthropic은 20억 달러 이상 투자를 유치했고, OpenAI는 Cerebras와 100억 달러 규모 파트너십을 맺었다. 돈이 들어왔으니 제품이 쏟아진다. 같은 주에 뉴스가 겹친 건 필연에 가깝다.
세 사건은 각각 다른 축을 공략한다. Anthropic은 품질, OpenAI는 속도, Amazon은 조직 문화. 그런데 세 축이 가리키는 곳은 같다. AI 코딩 도구가 개발자의 취향에서 기업의 인프라로 넘어가는 분기점이다.
5배 싸고 거의 같은 성능: Sonnet 4.6이 깨뜨린 공식
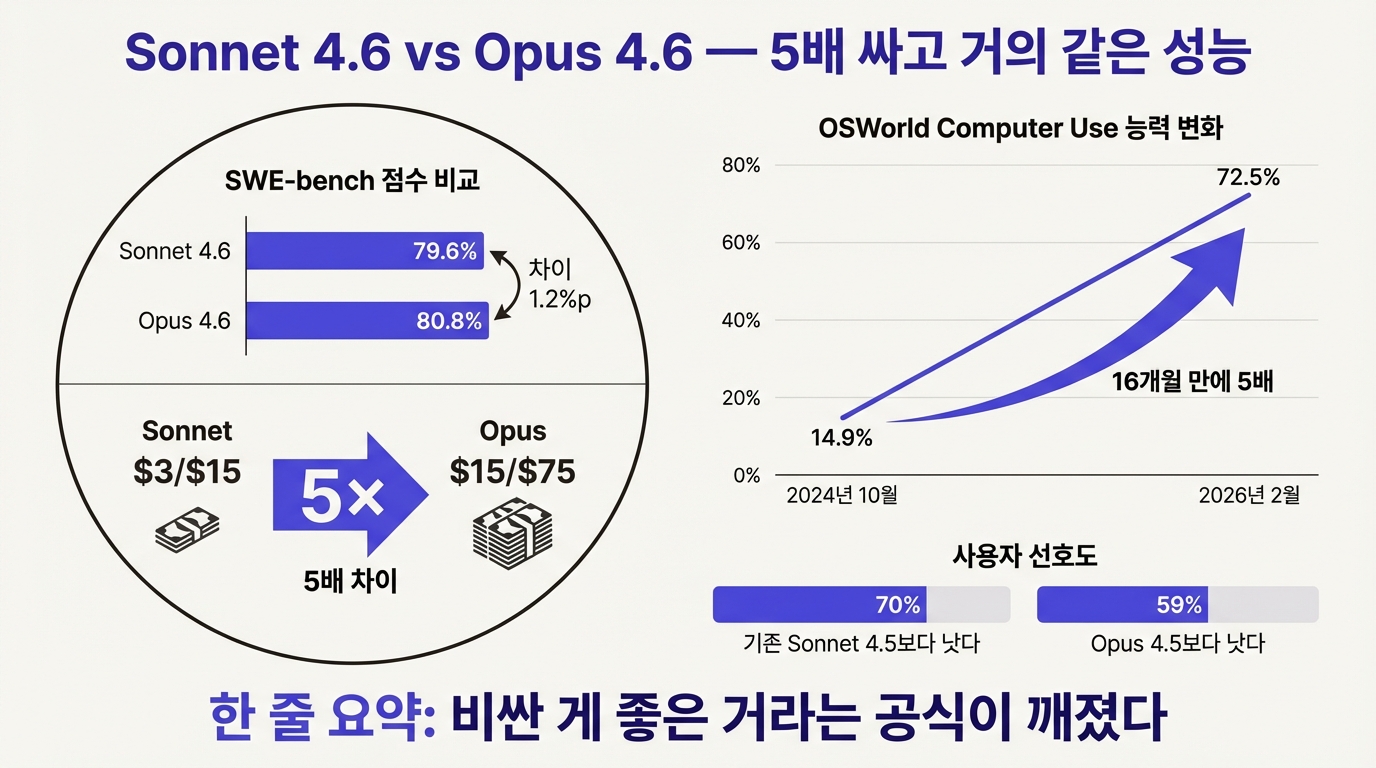
작년까지 AI 모델 세계에는 단순한 공식이 있었다. 비싸면 좋다. Anthropic의 최상위 모델 Opus는 입력 100만 토큰당 15달러, 출력은 75달러. 하위 모델 Sonnet은 3달러와 15달러. 가격이 5배 차이 나니 성능도 확연히 갈렸다.
