동일한 LLM의 성능이 10배가 차이나는 이유
2026년 2월 12일, 개발자 Can Boluk이 실험 하나를 공개했다. 16개 AI 모델에 코딩 벤치마크를 돌렸는데, 가중치(모델이 학습한 내용)는 그대로 두고 코드 편집 포맷만 바꿨다. AI 에이전트가 코드를 수정할 때 변경 사항을 전달하는 형식, 그 껍데기만 손댄 것이다.
결과는 극적이었다. Grok Code Fast 1의 정확도가 6.7%에서 68.3%로 뛰었다. 10배. 벤치마크 순위로 치면 30위에서 5위다. 비용은 300달러, 시간은 오후 반나절. 모델 자체는 한 글자도 안 바꿨다.
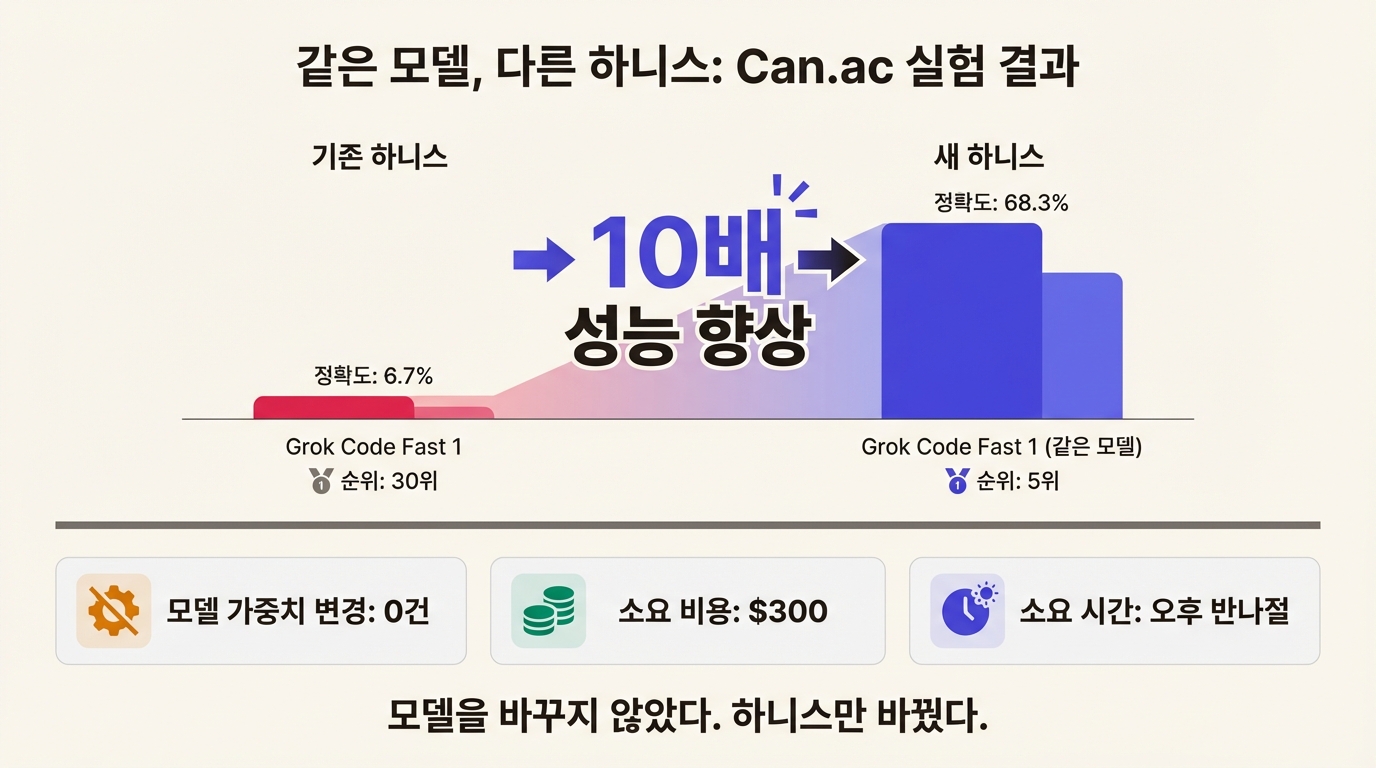
단순한 실험 같지만 시사하는 바가 분명하다. AI 성능을 결정하는 건 모델의 능력만이 아니다. 모델을 감싸는 시스템, 도구의 형식, 작업 환경, 피드백 구조가 결과를 좌우한다. 이 "모델을 감싸는 시스템"을 최근 업계에서 **하니스(harness)**라고 부르기 시작했다.
