하니스라는 OS를 열어보면
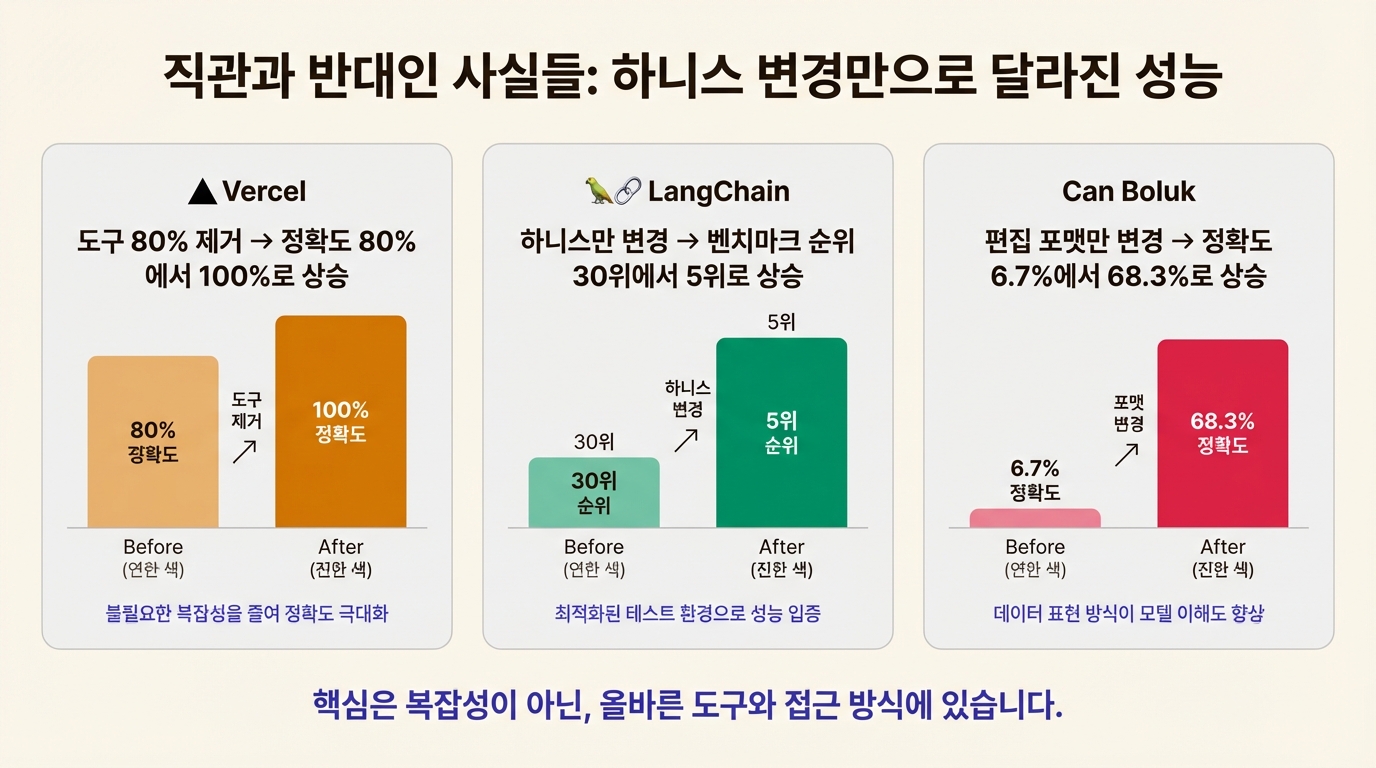
Phil Schmid가 하니스를 운영체제에 비유한 건 꽤 정확했다. CPU가 아무리 빨라도 OS가 엉망이면 컴퓨터가 제대로 돌아가지 않듯, 모델이 아무리 뛰어나도 하니스가 부실하면 에이전트는 헛돈다. Can Boluk의 실험에서 같은 모델의 정확도가 6.7%에서 68.3%로 뛴 것도, 결국 OS를 교체한 셈이었다.
