볼링 레인의 범퍼
볼링장에서 어린 아이가 공을 던진다. 양쪽에 범퍼가 올라와 있다. 공이 어디로 튀든 거터에 빠지지 않고 핀까지 굴러간다. 아이의 팔 힘이 세져서가 아니다. 실수해도 괜찮은 환경이 만들어져 있을 뿐이다.
Mitchell Hashimoto가 에이전트와의 작업을 이렇게 묘사했다. "잘 범위가 잡힌 문제에 많은 가드레일을 치는 것. 볼링 레인의 범퍼와 같다." 에이전트에게 "코드 품질을 높여줘"라고 부탁하는 건 범퍼 없이 스트라이크를 기대하는 것이다. 그 부탁을 아키텍처 제약이라는 범퍼로 바꾸면 어떤 일이 벌어지는지, 린터와 도구 제한과 편집 포맷이라는 세 방향에서 뜯어본다.
1. 린터가 아키텍트를 대신한다
한 방향으로만 흐르는 의존성
OpenAI Codex 팀의 코드베이스에는 레이어 순서가 고정되어 있다.
Types → Config → Repo → Service → Runtime → UI
각 비즈니스 도메인이 이 레이어 세트를 하나씩 갖는다. 의존성은 왼쪽에서 오른쪽으로만 흐른다. UI가 Repo를 직접 참조하거나 Service가 Runtime에 의존하는 역방향 엣지는 허용되지 않는다.
여기까지는 소프트웨어 아키텍처에서 흔한 원칙이다. 차이는 "어떻게 강제하느냐"에 있다. 보통은 아키텍처 문서에 "이 순서를 지켜주세요"라고 적어놓고, 코드 리뷰에서 사람이 확인한다. OpenAI는 이걸 커스텀 린터로 대체했다. 허용되지 않은 의존 엣지가 코드에 등장하면 린터가 빌드를 중단시킨다. 문서를 읽었든 안 읽었든 상관없다. 위반 자체가 물리적으로 불가능하다.
사람 개발자라면 아키텍처 문서를 안 읽어도 경험과 맥락으로 올바른 방향을 잡을 수 있다. 에이전트에게는 그런 암묵지가 없다. 문서를 컨텍스트로 넣어줘도 "참고"는 하지만 "준수"를 보장하지는 못한다. 린터가 그 간극을 메운다.
에러 메시지가 곧 수정 지침이 된다
이 린터에서 눈여겨볼 건 에러 메시지의 설계다. 보통 린터 에러는 "X 위반"으로 끝난다. OpenAI의 린터는 다르다. "이 의존성을 허용된 레이어로 옮기려면 X 리팩토링을 수행하라"는 구체적 지시가 에러 메시지에 담겨 있다.
에이전트는 린터 출력을 다음 행동의 입력으로 삼는다. 에러 메시지가 "뭘 어떻게 고쳐라"까지 알려주면, 에이전트가 추가로 추론할 필요가 없다. "이 에러가 뭘 뜻하지?"라고 해석하는 단계가 통째로 빠지는 셈이다. 반복 사이클이 줄고, 같은 위반을 두 번 범할 가능성도 낮아진다.
OpenAI의 Tony Lee가 정리한 Golden Principles 세 번째 원칙이 이걸 정확히 짚는다. "문서화가 아니라 기계적 강제가 일관성을 유지한다." 문서는 읽지 않을 수 있지만, 린터는 우회할 수 없다.
취향까지 검증하는 taste invariants
린터가 검증하는 건 아키텍처 규칙만이 아니다. OpenAI는 "taste invariants"라는 개념을 들고 나왔다. 코딩 스타일의 영역까지 기계적 검증 대상으로 확장한 것이다.
구체적으로 어떤 항목을 검증하는지 보면 이렇다.
| 카테고리 | 검증 항목 | 목적 |
|---|---|---|
| 코드 스타일 | 일관된 포맷팅, 구조화된 로깅 패턴, 스키마/타입 네이밍 컨벤션 | 유지보수성 확보 |
| 아키텍처 패턴 | 레이어 의존성 방향, 제한된 허용 엣지, 파일 크기 제한 | 코드 드리프트 방지 |
| 완료 기준 | 마일스톤별 즉시 검증, 조기 완료 금지, 결정 노트 기록 | 검증 없는 "완료" 차단 |
"조기 완료 금지"가 특히 눈에 띈다. 에이전트에게는 "거의 됐으니까 끝"이라고 선언하는 경향이 있다. 사람으로 치면 보고서의 마지막 1%를 대충 마무리하고 제출 버튼을 누르는 것과 비슷하다. taste invariants는 이걸 구조적으로 차단한다. 모든 마일스톤의 검증 항목이 통과되지 않으면 "완료" 상태로 전환할 수 없다. 위반하면 다음 마일스톤으로 넘어가는 것 자체가 막힌다(stop-and-fix).