Sonnet 4.6이 이 공식을 부쉈다.
소프트웨어 엔지니어링 벤치마크(SWE-bench Verified)에서 Sonnet 4.6은 79.6%를 찍었다. Opus 4.6은 80.8%. 격차가 1.2%포인트. 가격은 여전히 5분의 1이다. 엔터프라이즈 의사결정자 입장에서 보자. "5배 더 내시면 1.2%포인트 더 좋습니다"라는 제안서에 사인할 사람이 몇이나 될까.
컴퓨터 사용(Computer Use) 능력의 변화폭은 더 크다. 2024년 10월 첫 공개 때 OSWorld 벤치마크 14.9%였던 점수가 16개월 만에 72.5%로 올랐다. 거의 5배. AI가 화면을 보고 마우스를 움직이고 프로그램을 조작하는 능력이 이 속도로 개선되고 있다는 뜻이다.
컨텍스트 윈도우도 달라졌다. 100만 토큰을 정식으로 지원한다. 한국어 원고지로 치면 약 1만 장 분량이다. 여기에 Context Compaction이라는 기능이 붙었다. 대화가 길어져서 컨텍스트가 꽉 차면 서버가 핵심만 추려서 자동 압축한다. 긴 코딩 세션에서 대화가 쌓여 모델이 앞의 내용을 잊어버리던 문제가 구조적으로 풀린 것이다.
사용자 선호도 조사 결과도 주목할 만하다. 70%가 기존 Sonnet 4.5보다 나아졌다고 답했고, 59%는 Opus 4.5보다 낫다고 했다. 하위 모델이 상위 모델을 이기는 상황. "비싼 게 좋은 거"라는 상식이 깨지는 순간이다.
응답이 즉각적이면 경험 자체가 달라진다
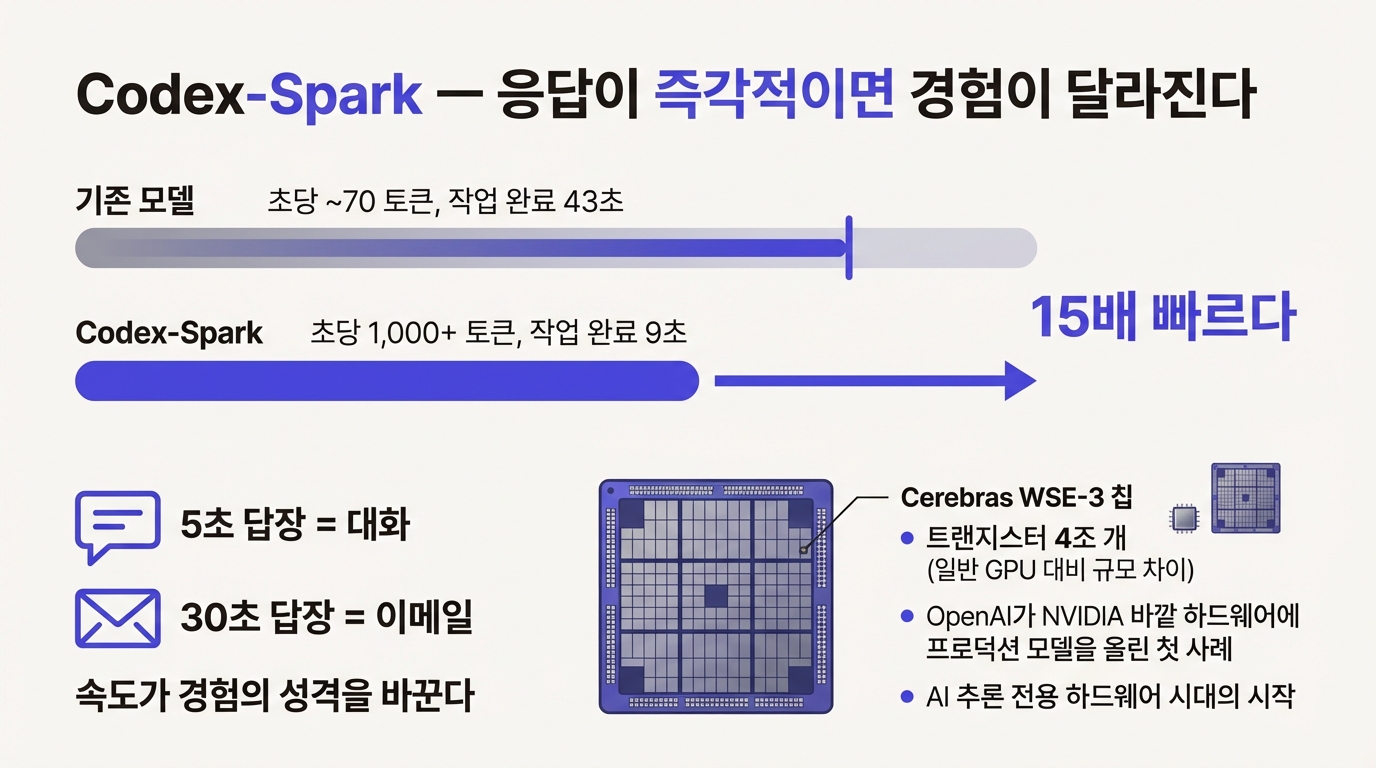
OpenAI의 Codex-Spark는 성능이 아니라 속도로 승부를 걸었다.
