원문: BitDance: Scaling Autoregressive Generative Models with Binary Tokens | arXiv 2026 | Jiaming Han et al. (ByteDance Research, CUHK)
코드북이라는 사전을 버리면 어떤 일이 벌어지는가
AI 이미지 생성에는 크게 두 갈래가 있다. Stable Diffusion 계열의 디퓨전 모델, 그리고 GPT처럼 토큰을 하나씩 찍어 나가는 Autoregressive(AR) 모델. AR 모델은 텍스트와 이미지를 하나의 시퀀스 안에 넣을 수 있어서 멀티모달 AI의 핵심 축으로 떠올랐다.
그런데 AR 모델이 이미지를 다루려면, 먼저 이미지를 토큰으로 바꿔야 한다. 2017년 VQ-VAE 이후 7년간 이 변환을 도맡은 건 VQ(Vector Quantization) 코드북이었다. 이미지 조각마다 미리 만들어 둔 사전에서 가장 비슷한 항목을 찾아 그 번호로 치환하는 방식이다. 사전이 8,192개 항목이면, 토큰 하나는 8,192가지 상태 중 하나를 갖는다.
문제는 이 사전을 키우기가 매우 어렵다는 것이다. 항목이 수천 개를 넘어가면 codebook collapse가 발생한다. 수천 개 항목 가운데 실제로 쓰이는 건 일부뿐이고 나머지는 학습 과정에서 죽어 버린다. 사전의 크기가 곧 이미지 품질의 천장이 되는 셈이다.
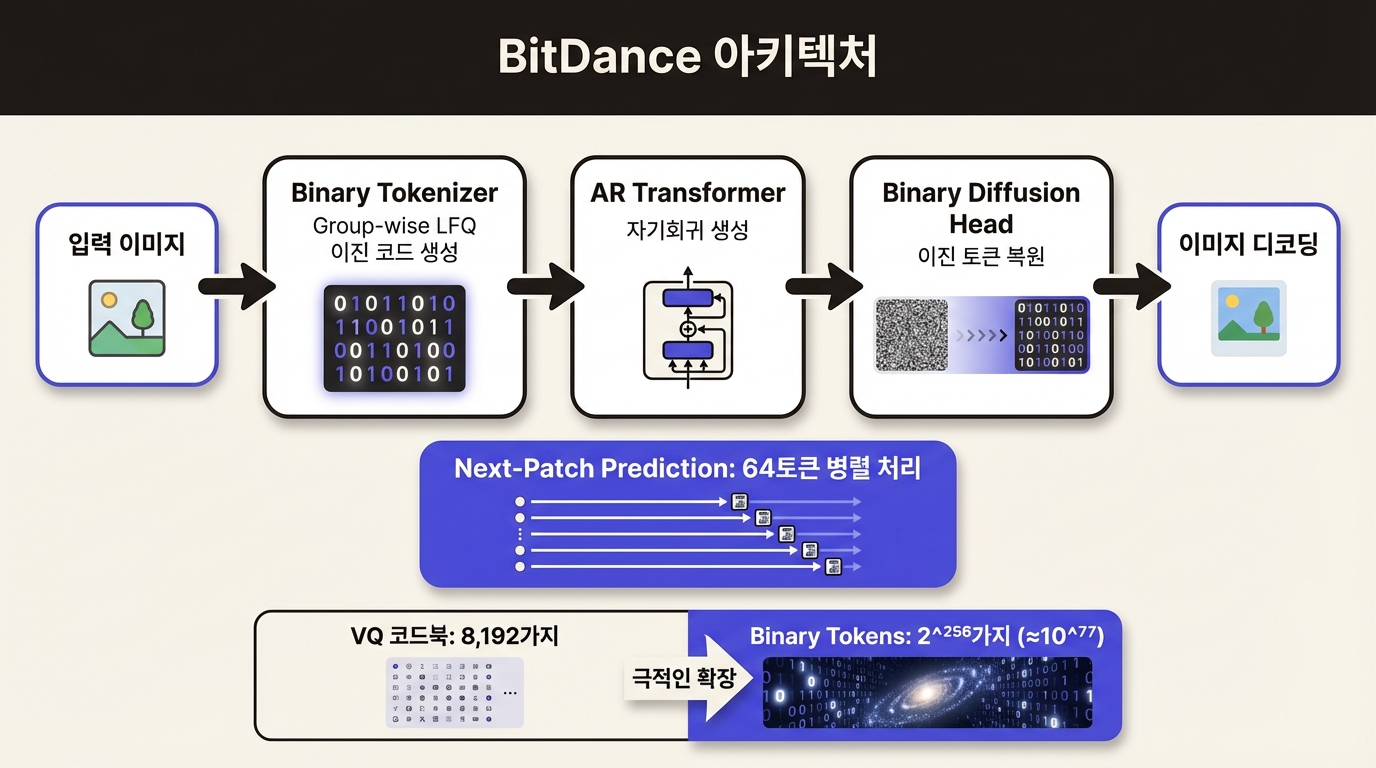
ByteDance Research와 CUHK 공동 연구팀이 내놓은 BitDance는 이 사전을 아예 치운다. 코드북 대신, 0과 1만으로 이루어진 이진 벡터로 이미지를 표현한다. ImageNet 256x256에서 FID 1.24를 찍으며 AR 모델 최고 기록을 갈아치웠고, 14B 파라미터 텍스트-이미지 모델까지 오픈소스로 풀었다.