하니스 엔지니어링은 무엇이고, 왜 2026년에 갑자기 화두가 됐을까. 그 맥락을 짚어본다.
잘 물어보기에서 잘 감싸기로
프롬프트 엔지니어링 (2022~2024)
2022년 ChatGPT가 등장한 뒤, AI를 잘 쓰는 기술은 곧 "잘 물어보는 기술"이었다. 역할을 부여하고("너는 시니어 개발자야"), 단계별 사고를 유도하고("step by step으로 생각해"), 예시를 먼저 보여주는(few-shot) 테크닉이 쏟아졌다. 실제로 효과가 있었다. 간단한 질의응답이나 번역, 요약에서 프롬프트를 다듬는 것만으로 결과 품질이 눈에 띄게 올라갔다.
한계는 작업이 복잡해지면서 드러났다. 수천 줄짜리 코드베이스를 다루거나 여러 단계에 걸친 작업을 시킬 때, 프롬프트 한 줄에 담을 수 있는 정보는 한정적이다. "프롬프트를 잘 쓰면 된다"는 접근이 통하지 않는 영역이 점점 넓어졌다.
컨텍스트 엔지니어링 (2025)
2025년, 前 Tesla AI, 前 OpenAI의 Andrej Karpathy가 이름을 붙였다. "컨텍스트 엔지니어링: 다음 단계에 필요한 정확한 정보를 컨텍스트 윈도우에 채우는 섬세한 기술이자 과학."
컨텍스트 윈도우는 AI 모델이 한 번에 볼 수 있는 정보의 총량이다. 프롬프트 한 줄만 들어가는 게 아니다. RAG(외부 문서를 검색해서 모델에게 보여주는 기술)로 가져온 문서, 이전 대화 기록, 사용 가능한 도구 목록, 장기 메모리까지 전부 이 윈도우 안에 들어간다. 컨텍스트 엔지니어링은 이 윈도우에 무엇을 넣고 무엇을 뺄지 의도적으로 설계하는 것이다.
Shopify CEO Tobi Lutke가 "컨텍스트 엔지니어링은 핵심 스킬"이라 선언하면서 이 개념이 빠르게 퍼졌다. Shopify에서는 AI 활용이 직원의 기본 기대치가 됐을 정도다.
프롬프트 엔지니어링이 "질문을 잘 쓰는 기술"이었다면, 컨텍스트 엔지니어링은 "모델이 볼 세계 전체를 설계하는 기술"이다. 초점이 입력 한 줄에서 입력 전체로 확장됐다.
그런데 빈 곳이 있었다. 모델에게 좋은 정보를 넣어서 좋은 답을 얻는 데까지는 성공했다. 하지만 답이 나온 뒤의 이야기가 빠져 있었다. 결과물 검증은 누가 하나. 에이전트가 잘못된 행동을 했을 때 피드백 루프는 어떻게 돌리나. 수십 번, 수백 번 반복 실행할 때 품질이 서서히 떨어지는 현상(엔트로피)은 어떻게 잡나. 이 빈 곳이 2026년의 출발점이 됐다.
하니스 엔지니어링 (2026년 2월)
2026년 2월, 서로 다른 세 곳에서 거의 동시에 같은 개념을 꺼냈다.