그런데 "OS가 중요하다"는 말만으로는 안이 보이지 않는다. 윈도우나 리눅스를 처음 쓰는 사람에게 OS의 중요성을 아무리 강조해도, 구체적으로 뭘 어떻게 해야 하는지는 여전히 모른다. 하니스도 마찬가지다. 1편에서 "하니스가 중요하다"는 충분히 다뤘으니, 이제 남은 질문은 하니스 안에 뭐가 들어 있느냐다.
하니스를 열어보면 네 가지 영역이 보인다. 아키텍처 제약, 피드백 루프, 워크플로우 제어, 개선 사이클. SmartScope가 정리한 계층도(프롬프트 엔지니어링 ⊂ 컨텍스트 엔지니어링 ⊂ 하니스 엔지니어링)에서 하니스만의 고유 영역을 구성하는 요소들이다. 컨텍스트 엔지니어링이 "모델에게 뭘 보여줄지"를 설계하는 것이라면, 이 네 영역은 그 너머를 다룬다. 모델이 보고 나서 무엇을 하게 할지, 어떻게 검증할지, 실패하면 어떻게 되돌릴지.
하나씩 뜯어본다.
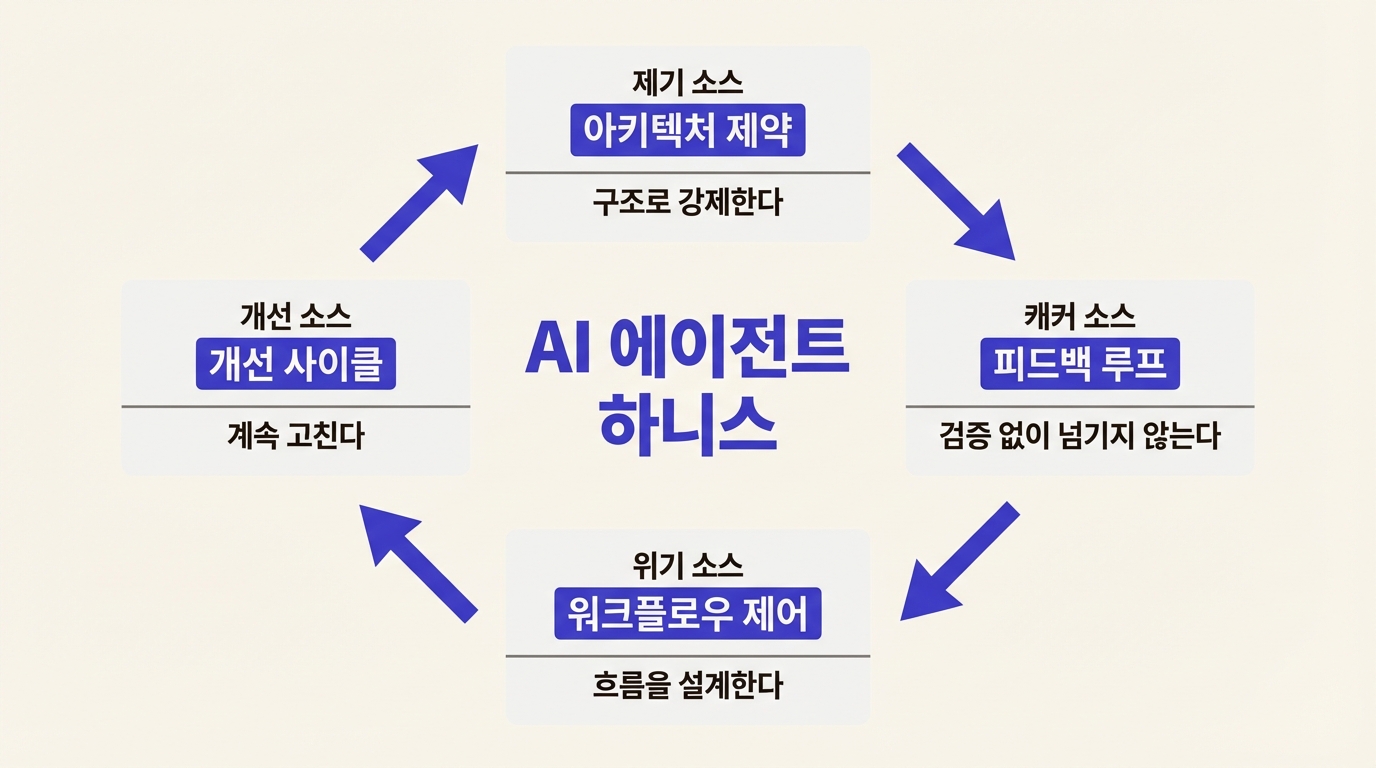
1. 부탁이 아니라 구조로 강제하는 아키텍처 제약
에이전트에게 "코드 레이어 순서를 지켜줘"라고 프롬프트로 부탁하는 것과, 순서를 어기면 시스템이 거부하는 것은 전혀 다른 접근이다. 전자는 에이전트의 "의지"에 기대는 것이고, 후자는 물리적으로 불가능하게 만드는 것이다.
린터가 "취향"까지 강제하는 이유
OpenAI Codex 팀이 설계한 레이어 아키텍처는 Types, Config, Repo, Service, Runtime, UI 순서로 코드 의존성 방향을 고정한다. "앞으로만" 의존할 수 있고, UI에서 Types를 직접 참조하는 역방향 의존은 구조적으로 차단된다. 여기까지는 소프트웨어 엔지니어링에서 익숙한 패턴이다.
흥미로운 건 그다음이다. OpenAI는 여기서 한 발 더 나아가 "taste invariants"라는 개념을 도입했다. 직역하면 "취향 불변량"이다. 코드 구조가 올바른지를 넘어서, 코딩 스타일이나 네이밍 컨벤션, 파일 크기 같은 "취향"의 영역까지 커스텀 린터로 기계적으로 검증한다는 뜻이다.
