원문: MedCoG: Maximizing LLM Inference Density in Medical Reasoning via Meta-Cognitive Regulation | arXiv 2026 | Yu Zhao, Hao Guan, Yongcheng Jing, Ying Zhang, Dacheng Tao (NTU)
토큰 효율이라는 질문
의료 LLM을 만져 본 사람이라면 이 딜레마를 알 것이다. GPT-4에 Chain-of-Thought를 걸고 RAG까지 붙이면 정확도는 올라가는데, 토큰 비용이 걷잡을 수 없이 불어난다. 정확도와 비용이 같은 방향으로 움직이는 이 구조를 어떻게 깰 수 있을까.
NTU의 Yu Zhao 등이 내놓은 MedCoG는 이 문제를 inference density라는 렌즈로 재정의한다. "얼마나 맞혔나"가 아니라 "토큰 1개당 얼마나 맞혔나"를 묻는 것이다. 결과는 기존 방법 대비 5.5배 높은 토큰 효율. 의료 LLM의 비용-정확도 곡선을 한 단계 바깥으로 밀어낸 셈이다.
추론 비용이 의료 도메인에서 유독 아픈 이유
LLM 성능 향상의 기본 공식은 단순하다. 더 큰 모델, 더 긴 프롬프트, 더 많은 외부 지식. Scaling law가 이를 뒷받침해왔다. 그런데 추론 시간(inference time)으로 오면 사정이 달라진다.
2025년 Nature Machine Intelligence에 실린 Densing Law(arXiv 2412.04315)에 따르면, 단위 파라미터당 LLM 성능은 약 3.5개월마다 2배로 개선되고 있다. 모델 자체는 점점 작아지면서도 똑똑해지는 셈이다. 하지만 이건 파라미터 효율 이야기일 뿐, 추론 시간에 쏟아붓는 토큰의 효율과는 별개다.
의료 도메인에서 이 비효율이 유독 날카롭게 드러나는 데에는 두 가지 구조적 이유가 있다. 첫째, 오진의 대가가 크다. 이미지 분류에서 고양이를 개로 분류하는 것과 폐렴을 폐암으로 오진하는 것은 차원이 다르다. 둘째, 문제 난이도의 편차가 극심하다. 감기 진단과 희귀 자가면역질환 감별은 필요한 추론의 깊이가 완전히 다른데, 기존 파이프라인은 둘 다 같은 무게의 추론을 돌린다. 감기 환자에게도 MRI를 찍는 격이다.
"더 많이 넣으면 더 잘하나?"에 대한 반례
현재 의료 LLM의 주류 접근법들(Chain-of-Thought, RAG, multi-agent)은 공통된 가정 위에 서 있다. 지식을 더 넣으면 더 잘한다. MedCoG는 이 가정에 정면으로 반례를 제시한다.
논문의 ablation study 결과가 이를 선명하게 보여준다. MedCoG-All, 구조화된 CoT와 지식 그래프와 사례 은행을 전부 투입한 버전은 평균 정확도 33.2%에 그쳤다. 반면 메타인지 조절로 필요한 것만 골라 넣은 MedCoG-Meta는 37.5%를 기록했다. 지식을 덜 넣었는데 더 잘 맞힌 것이다.
원인은 단순하다. 불필요한 지식이 noise로 작동했다. 에러를 세부 유형별로 뜯어보면, KG Noise(지식 그래프에서 유입된 정보가 오히려 모델을 틀린 방향으로 끌고 간 사례)가 MedCoG-All에서 23건이었던 것이 MedCoG-Meta에서 10건으로 절반 넘게 줄었다.
이건 직관과도 맞아떨어진다. 경험 많은 의사는 감기 환자를 볼 때 교과서를 펼치지 않는다. 희귀 질환이 의심될 때만 문헌을 뒤진다. MedCoG가 하려는 것도 같다. "언제 깊이 생각할지"를 LLM이 스스로 결정하게 만드는 것.