린터가 린터를 만드는 복리 효과
이 린터 시스템에서 가장 흥미로운 건 자기강화 구조다. Codex가 린터 규칙 자체를 작성한다. 그 린터가 Codex의 다음 코드를 검증한다. 검증 과정에서 발견된 새로운 패턴이 린터 규칙으로 추가된다. 업데이트된 린터가 다시 Codex를 검증한다.
이 순환의 결과는 시간이 갈수록 쌓인다. 린터 규칙이 하나 늘 때마다 미래의 실패 가능성이 하나 줄어든다. 오늘 추가한 규칙이 내일의 실수를 막고, 내일 추가한 규칙이 모레의 실수를 막는다. Addy Osmani의 표현을 빌리면 "각 개선이 미래의 개선을 더 쉽게 만든다." 복리와 같은 원리다. 금융에서 복리가 시간이 갈수록 가속하듯, 린터 규칙도 초기에는 효과가 미미하지만 누적될수록 위력이 커진다.
검증 루프 전체는 네 단계로 돌아간다. plan(계획) → implement(구현) → validate(린터+빌드+타입체크+구조테스트) → repair(수정). 이 루프가 매 마일스톤마다 반복되면서 에이전트가 잘못된 방향으로 한참 나아간 뒤 되돌아오는 상황을 막아준다.
Hashimoto는 이 접근의 본질을 간결하게 요약한다. "나는 여전히 소프트웨어 프로젝트의 아키텍트다. 코드 구조, 데이터 흐름, 상태 위치를 직접 정한다. 에이전트에게는 '이 최종 목표를 달성하되, 이 형태를 사용하라'고 가이드라인을 준다." 사람이 아키텍처를 정하고, 린터가 그 아키텍처를 강제하고, 에이전트가 그 안에서 구현한다. 역할이 깔끔하게 나뉜다.
2. 도구를 빼는 기술
Vercel이 도구 15개를 2개로 줄인 사연
Vercel의 AI 분석 에이전트 d0는 원래 15개의 특화 도구를 갖고 있었다. GetEntityJoins, LoadCatalog, RecallContext, SearchSchema, GenerateAnalysisPlan, FinalizeQueryPlan... 이름만 봐도 역할이 세분화되어 있다.
논리는 합리적이었다. 모델이 실수할 수 있으니 각 단계를 미리 정해진 도구로 제한하면 실수가 줄어들 것이다. 모델을 신뢰하지 않으니 직접 판단하는 범위를 좁히겠다는 전략이다.
결과는 의도와 정반대였다. 에이전트가 본래 작업인 데이터 분석에 집중하지 못하고 "지금 어떤 도구를 써야 하지?"를 고민하느라 연산을 허비했다. 분석가여야 할 에이전트가 라우터로 전락한 것이다. 최악의 경우 724초를 소비하고 145,463 토큰을 태운 뒤에도 작업에 실패했다.