사람 개발자끼리도 코드 리뷰에서 이런 경험이 있을 것이다. "규칙 위반은 아닌데 읽기가 좀..." 하는 경우. OpenAI는 그 "읽기가 좀..."을 린터 규칙으로 만들어서 에이전트가 지키게 했다.
왜 이게 효과적인가. 에이전트는 사람과 달리 분위기를 읽지 못한다. 코드가 기술적으로 맞는지는 판단하지만, 팀의 코딩 스타일에 자연스럽게 녹아드는지는 모른다. 취향을 규칙으로 명시하고 기계적으로 강제하는 수밖에 없다.
편집 포맷 하나가 정확도를 10배 바꾼 원리
Can Boluk의 실험에서 정확도가 10배 뛴 이유를 기술적으로 들여다보면, 편집 포맷의 차이가 핵심이다. AI 코딩 에이전트가 코드를 수정하는 방식은 크게 세 가지로 나뉜다.
Patch 포맷(OpenAI 스타일 diff): 변경할 부분의 앞뒤 맥락을 지정하고, 빼야 할 줄과 넣어야 할 줄을 표시한다. 사람에게는 직관적이지만 모델에게는 까다롭다. Grok 4에서 이 포맷의 실패율이 50.7%에 달했다.
String Replace(Claude Code, Gemini 방식): 바꾸고 싶은 문자열을 정확히 재현한 뒤 새 문자열로 교체한다. 문제는 "정확히 재현"이라는 조건이다. 공백 하나, 들여쓰기 한 칸이 달라도 실패한다. 파일이 길어질수록 실패 확률이 올라간다.
Hashline(Can Boluk이 고안한 방식): 코드의 각 줄에 2~3자짜리 고유 해시 태그를 부여한다. 모델은 코드 내용을 통째로 재현할 필요 없이 해시 ID로 "이 줄을 이걸로 바꿔"라고 지시하면 된다. 출력 토큰이 61% 줄었고, 코드 내용을 외울 필요가 없어지면서 정확도가 급등했다. 400줄 이하 파일에서는 전체 재작성이 diff 방식보다 우수하다는 점을 Cursor 팀도 인정했다.