메타인지라는 해법
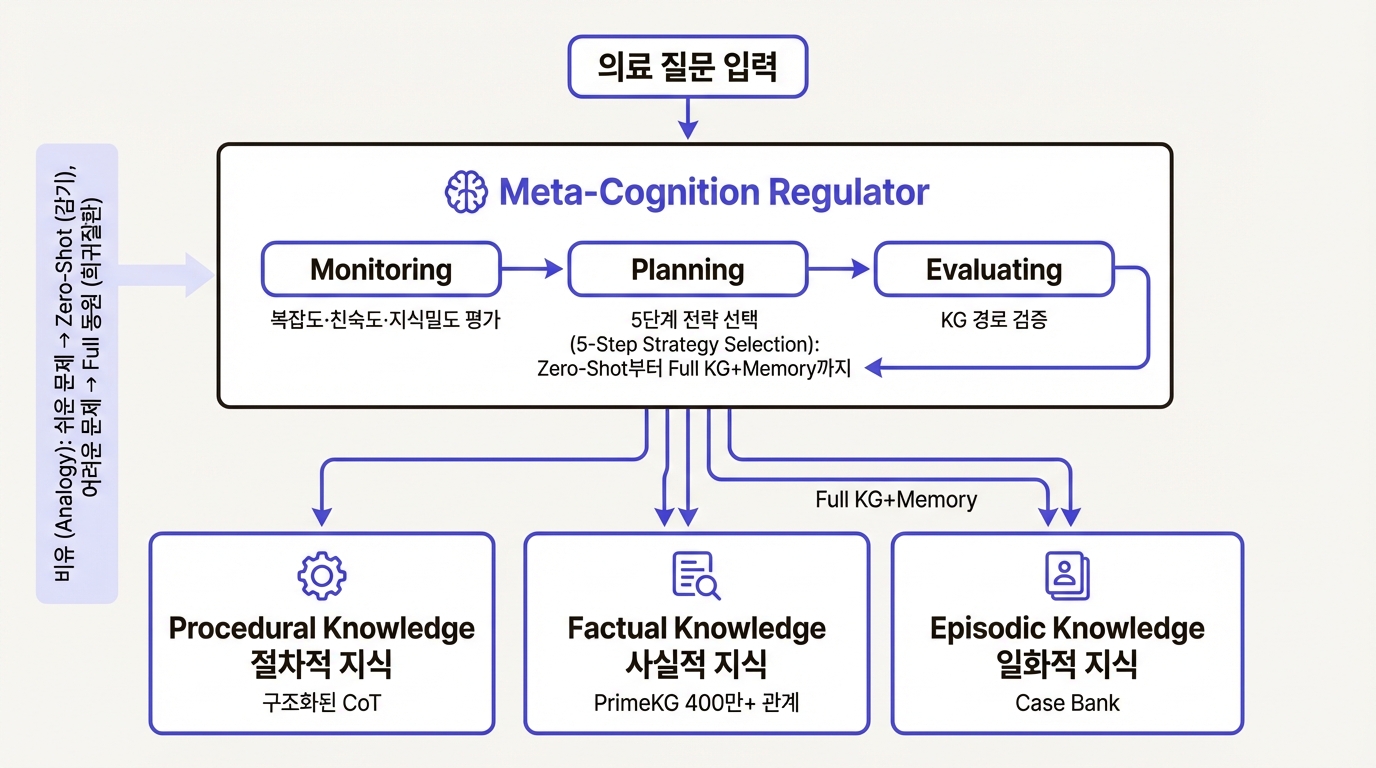
메타인지(metacognition)는 인지심리학에서 "자기 사고에 대한 사고"를 가리킨다. 시험을 볼 때 "이건 바로 풀 수 있다"와 "이건 시간을 들여야 한다"를 구별하는 능력이 메타인지다. MedCoG는 이것을 LLM 추론 파이프라인에 세 단계로 옮겨놓았다.
Monitoring: 문제부터 진단한다. LLM이 의료 질문을 받으면 바로 답을 내지 않는다. 먼저 복잡도(문제가 단순 사실 확인인지 다단계 추론인지), 친숙도(사전학습에서 충분히 본 패턴인지), 지식 밀도(외부 지식 없이 풀 수 있는지)의 세 축으로 문제를 평가한다. 이 조합이 문제의 난이도 프로필이 된다.
Planning: 전략을 고른다. 난이도에 따라 다섯 단계 중 하나가 선택된다. 가장 가벼운 것은 Zero-Shot, 아무 자원 없이 바로 답하는 것이다. 여기에 구조화된 사고 사슬(SCoT)을 붙이거나, PrimeKG 지식 그래프를 검색하거나, 과거 유사 사례를 Case Bank에서 불러오거나, 셋 다 동원하는 풀옵션까지 단계가 나뉜다. 핵심은 모든 문제에 풀옵션을 적용하지 않는다는 것이다. 쉬운 문제에 무거운 파이프라인은 토큰 낭비일 뿐 아니라, 앞서 봤듯 정확도까지 깎아먹는다.
Evaluating: 답을 검증한다. 지식 그래프를 사용한 경우, KG에서 추출한 경로가 답변의 논리와 정합하는지 확인한다. 맞지 않으면 다른 전략으로 재추론에 들어간다.
세 종류의 지식 자원
MedCoG가 동원하는 외부 지식은 세 갈래다.