기존 AI 코딩 도구의 작업 흐름을 떠올려보자. 코드를 요청한다. 몇 초에서 수십 초를 기다린다. 결과를 확인하고 수정을 요청한다. 또 기다린다. 요청, 대기, 확인의 반복이다.
Codex-Spark는 초당 1,000토큰 이상을 생성한다. 일반 모델이 초당 70토큰 안팎이니 15배 빠르다. 체감으로 따지면 기존 모델이 43초 걸리던 작업을 9초에 끝낸다.
숫자만 보면 "좀 빨라졌네" 정도로 느낄 수 있다. 그런데 속도가 일정 수준을 넘으면 경험의 성격 자체가 바뀐다. 채팅 앱을 생각해보면 쉽다. 메시지를 보내고 5초 안에 답이 오면 대화다. 30초 후에 오면 이메일이다. 같은 텍스트인데 속도에 따라 쓰임새가 달라진다.
코딩도 마찬가지다. 응답이 즉각적으로 나오면 "AI에게 코드 생성을 부탁하는" 행위가 "AI와 나란히 코드를 짜는" 행위로 바뀐다. 대기 시간이 사라지면 생각의 흐름이 끊기지 않는다. 페어 프로그래밍에서 옆자리 동료에게 말 걸듯 주고받을 수 있게 되는 것이다.
이 속도를 가능하게 한 건 NVIDIA GPU가 아니다. Cerebras의 WSE-3라는 전용 칩이다. 트랜지스터 4조 개를 하나의 웨이퍼에 집적했다. 일반 GPU가 수백억 개 단위인 걸 감안하면 규모 자체가 다르다. OpenAI가 NVIDIA 바깥의 하드웨어에 프로덕션 모델을 올린 건 이번이 처음이다. AI 추론이 GPU만의 영역이 아닐 수 있다는 첫 신호에 해당한다.
쓸 사람이 안 쓰면? Amazon의 답
기술은 나왔다. 속도도 나왔다. 그런데 정작 쓸 사람이 안 쓰면 소용없다. Amazon이 이 문제에 답을 내놨다. 좀 강압적인 답이긴 하다.