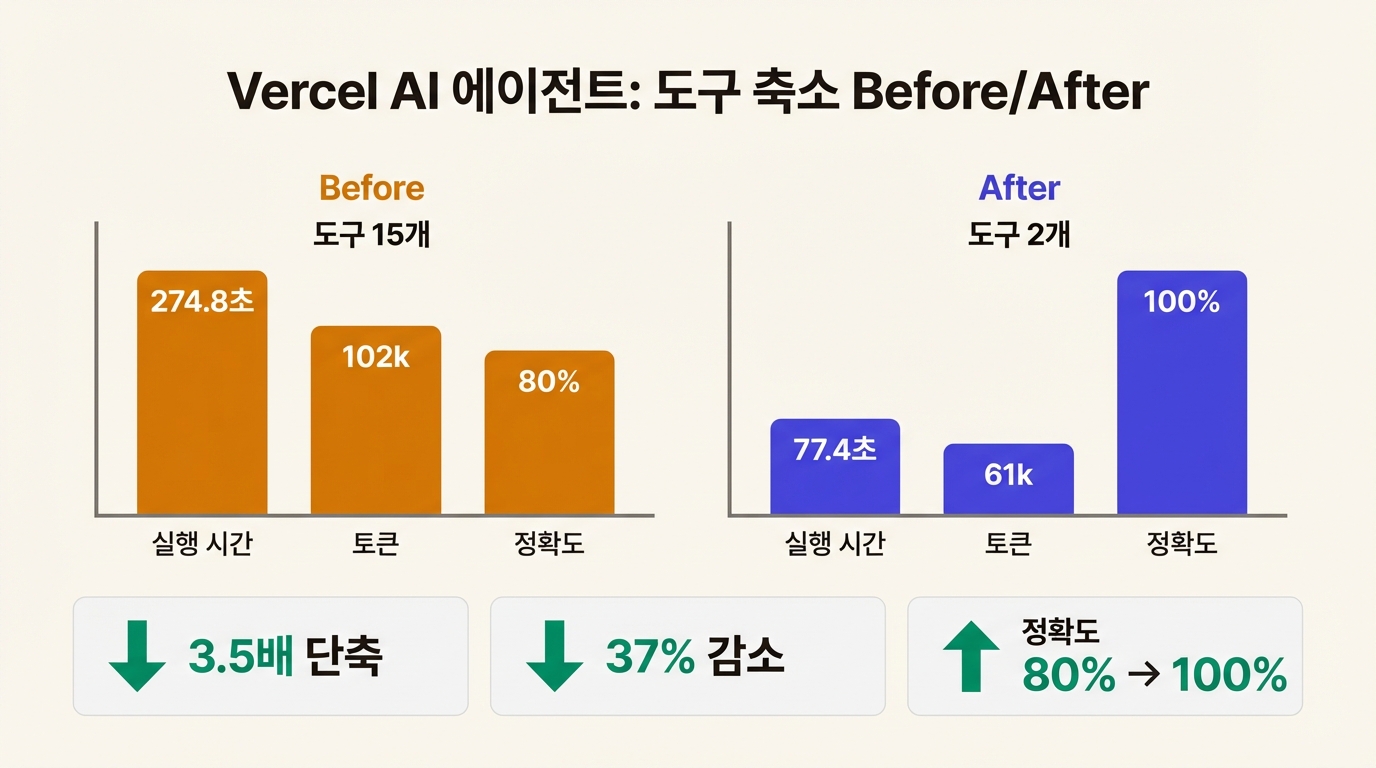
Vercel은 15개를 2개로 줄였다. ExecuteCommand(bash 명령 실행)와 ExecuteSQL. 그게 전부다.
| 지표 | 15개 도구 | 2개 도구 | 변화 |
|---|---|---|---|
| 실행 시간 | 274.8초 | 77.4초 | 3.5배 단축 |
| 성공률 | 80% | 100% | +20%p |
| 토큰 사용량 | ~102k | ~61k | 37% 감소 |
| 작업 단계 수 | ~12 | ~7 | 42% 감소 |
앞서 724초에 145k 토큰을 태우고도 실패했던 쿼리가, 새 시스템에서는 141초와 67,483 토큰으로 성공했다.
기술적 근거는 이렇다. Claude Opus 4.5 수준의 모델이라면 사전 필터링된 요약보다 원본 데이터에 직접 접근하는 편이 더 정확하다. 15개 특화 도구가 제공하던 "중간 요약"이 오히려 모델의 추론 능력을 제약하고 있었다. 도구를 빼자 모델이 원본 데이터를 직접 보고 스스로 판단할 수 있게 됐고, 정확도가 올라갔다.
Stripe는 400개를 큐레이션한다
Stripe의 접근은 Vercel과 방향이 같지만 규모가 다르다. Stripe의 에이전트 시스템 Minions는 "Toolshed"라는 도구 관리 시스템을 통해 400개가 넘는 MCP 도구를 운용한다. 코드베이스가 수억 줄이고 주당 1,000건 이상의 PR을 처리하는 규모에서는 도구 2개로 버틸 수 없다.
그래서 Stripe는 도구를 줄이는 대신 "한 번에 보는 양"을 제한했다. 400개 중 작업에 필요한 하위 집합만 각 에이전트에게 노출한다. 핵심 기법은 "사전 컨텍스트 수화(proactive context hydration)"다. 에이전트가 작업을 시작하기 전에 관련 MCP 도구를 결정론적으로(에이전트의 판단이 아니라 규칙 기반으로) 실행해서 필요한 정보를 미리 컨텍스트에 채워 넣는다. 에이전트가 "어떤 도구로 이 정보를 가져오지?"를 고민할 필요가 사라진다.
격리도 빠뜨릴 수 없다. Stripe의 Devbox는 에이전트에게 사람 엔지니어와 동일한 개발 환경을 제공하되 프로덕션 리소스와 인터넷으로부터 완전히 차단한다. 10초 내에 뜨고, Stripe 코드와 서비스가 미리 깔려 있다. 격리 덕분에 사람의 허가를 일일이 받지 않아도 에이전트가 자유롭게 실행할 수 있다. 역설적으로 격리라는 제약이 에이전트에게 더 큰 자유를 준 셈이다.