절차적 지식(Procedural Knowledge)은 Structural CoT의 형태를 띤다. "감별 진단 시 증상을 먼저 나열하고, 각 후보 질환과 대조하라"는 식의 추론 템플릿이다. 사실적 지식(Factual Knowledge)은 Harvard에서 구축한 PrimeKG 기반으로, 질환-유전자, 약물-부작용 등 400만 건 이상의 관계를 포함하는 의료 지식 그래프다. 경험적 지식(Episodic Knowledge)은 Case Bank라 부르는데, 과거에 풀었던 문제-답-보상 삼중항을 저장해두고 유사한 새 문제에서 참조한다. 경험 많은 의사가 이전 환자 사례를 떠올리는 것과 같은 메커니즘이다.
메타인지 조절기는 문제의 성격에 따라 이 세 자원을 조합하거나, 아예 쓰지 않는 판단을 내린다.
실험: Inference Density가 보여주는 것
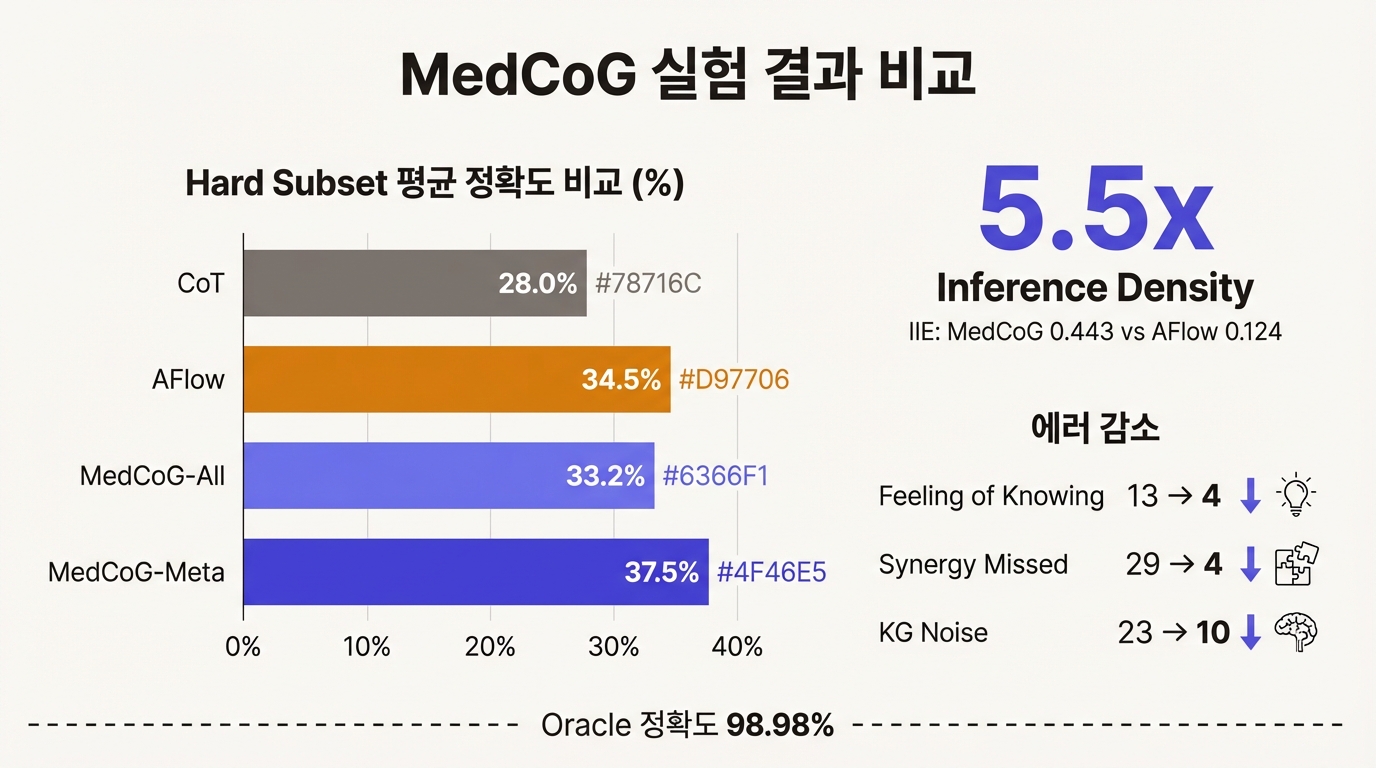
실험 설계부터 눈여겨볼 부분이 있다. MedCoG는 MedQA, MedMCQA, MMLU, MMLU-Pro, PubMedQA 등 5개 벤치마크에서 기존 방법들이 이미 틀린 문제만 모아서 평가했다. 쉬운 문제에서 점수를 부풀리는 게 아니라, 진짜 어려운 문제에서 얼마나 더 맞히는지를 측정하겠다는 뜻이다.
핵심 수치를 짚어보면, MedCoG-Meta의 Hard subset 평균 정확도는 37.5%로 CoT(28.0%)와 AFlow(34.5%)를 넘어섰다. 토큰 효율 지표인 IIE(Inference-Intensive Efficiency)는 0.443으로 AFlow의 0.124를 크게 앞질렀다. 에러 유형별로 보면 Feeling of Knowing 에러가 13건에서 4건으로, Synergy Missed가 29건에서 4건으로, KG Noise가 23건에서 10건으로 줄었다.