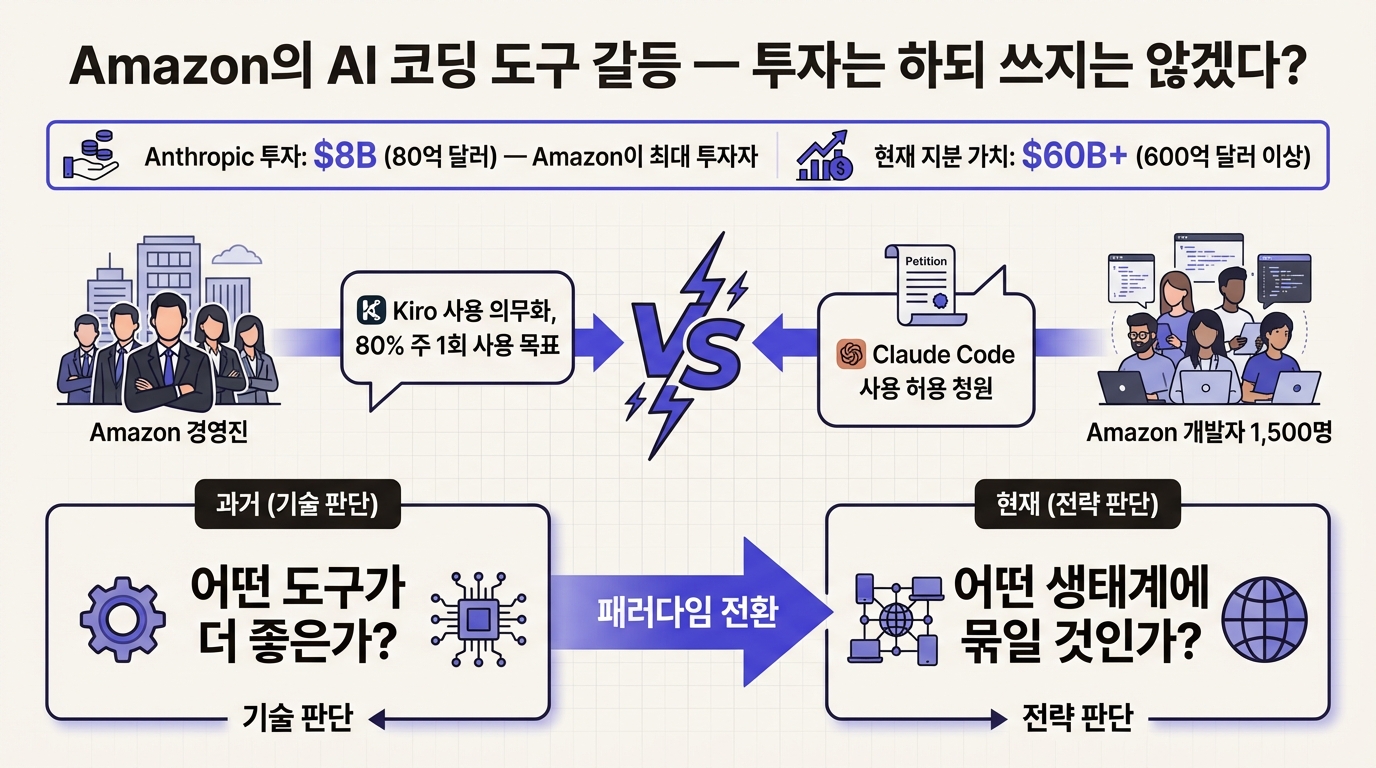
2월 17일 보도에 따르면 Amazon은 내부 개발자 80%가 AI 코딩 도구를 주 1회 이상 사용하는 것을 목표로 잡았다. 1월 기준으로 엔지니어 70%가 자사 도구 Kiro를 최소 한 번은 써봤다고 한다. "써본 사람 70%"를 "매주 쓰는 사람 80%"로 끌어올리겠다는 것이다.
도구 선택의 정치학이 흥미롭다. Amazon은 Anthropic에 총 80억 달러를 투자했다. 최대 외부 투자자다. 그 지분 가치가 현재 600억 달러 이상으로 추정된다. 투자 성적표로만 보면 대성공이다. 그런데 정작 자사 개발자에게는 Anthropic 제품인 Claude Code 사용을 제한하고 자체 도구 Kiro를 밀고 있다.
개발자들이 가만있을 리 없다. 1,500명이 넘는 엔지니어가 Claude Code 사용 허용을 요구하는 청원에 서명했다. "투자는 하되 쓰지는 않겠다"는 회사 방침에 대한 현장의 반발인 셈이다.
이 상황이 시사하는 바가 있다. AI 코딩 도구가 개인의 취향에서 조직의 인프라 정책으로 격상되면 도구 선택이 기술 판단이 아니라 전략 판단이 된다. "어떤 도구가 더 좋은가"보다 "어떤 생태계에 묶일 것인가", "외부 의존도를 얼마나 허용할 것인가"가 쟁점으로 떠오른다. 개발자가 원하는 도구와 회사가 정해주는 도구 사이의 간극에서 새로운 종류의 갈등이 시작된다.
세 사건이 그리는 지도
세 사건을 겹쳐보면 윤곽이 드러난다.
Sonnet 4.6이 보여준 "하위 모델이 상위 모델을 따라잡는" 흐름은 이번이 처음이 아니다. Anthropic의 매 세대마다 Sonnet과 Opus의 격차가 줄었고 이번에 사실상 수렴했다. 다른 회사들도 비슷한 궤적을 밟을 가능성이 높다. 최고 성능에 접근하는 비용이 계속 내려간다는 뜻이다.