Mitchell Hashimoto (2월 5일): Terraform, Vagrant, Ghostty 등을 만든 개발자다. "My AI Adoption Journey"라는 글에서 "harness engineering"이라는 말을 처음 썼다. 핵심 원칙은 이것이다: "에이전트가 실수할 때마다, 그 실수를 다시는 반복하지 않도록 솔루션을 엔지니어링한다." 에이전트에게 매번 "이건 하지 마"라고 말하는 대신, 환경 자체를 고쳐서 실수가 구조적으로 불가능하게 만드는 접근이다.
OpenAI (2월 11일): "Harness Engineering: Leveraging Codex in an Agent-First World"를 발표했다. 소수의 엔지니어가 5개월간 Codex 에이전트만으로 100만 줄의 프로덕션 코드를 생성하고 배포한 실험 보고다. 이 기간에 엔지니어가 직접 작성한 코드는 0줄. 대신 환경 설계, 의도 명세, 피드백 제공에 시간을 쏟았다.
Martin Fowler / Birgitta Bockeler (2월 17일): Thoughtworks의 수석 아키텍트 Fowler와 컨설턴트 Bockeler가 OpenAI의 하니스를 세 범주로 분류했다. Context Engineering(모델에게 제공하는 정보 설계), Architectural Constraints(코드 구조를 강제하는 규칙), Garbage Collection(에이전트가 만든 잔해물을 정리하는 메커니즘). "하니스가 새로운 서비스 템플릿이 될 수 있다"는 관찰도 덧붙였다.
세 곳이 사전 조율 없이 같은 시기에 같은 이름을 꺼냈다. 내 판단에, 이건 우연이 아니다. 각기 독립적으로 같은 결론에 도달했다는 건 특정 집단의 유행이 아니라, 실무에서 반복적으로 부딪힌 문제가 자연스럽게 이름을 얻은 것이다.
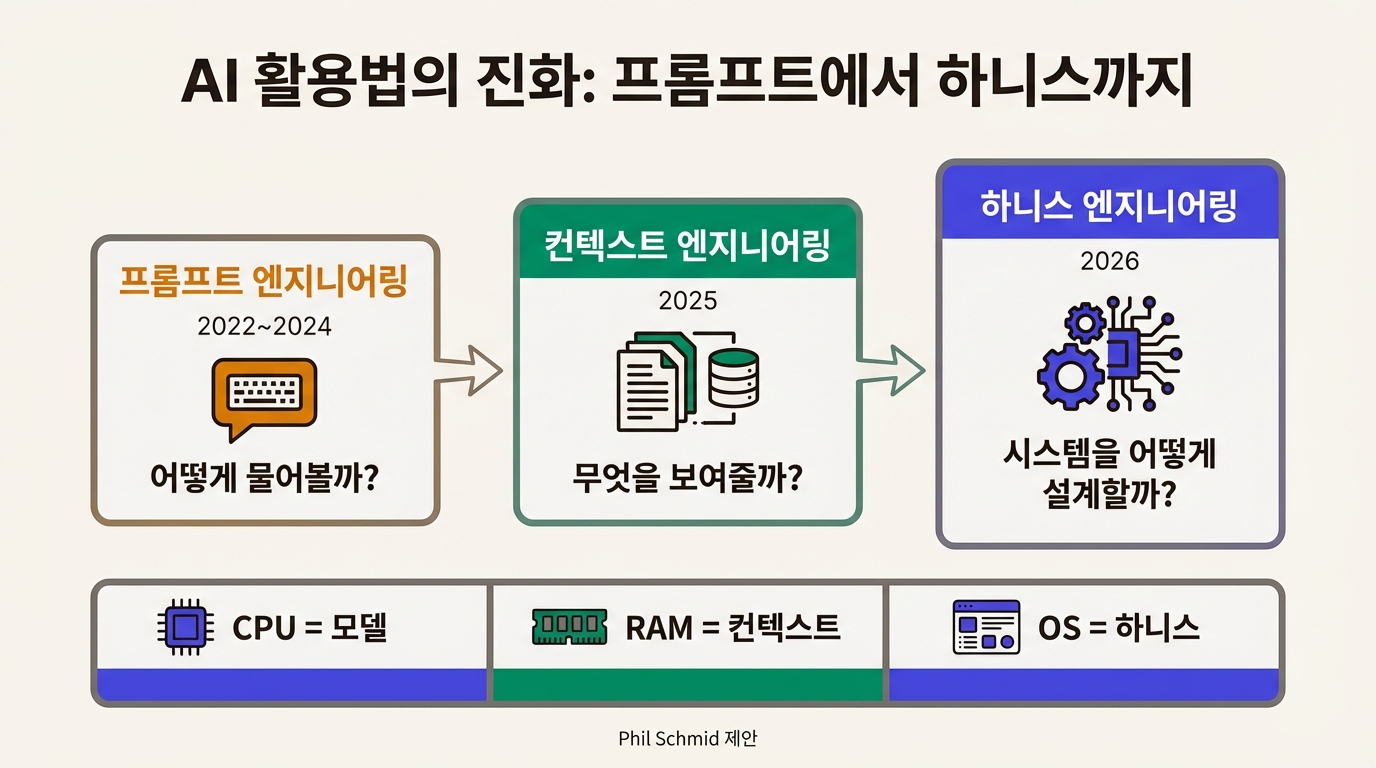
CPU, RAM, 그리고 OS
Phil Schmid(Hugging Face)가 제시한 컴퓨터 비유가 세 개념의 관계를 깔끔하게 정리한다.
| 컴퓨터 | AI 에이전트 | 하는 일 |