CI 통합에서도 실용적인 제한이 눈에 띈다. 각 git push마다 선택된 린트가 5초 내에 돌아간다. Stripe 전체 테스트(300만 개 이상) 중 관련 테스트만 골라 실행하고, 실패 시 자동 수정을 적용한다. 이 자동 수정 루프를 최대 2라운드로 제한한다는 점이 재미있다. 첫 push 후 실패하면 수정해서 두 번째 push. 두 번째에서도 실패하면 거기서 멈춘다. "세 번째 시도부터는 수확이 체감된다"는 판단이다.
선택지가 많으면 왜 정확도가 떨어지나
도구 수와 정확도의 관계는 직관에 어긋난다. 도구가 20개를 넘으면 에이전트의 "선택 마비"가 급격히 심해진다는 경험적 패턴이 있다. 400개 도구의 스키마(이름, 설명, 파라미터)를 컨텍스트에 넣으면 약 8,000 토큰을 잡아먹는다. 모델의 컨텍스트 윈도우가 유한한 상황에서 8,000 토큰이 도구 목록에 쓰이면, 그만큼 본래 작업에 쓸 공간이 줄어든다.
결정 분기 문제도 있다. 10개 도구 중 하나를 고르는 것과 50개 중 하나를 고르는 것은 차원이 다르다. 각 도구가 여러 파라미터를 받으면 조합의 수는 기하급수적으로 늘어난다. 이 조합 중 올바른 하나를 골라내는 것이 에이전트의 추론에 거는 부담이다.
이 문제를 풀려는 시도는 여러 방향에서 나오고 있다. Cursor의 "lazy-tools"는 필요한 시점에만 도구를 불러온다. 도구 시그니처를 벡터 DB에 저장하고 시맨틱 검색으로 관련 도구만 꺼내오는 접근도 있다. Stripe처럼 네임스페이스별로 도구를 계층적으로 라우팅하는 방법도 있다. 결국 핵심은 같다. "에이전트가 한 번에 보는 도구 수"를 줄이는 것.
3. 편집 포맷이라는 보이지 않는 제약
세 포맷이 실패하는 방식
AI 에이전트가 코드를 수정할 때 쓰는 포맷은 세 가지가 주류다. 각 포맷은 실패하는 방식 자체가 다르고, 그 차이가 모델에 걸리는 인지 부담의 차이를 드러낸다.
Patch 포맷(OpenAI apply_patch 스타일)은 변경할 부분의 앞뒤 맥락을 모델이 직접 재현해야 한다. 파일에서 "이 부분"을 정확히 짚으려면 주변 코드를 기억하고 있어야 한다. 모델이 기억에 의존하는 순간 오류가 끼어든다. 비OpenAI 모델에서 이 포맷의 실패율이 50%를 넘는 건 우연이 아니다.
String Replace 포맷(Claude Code, Gemini 방식)은 바꿀 문자열을 글자 그대로 재현한 뒤 새 문자열로 교체한다. "글자 그대로"가 핵심이다. 공백 하나, 탭 하나가 달라도 매칭이 실패한다. 200줄짜리 파일에서 정확한 구간을 한 글자도 틀리지 않고 복사해야 하니, 파일이 길어질수록 실패 확률이 올라가는 구조적 한계가 있다.
Hashline 포맷(Can Boluk이 설계)은 접근 자체가 다르다. 코드의 각 줄에 고유 식별자를 부여한다.
11:a3|function hello() {
22:f1| return "world";
33:0e|}
줄번호:해시|내용 형태의 2~3자짜리 콘텐츠 해시가 앵커 역할을 한다. 모델은 코드 내용을 통째로 재현할 필요가 없다. "줄 2:f1을 이걸로 바꿔라", "범위 1:a3부터 3:0e까지 교체", "3:0e 뒤에 삽입" 같은 식으로 해시 ID만 참조하면 된다.
이 해시는 줄 내용에서 파생된다. 파일이 마지막 읽기 이후 바뀌었으면 해시가 일치하지 않아 편집이 거부된다. 데이터베이스의 낙관적 동시성 제어(optimistic concurrency control)와 같은 원리다. 데이터를 읽을 때 버전 태그를 받고 수정을 제출할 때 그 태그가 여전히 유효한지 확인한다. 맞으면 수정이 반영되고, 누군가 먼저 바꿨으면 거부된다. Hashline의 해시가 정확히 이 역할을 한다.