세 포맷의 차이가 보여주는 건 이것이다. 모델의 능력을 바꾼 게 아니라, 모델이 실수할 수 있는 구간을 줄였다. 코드 내용을 정확히 기억해야 하는 부담을 해시 참조로 대체해서 실수 가능 범위를 좁힌 것이다.
도구를 빼니까 정확도가 올랐다
직관에 반하는 사례가 하나 있다. Vercel 팀은 AI 에이전트에게 제공하는 도구의 80%를 제거했더니, 작업 정확도가 80%에서 100%로 올라갔다.
이유는 단순하다. 선택지가 많으면 잘못된 선택을 할 확률도 높아진다. 파일 읽기, 쓰기, 검색, 실행, 테스트, 배포까지 20가지 도구를 한꺼번에 쥐어주면, 에이전트는 "어떤 도구를 써야 하지?"를 고민하느라 본래 작업에 집중하지 못한다. 꼭 필요한 도구만 남기면 행동 범위가 좁아지고, 좁아진 범위 안에서 정확도가 올라간다.
Stripe도 비슷한 원리를 적용했다. "Minions"라는 에이전트 시스템으로 주당 1,000건 이상의 PR을 처리하는데, 핵심 장치는 "Toolshed"라는 도구 관리 시스템이다. 400개가 넘는 내부 도구를 여기서 관리하면서, 각 에이전트가 접근할 수 있는 도구를 작업 유형에 따라 제한한다. 400개 도구를 전부 쓸 수 있는 에이전트는 하나도 없다. 이 제한이 오히려 정확도를 높인다.
아키텍처 제약의 핵심 원리는 결국 이것이다. 제약은 에이전트를 약하게 만드는 게 아니라, 실수 가능 범위를 좁혀서 강하게 만든다.
2. 모델 출력을 검증 없이 넘기지 않는 피드백 루프
에이전트가 "완료했습니다"라고 보고한다. 정말 끝난 걸까. 높은 확률로, 아니다. 피드백 루프는 에이전트의 출력을 검증하고, 문제가 있으면 신호를 돌려보내 스스로 수정하게 만드는 순환 구조다. 이 장치가 없으면 에이전트는 자신감 있게 틀린 결과를 내놓는다.
하니스만 바꿔서 30위에서 5위로
LangChain 팀이 Terminal Bench 2.0이라는 벤치마크에서 흥미로운 실험을 했다. 89개 코딩 과제(ML, 디버깅, 생물학 시뮬레이션)에 gpt-5.2-codex라는 동일 모델을 고정해놓고 하니스만 바꿔봤다.
결과: 52.8%에서 66.5%로 13.7포인트 상승. 벤치마크 순위로는 30위에서 5위. 모델은 한 글자도 안 바꿨다.
어떤 하니스를 추가했을까. 핵심 기법은 두 가지다.
첫째, PreCompletionChecklistMiddleware. 에이전트가 "끝났다"고 선언하기 직전에 끼어드는 장치다. "정말 끝났어? 테스트는 돌렸어? 빌드는 되어?" 같은 체크리스트를 강제로 통과시킨다. 사람으로 치면 보고서 제출 전 필수 항목을 확인하는 것과 비슷하다. 단순하지만 효과가 크다. 에이전트에게는 "거의 됐으니까 일단 제출하자"는 경향이 있기 때문이다.
둘째, LoopDetectionMiddleware. 에이전트가 같은 파일을 N번 이상 수정하면 개입한다. "이 파일을 5번째 수정하고 있는데, 접근 방식을 바꿔보는 게 어때?"라고 제안한다. 같은 실수를 반복하며 빠지는 무한 루프(doom loop)를 방지하는 장치다.