2^256이라는 표현 공간
BitDance의 토크나이저는 이미지를 16배 축소해 16x16 = 256개 패치로 나눈 뒤, 각 패치를 d차원 이진 벡터로 바꾼다. d=256일 때 토큰 하나가 가질 수 있는 상태는 2^256, 약 10^77가지다. 관측 가능한 우주의 원자 수(약 10^80)와 비슷한 규모인데, 기존 VQ 코드북의 8,192가지와는 차원이 다르다.
핵심 기법은 Group-wise Lookup-Free Quantization(LFQ)이다. 이름 그대로 코드북 조회 자체를 없앤다. 인코더가 뱉은 연속 벡터의 각 차원을 0 또는 1로 양자화하되, 채널을 여러 그룹으로 묶어 그룹 단위로 엔트로피를 관리한다. 이 엔트로피 정규화가 모든 비트를 골고루 쓰도록 유도하기 때문에, VQ에서 고질적이던 collapse가 구조적으로 일어나지 않는다.
2^256개 선택지에서 다음 토큰을 고르는 법
그런데 새로운 난관이 생긴다. 기존 AR 모델은 다음 토큰을 예측할 때 softmax를 쓴다. 선택지가 8,192개면 8,192차원 확률 벡터를 계산하면 된다. 선택지가 2^256개라면? 이 크기의 softmax는 물리적으로 계산할 수 없다.
BitDance는 디퓨전으로 이 문제를 돌파한다. AR backbone(Decoder-only Transformer)이 앞선 토큰들의 문맥 정보를 인코딩하면, 그 조건 아래에서 경량 디퓨전 모듈이 노이즈로부터 이진 벡터를 점진적으로 복원한다. 수학적으로는 연속 하이퍼큐브 [0,1]^d 위에서 velocity-matching objective로 학습한 뒤, 최종 출력을 임계값으로 이진화한다.
여기서 Infinity와의 차이가 드러난다. Infinity(CVPR 2025 Oral)도 비트 단위 예측을 시도했지만, 각 비트를 독립적으로 분류했다. BitDance의 디퓨전 헤드는 256개 비트의 결합 분포(joint distribution)를 모델링한다. 비트들 사이의 상관관계를 디퓨전 과정 전체에 걸쳐 학습하는 것이다. 좋은 이미지 조각이 되려면 256개의 0과 1이 어떤 조합을 이루어야 하는지를 모델이 스스로 알아낸다.
한 번에 64토큰씩
AR 모델의 오래된 약점은 속도다. 256x256 이미지를 256개 토큰으로 나타내면, 토큰을 하나씩 예측하는 방식으로는 최소 256 스텝이 필요하다. 1024x1024라면 수천 스텝이다.
BitDance는 next-patch diffusion으로 이 벽을 넘는다. 한 스텝에서 1개가 아닌 최대 64개 토큰을 동시에 예측한다. 같은 패치 그룹 안의 토큰들은 block-wise causal mask를 통해 서로의 정보를 참조할 수 있고, 이전 그룹의 맥락도 그대로 활용한다. 1024x1024 이미지 기준으로 수천 스텝이 약 64 스텝으로 줄어든다.
이 효율이 실제 성능에 어떻게 반영되는지 보자. 260M 파라미터의 BitDance-B-16x가 1.4B 파라미터의 LlamaGen-XXL보다 낮은 FID를 기록했다. 파라미터가 5분의 1 수준인 모델이 더 좋은 이미지를 만든 것이다.
실험 결과를 들여다보면
BitDance-H(1.0B 파라미터)는 ImageNet 256x256 class-conditional generation에서 FID 1.24를 달성했다. 같은 조건에서 VQ 기반 LlamaGen-XXL(1.4B)은 2.34다. 파라미터가 적은 모델이 FID를 거의 절반으로 낮춘 셈이다.