Inference density의 정의는 ρ(M) = f⁻¹(Acc_M) / C_M이다. 정확도를 달성하는 데 필요한 능력치를 비용으로 나눈 값이므로, 같은 정확도를 더 적은 토큰으로 달성하거나 같은 토큰으로 더 높은 정확도를 낼수록 이 값이 커진다. MedCoG가 기존 대비 5.5배 높은 inference density를 기록했다는 것은, 토큰 한 개가 하는 일의 밀도가 5.5배 높아졌다는 뜻이다.
Oracle 실험도 음미할 만하다. 메타인지 조절기가 매번 최적 전략을 골랐다고 가정하면 정확도가 98.98%까지 치솟는다. 현재 37.5%와의 격차 61%포인트는 전략 선택 정확도의 개선 여지가 그만큼 넓다는 뜻이면서, 동시에 이 프레임워크의 천장이 매우 높다는 증거이기도 하다.
한계와 현실적 맥락
MedCoG의 접근이 설득력 있다고 해서 한계를 간과할 수는 없다.
절대 정확도 문제. Hard subset 37.5%라는 숫자를 현실 진료실에 대입하면, 어려운 문제 10개 중 6개 이상을 틀린다. 보조 도구로서의 신뢰를 확보하기엔 부족한 수치다.
환각은 여전하다. 메타인지 조절이 불필요한 지식 유입을 줄여주긴 하지만, LLM 자체가 만들어내는 환각(hallucination)까지 차단하지는 못한다. 메타인지와 환각 억제는 다른 문제다.
지식 자원의 편향이 전이된다. PrimeKG가 특정 질환 영역에서 편향되어 있으면 추론도 편향된다. Case Bank는 더 까다롭다. 초기 사례의 성공/실패 패턴이 누적되면서, 강화학습의 reward hacking처럼 편향이 증폭될 위험이 있다.
단일 backbone으로만 검증했다. 실험은 GPT-4o-mini 한 모델로 수행됐다. 메타인지 조절기의 monitoring 단계가 모델의 self-assessment 능력에 의존하는 구조이므로, Llama나 Gemini처럼 backbone이 달라지면 결과도 달라질 공산이 크다.
규제적 맥락. 효율이 아무리 좋아져도 의료 AI는 보조 도구다. inference density 개선은 "더 나은 보조 도구"를 만드는 데 기여하지, "의사를 대체하는 AI"를 향한 길과는 다르다.
이 논문이 열어놓은 질문 세 가지
메타인지 조절기의 정확도가 병목이다. Oracle(98.98%)과 Meta(37.5%)의 격차는 모델의 의료 추론 능력보다 전략 선택 능력이 현재 성능의 상한을 결정한다는 뜻이다. 모델 크기를 키우는 것보다 조절기를 개선하는 편이 효과적일 수 있다. 후속 연구인 Meta-R1(arXiv 2508.17291)이 reinforcement learning으로 메타인지를 학습시키는 방향을 탐색하고 있어 흐름이 이어지는 중이다.
다른 고위험 도메인으로의 확장. Inference density와 메타인지 프레임워크 자체는 의료에 한정되지 않는다. 법률 자문이나 금융 분석처럼 문제 난이도 편차가 크고 오답의 비용이 높은 도메인이라면 같은 접근이 유효하다. 다만 도메인별 지식 그래프와 난이도 평가 기준을 새로 설계해야 한다.
한국어 의료 지식 그래프. MedCoG는 영어 기반 PrimeKG에 의존한다. 한국 의료 환경(특유의 질환 분포, 약물 처방 패턴, 건강보험 기준)을 반영한 대규모 한국어 의료 KG는 아직 공개된 것이 없다. 이 인프라가 갖춰진다면 한국형 MedCoG 변형의 가능성이 열린다.
추가로 읽으면 좋은 논문:
- Meta-R1 (arXiv 2508.17291): 메타인지를 reinforcement learning으로 학습하는 후속 접근
- KGARevion (arXiv 2410.04660, ICLR 2025): 지식 그래프 기반 의료 추론의 또 다른 프레임워크
- Densing Law (arXiv 2412.04315, Nature MI 2025): LLM 효율성의 이론적 기반
출처
- MedCoG: arXiv 2602.07905
- Densing Law: arXiv 2412.04315 (Nature Machine Intelligence, 2025)
- Meta-R1: arXiv 2508.17291
- KGARevion: arXiv 2410.04660 (ICLR 2025)
- KG4Diagnosis: arXiv 2412.16833 (AAAI 2025)
- PrimeKG: Harvard Precision Medicine