여기에 Reasoning Sandwich라는 전략도 눈에 띈다. 에이전트의 작업을 세 단계로 나눠서, 계획 단계에는 높은 추론 강도를, 구현 단계에는 중간 강도를, 최종 검증 단계에는 다시 높은 강도를 적용한다. 모든 단계에 높은 추론 강도를 쓰면 53.9%인데, 이렇게 단계별로 배분하면 63.6%까지 올라간다. 검증이 중요한 곳에 자원을 집중한 셈이다.
"코드 0줄" 뒤에 숨은 7단계 검증 사이클
OpenAI Codex 팀이 5개월간 사람이 직접 쓴 코드 0줄로 100만 줄을 출하할 수 있었던 배경에는 E2E(End-to-End) 검증 사이클이 있다. 에이전트가 프롬프트 하나를 받으면 거치는 전체 흐름은 이렇다.
- 코드베이스 상태 검증
- 보고된 버그를 직접 재현(비디오 녹화 포함)
- 수정 구현
- 수정 결과를 앱을 직접 구동해서 확인
- PR(코드 변경 요청) 열기
- 리뷰 피드백에 대응
- 빌드 실패 감지 및 해결
사람이 판단해야 할 상황이 발생하면 그때만 에스컬레이션한다. 코드를 쓰는 것 자체보다 검증하고 피드백하는 과정이 훨씬 더 많은 비중을 차지하는 구조다.
AGENTS.md는 정적 문서가 아니다
Hashimoto가 고안한 AGENTS.md는 "에이전트가 따라야 할 규칙을 적어둔 문서"로 소개되는 경우가 많다. 하지만 진짜 힘은 피드백 루프에 있다.
작동 방식은 이렇다. 에이전트가 실수한다. 그 실수를 방지하는 규칙을 AGENTS.md에 추가한다. 다음번 에이전트가 작업을 시작할 때 이 규칙을 읽는다. 같은 실수를 반복하지 않는다. 시간이 갈수록 규칙이 쌓이고, 실수 빈도는 줄어든다.
정적 문서가 아니라 살아있는 피드백 루프인 셈이다. Google의 Addy Osmani도 같은 관찰을 했다. "에이전트가 실수하면 AGENTS.md에 노트를 추가한다. 이후 반복에서 같은 유형의 실수가 줄어든다." 문서 자체가 학습 장치가 된다. 모델의 가중치를 바꾸지 않아도, 모델이 읽는 규칙을 바꾸면 행동이 바뀐다.
피드백 루프의 핵심 원리는 결국 이것이다. 에이전트에게 검증 수단을 주면 대부분 스스로 실수를 고친다. 관건은 "어떤 검증 수단을 어디에 배치할 것인가"다.
3. 흐름 자체를 설계하는 워크플로우 제어
에이전트에게 "이 앱 만들어줘"라고 큰 목표를 던지면 어떻게 될까. 높은 확률로 초반에는 그럴듯하게 진행하다가 중반부터 품질이 떨어지고, 후반에는 앞에서 만든 코드와 충돌하면서 무한 수정 루프에 빠진다. 작업을 어떻게 쪼개고, 순서를 어떻게 정하고, 컨텍스트를 어떻게 관리할지를 사람이 설계해야 한다.
과제 하나, 커밋 하나, 그리고 리셋
Addy Osmani가 소개한 "Ralph Wiggum 기법"은 이름은 장난스럽지만 원리는 견고하다. 에이전트의 작업 흐름을 다음과 같이 구성한다. 구조화된 TODO 리스트에서 다음 과제를 하나 고른다. 그 과제만 구현한다. 테스트로 검증한다. 통과하면 커밋한다. 과제 상태를 업데이트하고 학습 내용을 기록한다. 컨텍스트를 리셋하고 처음으로 돌아간다.