|---|---|---|
| CPU | 모델 | 연산 수행 |
| RAM | 컨텍스트 윈도우 | 작업에 필요한 정보 보관 |
| OS | 하니스 | 프로세스 관리, 자원 배분, 안전 장치 |
| 애플리케이션 | 에이전트 | 특정 작업 수행 |
CPU가 아무리 빨라도 OS가 허술하면 컴퓨터가 제대로 돌아가지 않는다. AI도 마찬가지다. 모델이 아무리 뛰어나도 하니스가 부실하면 에이전트는 헛돌 뿐이다. 글 서두에서 소개한 Can Boluk의 실험이 정확히 이걸 보여줬다. 같은 CPU(모델)에 OS(하니스)만 바꿨더니 성능이 10배 차이가 났다.
정리하면 이렇다. 프롬프트 엔지니어링은 CPU에게 전달하는 명령어를 다듬는 것이고, 컨텍스트 엔지니어링은 RAM에 올릴 데이터를 설계하는 것이고, 하니스 엔지니어링은 OS 전체를 설계하는 것이다. 이전 단계를 부정하는 게 아니라 포함하면서 확장한다.
실전 사례 세 가지
개념은 여기까지. 실제로 하니스를 잘 설계하면 어떤 차이가 나는지 사례를 본다.
Hashimoto의 방법: 규칙 축적과 도구 제작
Hashimoto가 공개한 방법은 두 가지다.
첫째, AGENTS.md를 통한 규칙 축적. 프로젝트 루트에 에이전트가 따라야 할 규칙을 문서로 남긴다. 에이전트가 작업을 시작할 때 이 문서를 자동으로 읽고 반영한다. 핵심은 "한 번 쓰고 끝"이 아니라는 점이다. 에이전트가 실수할 때마다 그 실수를 방지하는 규칙을 추가한다. 시간이 갈수록 실수가 줄어드는 구조가 만들어진다.
둘째, 프로그래밍된 도구 제작. 스크린샷 캡처, 필터 테스트 등 에이전트가 직접 쓸 수 있는 맞춤형 도구를 만들어준다. 사람이 화면을 보고 "이거 이상한데?"라고 판단하는 과정을 도구로 옮겨서 에이전트도 수행할 수 있게 만드는 셈이다.
두 방법의 공통점은 명확하다. 사람이 매번 개입하는 대신 환경 자체를 고친다. 프롬프트가 아니라 환경을 수정한다.
OpenAI Codex 팀의 5개월 실험
OpenAI가 공개한 Codex 실험은 하니스 엔지니어링을 조직 규모로 적용한 사례다.