16개 모델에서 작동하는 범용성
Hashline의 진짜 강점은 특정 모델에 맞춘 솔루션이 아니라는 점이다. Can Boluk은 "한 오후 만에 15개 LLM의 코딩 성능을 개선했다"고 밝혔다. 벤치마크 데이터를 보면 효과가 모델 전반에 걸쳐 나타난다.
Grok 4 Fast의 정확도가 6.7%에서 68.3%로 뛴 건 이미 알려진 수치다. 여기에 더해 출력 토큰이 61% 줄었다. 코드를 통째로 재현하는 대신 해시 참조만 하면 되니 모델이 "쓸" 양 자체가 줄어든 것이다. 무한 재시도 루프에 빠지는 현상도 사라졌다. MiniMax는 성공률이 2배 이상 올랐고, Gemini 3 Flash는 String Replace 대비 5포인트 상승했다.
Can Boluk의 표현이 핵심을 찌른다. "16개 서로 다른 모델에서 동등하게 잘 작동하는 첫 번째 솔루션." 모델마다 따로 최적화할 필요가 없다는 뜻이다. Patch 포맷은 OpenAI 모델에는 잘 맞지만 다른 모델에서 실패율이 높고, String Replace는 파일 길이에 따라 성능이 들쑥날쑥하다. Hashline이 모델 간 편차를 줄인 이유는, 모델의 "기억" 능력에 의존하는 부분을 구조적으로 없앴기 때문이다.
oh-my-pi라는 이름의 이 시스템은 약 7,500줄의 Rust 코드로 구현되어 플랫폼별 N-API 애드온으로 컴파일된다. 포맷 하나를 바꾸는 데 이 정도 엔지니어링이 들어간 이유가 있다. "모델이 실수할 수 있는 구간"을 체계적으로 제거하려면 해시 생성, 검증, 편집 도구 전체를 일관성 있게 설계해야 하기 때문이다.
셋이 공유하는 한 가지 원리
린터는 코드 구조 수준에서, 도구 제한은 에이전트 행동 수준에서, 편집 포맷은 코드 수정 수준에서 작동한다. 레이어는 다르지만 공통 원리는 하나다. 모델의 능력을 바꾸지 않고 실수할 수 있는 표면적을 줄인다.
CNCF(Cloud Native Computing Foundation)가 2026년 1월에 발표한 "자율 기업의 4필러" 중 Golden Paths 원리가 이 관찰과 맞닿는다. Golden Paths란 "안전하고 규정을 준수하는 선택을 가장 쉬운 선택으로 만드는 사전 승인된 블루프린트"다. 핵심은 이것이다: 표면적을 줄이면 가드레일이 커버해야 할 범위도 줄어든다.
린터, 도구 제한, 편집 포맷은 각각 다른 방식으로 Golden Paths를 구현한다. 린터는 코드가 갈 수 있는 경로를 좁히고, 도구 제한은 에이전트가 선택할 수 있는 행동을 좁히고, 편집 포맷은 코드를 수정하는 방법을 좁힌다. 셋 다 "올바른 길을 가장 쉬운 길로 만드는" 장치다.
이 원리를 끝까지 밀어붙인 사례가 있다. Peter Steinberger는 OpenClaw 프로젝트에서 월 6,600건 이상의 커밋을 찍으면서 코드를 한 줄도 직접 읽지 않고 출하한다. 5~10개 에이전트를 동시에 돌리는 솔로 개발이다. 이게 가능한 전제 조건이 바로 기계적으로 강제되는 아키텍처 제약이다. Steinberger는 스스로를 "자비로운 독재자"라고 표현한다. 아키텍처 결정만 사람이 하고 구현과 검증은 전부 에이전트에 위임한다. 코드를 안 읽어도 되는 건, 린터와 테스트와 빌드 검증이 "코드가 형태를 지키고 있는지"를 대신 확인해주기 때문이다.
제약이 만드는 자유
아키텍처 제약의 역설은 이것이다. 에이전트를 더 강하게 만드는 방법은 더 많은 자유를 주는 게 아니라 올바른 제약을 설계하는 것이다. 린터가 의존성 방향을 고정하고, 도구 목록이 선택지를 좁히고, 편집 포맷이 수정 방식을 단순화할 때 에이전트는 본래 작업에 집중할 여유를 얻는다.
그런데 제약이 "무엇을 하지 말라"를 정의한다면, 다음 질문은 자연스럽게 따라온다. "했는데 괜찮은가?"를 어떻게 검증할 것인가. 린터 에러 메시지가 교정 지침으로 작동한다는 사실 자체가 이미 피드백 루프의 시작점이다. 다음 편에서는 이 피드백 루프를 정면으로 파고든다.