핵심은 마지막 단계의 "컨텍스트 리셋"이다. AI 모델에게는 컨텍스트 윈도우라는 작업 기억 공간이 있는데, 이 공간에는 한계가 있다. 한 세션에서 큰 기능을 통째로 만들려고 하면, 앞쪽에서 논의한 내용이 뒤쪽에서 밀려나면서 에이전트가 자기가 앞에서 뭘 했는지 잊어버린다. 이걸 "컨텍스트 오버플로"라고 부른다. 사람으로 치면 회의가 8시간째 이어지면서 앞부분에서 합의한 내용을 아무도 기억하지 못하는 상황과 비슷하다.
Ralph Wiggum 기법은 그 회의를 30분 단위로 끊는 전략이다. 과제 하나를 끝낼 때마다 컨텍스트를 깨끗이 비우고 다시 시작한다. 대신 커밋된 코드와 TODO 리스트가 "회의록" 역할을 하면서 연속성을 보장한다.
컨텍스트를 다루는 세 가지 원칙
Manus(AI 에이전트 스타트업)는 컨텍스트 관리를 세 원칙으로 정리했다.
Reduce(줄이기): 컨텍스트 윈도우에 들어가는 정보를 공격적으로 압축하고, 불필요한 부분을 잘라낸다. 에이전트가 코드 전체를 볼 필요 없이, 지금 작업에 관련된 부분만 보게 한다.
Offload(옮기기): 윈도우 안에 다 넣을 수 없는 정보는 파일시스템 같은 외부 저장소로 옮긴다. 필요할 때만 꺼내 본다. 모든 걸 머리에 담지 않고 메모장에 적어두는 것과 같다.
Isolate(격리하기): 무거운 하위 작업은 별도의 서브 에이전트에게 위임하고, 메인 에이전트는 결과 요약만 받는다. 과장이 팀원에게 세부 업무를 맡기고 보고서만 받아보는 구조다.
세 원칙의 공통점은 하나다. 에이전트의 컨텍스트 윈도우를 "쓸 수 있는 만큼만 쓴다." 정보를 더 넣는 게 능사가 아니라, 적절한 양을 유지하는 게 관건이다.
복잡한 파이프라인이라는 함정
Phil Schmid가 강조하는 원칙이 있다. "단순하게 시작하라." 에이전트에게 복잡한 파이프라인을 짜주고 싶은 유혹이 있지만, 그보다는 원자적 도구(하나의 일만 하는 작은 도구)를 제공하고 모델이 직접 계획하게 두는 편이 낫다.
이 원칙의 연장선에 "Build to Delete(삭제하기 위해 만든다)"라는 개념이 있다. 하니스를 만들 때부터 언젠가 버릴 것을 전제로 모듈화한다는 뜻이다. 이유는 간단하다. 3개월 뒤에 더 나은 모델이 나오면 하니스의 일부가 불필요해진다. 6개월 뒤에는 더 많은 부분이 불필요해진다. 처음부터 교체가 쉽도록 느슨하게 결합된 구조로 만들어야 한다.
Schmid의 통찰 중 가장 날카로운 건 이것이다. "모델이 똑똑해질수록 하니스는 단순해져야 한다." 직관적으로는 모델이 발전하면 더 정교한 하니스가 필요할 것 같지만 현실은 반대다. 모델이 똑똑해지면 이전에 하니스가 대신해주던 역할을 모델 스스로 처리할 수 있게 된다. 그때 하니스가 여전히 복잡하면, 오히려 모델의 능력을 제약하는 족쇄가 된다.
4. 하니스 자체를 계속 고치는 개선 사이클
앞의 세 영역(제약, 피드백, 워크플로우)을 한 번 만들고 끝이면 좋겠지만 현실은 그렇지 않다. 모델이 바뀌고, 요구사항이 바뀌고, 에이전트가 새로운 유형의 실패를 만들어낸다. 마지막 영역은 하니스 자체를 지속적으로 개선하는 메타 루프다.