핵심 장치는 "Golden Principles"라는 규칙 세트다. 리포지토리에 직접 심어놓은 아키텍처 규칙으로, 코드의 레이어 순서를 강제한다: Types, Config, Repo, Service, Runtime, UI. 에이전트가 이 순서를 어기면 코드가 아예 통과되지 않는다. "레이어 순서를 지켜"라고 프롬프트로 부탁하는 게 아니다. 순서를 어기면 시스템이 거부한다.
5개월간의 결과: 엔지니어가 직접 작성한 코드 0줄, Codex가 생성한 코드 100만 줄 이상. 엔지니어는 코드를 쓰는 대신 환경을 설계하고, 의도를 명세하고, 결과를 검토하는 역할로 완전히 전환됐다.
다만 솔직히 짚어야 할 점이 있다. Bockeler가 지적했듯이 OpenAI의 보고서에는 구조적 정합성(아키텍처 규칙 준수)에 대한 내용은 상세하지만, "코드가 의도한 대로 동작하는가"를 확인하는 기능 검증 장치에 대한 설명은 부족하다. 100만 줄이라는 숫자만으로 코드 품질을 판단할 수는 없다. 하니스 엔지니어링이 무엇을 해결했는지뿐 아니라 아직 무엇이 열려 있는지도 같이 봐야 한다.
Fowler와 Bockeler의 세 범주
Fowler와 Bockeler가 OpenAI의 하니스를 분석하며 제시한 세 범주는 하니스의 구성 요소를 이해하는 틀로 유용하다.
Context Engineering: 모델에게 어떤 정보를 제공할지 설계하는 것. 앞서 다룬 컨텍스트 엔지니어링이 하니스의 한 축으로 들어온 셈이다.
Architectural Constraints: 에이전트가 따라야 할 구조적 규칙. Golden Principles처럼 코드 구조를 강제하거나 특정 패턴을 금지하는 장치다.
Garbage Collection: 에이전트가 작업하면서 만들어내는 잔해물(불필요한 코드, 깨진 테스트, 일관성 없는 네이밍)을 자동으로 정리하는 메커니즘이다.
이 분류가 보여주는 건 하니스 엔지니어링이 "좋은 프롬프트를 주는 것"의 확장이 아니라는 점이다. 입력을 설계하고, 구조를 강제하고, 잔해를 정리하는 시스템 전체를 만드는 작업이다. OpenAI가 5개월간 이 시스템을 구축하는 데 쏟은 시간이 100만 줄이라는 산출물의 토대가 됐다.
모델은 교체되지만 하니스는 남는다
2026년 2월 현재, 최상위 AI 모델은 Claude Opus 4.6(Anthropic), GPT-5.3-Codex(OpenAI), Gemini 3.1 Pro(Google)다. 코딩 영역에서는 GPT-5.3-Codex와 Opus가 경쟁하고, 과학 지식에서는 Gemini가 앞선다. 모델 간 최저가와 최고가 차이는 33배에 달한다.
6개월 후면 이 순위는 바뀐다. 새 모델이 나오고, 기존 모델은 밀려난다.
반면 잘 설계된 하니스는 모델이 바뀌어도 유지된다. Hashimoto의 AGENTS.md는 Claude에서 Gemini로 모델을 바꿔도 그대로 작동한다. OpenAI의 아키텍처 제약은 Codex 다음 모델이 나와도 적용 가능하다. Can Boluk의 코드 편집 포맷도 모델을 가리지 않는다.
여기서 내가 강조하고 싶은 건 이 점이다. 빠르게 감가상각되는 모델에 모든 걸 거는 것보다, 모델 교체와 무관하게 축적되는 시스템에 투자하는 쪽이 합리적이다. "어떤 모델을 쓸 것인가"보다 "어떤 환경을 설계할 것인가"가 장기적으로 더 큰 차이를 만든다.
이 시리즈의 다음 편에서는 하니스의 내부를 분해한다. 아키텍처 제약, 피드백 루프, 워크플로우 제어, 개선 사이클. 하니스를 구성하는 네 가지 축을 Can.ac와 OpenAI 사례로 하나씩 뜯어본다.