Codex-Spark와 Cerebras의 조합은 NVIDIA GPU 중심 생태계에 균열을 낸 첫 실전 사례다. 추론 속도에서 전용 칩이 GPU를 압도한다는 게 확인되면 AI 추론 전용 하드웨어 시장이 본격적으로 열린다.
Amazon은 시작에 불과하다. AI 코딩 도구가 기업 인프라로 자리 잡으면 선택권이 IT 부서와 경영진으로 넘어간다. "무엇을 쓸 것인가"에 더해 "누가 결정할 것인가"가 쟁점으로 떠오른다.
열린 질문도 있다. Codex-Spark의 정식 가격이 나오면 속도 대 비용 계산이 어떻게 달라질까. Amazon 말고 다른 대기업도 AI 코딩 사용을 의무화할까. 그리고 가장 불편한 질문. AI가 생성한 코드의 품질은 충분히 검증되고 있는가.
이 마지막 질문에 관해 데이터가 좀 불편하다. 2026년 기준 전체 코드의 41%가 AI 생성으로 추정된다. 그런데 개발자 46%가 AI 출력을 적극적으로 불신하고 신뢰한다는 응답은 33%에 그친다. 더 주목할 만한 연구가 있다. 경험 많은 개발자가 "AI 덕분에 20% 빨라졌다"고 체감했지만 실제 측정에서는 오히려 19% 느려진 사례가 보고됐다. 체감과 실제의 괴리. 도구가 좋아지는 속도만큼 이 괴리를 검증하는 장치가 필요하다.
이번 주 세 사건에서 끌어낼 수 있는 실질적 판단 기준
앞서 다룬 세 사건은 각각 다른 결정을 내려야 하는 사람에게 서로 다른 신호를 보낸다.
가성비 모델을 자주 쓰는 편이 최상위 모델을 아끼는 것보다 낫다. Sonnet 4.6과 Opus 4.6의 SWE-bench 격차가 1.2%포인트로 좁혀진 상황에서, 엔터프라이즈가 취할 수 있는 가장 합리적인 전략은 최상위 모델 호출을 줄이고 가성비 모델의 호출 빈도를 높이는 쪽이다. 5분의 1 비용으로 거의 같은 결과를 얻는다면 아낀 예산으로 호출 횟수를 늘릴 수 있다. 코드 리뷰 한 번에 Opus를 쓰는 대신 Sonnet으로 세 번 돌리는 게 결함 검출률을 올릴 가능성이 높다. "최고 모델을 쓴다"가 아니라 "적정 모델을 충분히 쓴다"가 비용 효율의 핵심이 되는 국면이다.
"요청하고 기다리는" 식의 프롬프트 작성법은 유통기한이 짧다. Codex-Spark 수준의 응답 속도가 보편화되면 AI와의 상호작용 패턴이 근본적으로 달라진다. 지금은 요청을 잘 정리해서 한 번에 보내는 게 효율적이다. 대기 시간이 길기 때문이다. 그런데 응답이 즉각적으로 돌아오는 환경에서는 오히려 잘게 쪼개서 반복적으로 주고받는 게 유리해진다. 지금 정성 들여 익히고 있는 "한 방에 완벽한 프롬프트" 기법이 6개월 뒤에는 비효율의 상징이 될 수 있다. 프롬프트 엔지니어링보다 대화 설계가 중요해지는 전환점이 가까워지고 있다.
"내가 원하는 도구"를 쓰려면 조직 안에서 설득해야 하는 시대가 왔다. Amazon 사례가 보여주듯 도구 선택권이 개인에서 조직으로 넘어가고 있다. 1,500명이 서명한 청원서가 나올 정도로 개발자와 경영진의 도구 선호가 갈라지는 상황이 이미 벌어졌다. 앞으로 "이 도구가 좋다"는 개인 경험만으로는 부족하다. 보안 정책, 벤더 종속 리스크, 라이선스 비용 구조까지 포함한 제안서를 만들어 IT 부서와 경영진을 설득할 수 있어야 자기가 원하는 환경에서 일할 수 있게 된다. 기술 역량과 별개로 조직 내 의사결정 과정에 참여하는 능력이 개발자에게도 필요해졌다.