잔해물을 치우는 에이전트
Fowler와 Bockeler가 분류한 세 범주 중 "Garbage Collection"이 여기에 해당한다. 에이전트가 코드를 생성하면서 남기는 잔해물이 있다. 깨진 테스트, 일관성 없는 네이밍, 쓰이지 않는 코드, 문서와 코드의 불일치. 방치하면 시간이 갈수록 코드베이스의 엔트로피(무질서)가 증가한다.
해결책은 주기적으로 실행되는 GC 에이전트다. 코드베이스를 스캔하며 문서 불일치를 탐지하고, 아키텍처 제약 위반을 식별하고, 일관성을 자동으로 복구한다. Fowler의 표현을 빌리면, "에이전트가 어려워하는 것을 신호로 삼는다. 무엇이 빠져 있는지 파악하고, 도구든 가드레일이든 문서든 시스템에 피드백한다."
트레이스 없이는 "개선"이라고 부를 근거도 없다
Arize AI가 제시한 프레임워크는 개선 사이클을 데이터 기반으로 만든다. 핵심 원칙은 이것이다. "소프트웨어에서는 코드가 앱을 문서화하지만, AI에서는 트레이스가 문서화한다."
트레이스(trace)는 에이전트의 런타임 행동 기록이다. 어떤 순서로 도구를 호출했는지, 몇 번 루프를 돌았는지, 어디서 실패했는지가 전부 기록된다. 이 트레이스를 분석하면 하니스의 어느 부분을 고쳐야 하는지 경험적 근거가 생긴다. Arize의 표현이 정곡을 찌른다. "실제 트레이스에 대한 평가 없이는 변경이 개선이라고 주장할 경험적 근거가 없다."
하니스는 영구 인프라가 아니다
하니스 재구축 빈도를 보면 이 점이 분명해진다. LangChain은 연 3회 하니스를 근본적으로 재구축한다. Manus는 6개월에 5회. "한 번 잘 만들어놓으면 오래 쓸 수 있지 않을까?"라는 기대와는 거리가 멀다.
이유는 앞서 Schmid가 짚은 것과 같다. 모델이 빠르게 진화하기 때문이다. 3개월 전에 유효했던 하니스 설계가 새 모델에서는 오히려 방해가 될 수 있다. 이전 모델의 약점을 보완하려고 추가했던 가드레일이, 그 약점을 해소한 새 모델에서는 불필요한 제약이 되는 식이다. Phil Schmid의 "Build to Delete" 원칙이 중요한 이유가 여기에 있다.
네 영역이 맞물려 돌아가는 방식
네 영역은 따로 노는 게 아니다.
아키텍처 제약이 피드백 루프의 기준을 만든다. "이 레이어 순서를 어겼는가"가 검증 항목이 되는 식이다. 피드백 루프가 발견한 반복 실패 패턴이 워크플로우 제어를 조정한다. "이 유형의 작업은 한 번에 하지 말고 쪼개서 하자." 그리고 개선 사이클이 제약, 피드백, 워크플로우 전부를 주기적으로 갈아엎는다. 모델이 바뀌면 제약도, 검증 기준도, 작업 분해 방식도 함께 바뀌어야 하기 때문이다.
직관과 반대인 패턴도 눈에 띈다. 도구를 빼야 정확도가 오르고(Vercel), 에이전트가 끝났다고 할 때 안 끝난 거고(PreCompletionChecklist), 하니스를 자주 부수는 팀이 더 잘 만든다(LangChain, Manus). 이 패턴들이 가리키는 방향은 같다. 하니스는 한 번 설치하고 잊어버리는 인프라가 아니라, 계속 관찰하고 다듬고 때로는 갈아엎으며 가꾸는 대상이다.
지도를 펼쳤으니 이제 각 지역을 직접 걸어볼 차례다. 다음 편에서는 첫 번째 영역인 아키텍처 제약을 깊이 파고든다. OpenAI 린터 시스템의 구체적 구현, CNCF가 정리한 4필러(Golden Paths, Guardrails, Safety Nets, Manual Review), 그리고 Hashline 포맷의 기술적 설계를 상세히 다룬다.