속도 차이는 더 극적이다. BitDance-B-16x(260M)는 초당 90.26장을 생성한다. MAR-L이 초당 1.39장인 것과 비교하면 65배 가까운 차이다. 기존 next-token AR 대비로는 256x256에서 8.7배, 1024x1024에서 30배 이상 빠르다.
14B 파라미터 텍스트-이미지 모델도 주목할 만하다. DPG-Bench 88.28, GenEval 0.86으로 오픈소스 모델 상위권에 들었다. GLM-Image 대비 4.3배 빠르면서 품질도 앞서고, Qwen-Image나 Z-Image 같은 디퓨전 기반 모델보다도 속도가 우위다.

냉정하게 볼 부분
성과가 눈에 띄지만, 몇 가지 유보가 필요하다.
이진 양자화에는 본질적인 정보 손실이 따른다. BitDance 토크나이저의 PSNR은 25.29로, MAGVIT2 같은 최고급 VQ 토크나이저와 동급이거나 약간 낮다. 이론적 표현 공간이 2^256이라고 해서 재구성 품질이 그에 비례하지는 않는다.
1024x1024 이미지 생성에는 약 30초가 걸린다. 기존 AR 모델보다야 빠르지만, 실시간 응용에 투입하기엔 아직 멀었다.
논문 공개 후 아직 2주가 채 되지 않았다. 커뮤니티의 독립적 재현이나 심층 검증은 이루어지지 않은 상태다. 영어와 중국어 프롬프트에서는 강하지만 다른 언어에서의 품질이 불안정하다는 보고(GIGAZINE)도 있다.
평가가 ImageNet에 집중되어 있다는 점도 염두에 둘 필요가 있다. 다른 도메인이나 스타일에서의 일반화 성능은 아직 확인되지 않았다.
핵심 질문 3개
1. 이산 토큰인가, 연속 토큰인가
MAR은 VQ를 완전히 걷어내고 연속 토큰으로 AR 모델을 돌렸다. BitDance는 이산(이진) 토큰을 고수한다. 텍스트-이미지 통합 모델링에서는 이산 토큰이 자연스럽지만, 재구성 품질은 연속 쪽이 유리할 수 있다. 두 경로가 최종적으로 어디서 만나거나 갈라지는지가 핵심 쟁점이다.
- 관련 논문: Autoregressive Image Generation without Vector Quantization (MAR, NeurIPS 2024)
2. Next-patch prediction의 확장 한계는 어디인가
64토큰 동시 예측은 VAR의 next-scale prediction과 다른 전략이다. 패치 크기를 더 키우면 품질이 어떻게 변하는가. 비디오처럼 시간 축이 추가되면 이 전략이 여전히 유효한가. 둘 다 열린 질문이다.
- 관련 논문: Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction (VAR, NeurIPS 2024 Best Paper)
3. 비트 간 상관관계 모델링은 실제로 얼마나 중요한가
Infinity는 비트를 독립 분류해도 좋은 결과를 냈다. BitDance는 joint distribution이 더 낫다고 주장하지만, 두 방식의 직접 비교 실험이 충분히 제시되지는 않았다. 비트 간 상관관계가 생성 품질에 미치는 영향을 정량적으로 분리할 수 있을까.
- 관련 논문: Infinity: Scaling Bitwise AutoRegressive Modeling for High-Resolution Image Synthesis (Infinity, CVPR 2025 Oral)
출처
- Han, J. et al. (2026). "BitDance: Scaling Autoregressive Generative Models with Binary Tokens." arXiv:2602.14041.
- Li, T. et al. (2024). "Autoregressive Image Generation without Vector Quantization." NeurIPS 2024 Spotlight. arXiv:2406.11838.
- Tian, K. et al. (2024). "Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction." NeurIPS 2024 Best Paper. arXiv:2404.02905.
- Han, J. et al. (2024). "Infinity: Scaling Bitwise AutoRegressive Modeling for High-Resolution Image Synthesis." CVPR 2025 Oral. arXiv:2412.04431.
- Tang, H. et al. (2025). "HART: Efficient Visual Generation with Hybrid Autoregressive Transformer." ICLR 2025. arXiv:2410.10812.
- Esser, P. et al. (2021). "Taming Transformers for High-Resolution Image Synthesis." CVPR 2021.
- van den Oord, A. et al. (2017). "Neural Discrete Representation Learning." NeurIPS 2017.