원문: Gated Attention for Large Language Models | NeurIPS 2025 Best Paper | Qwen Team, Alibaba
수식 하나, 핵심 기여 하나
NeurIPS 2025 Best Paper의 핵심 기여는 수식 한 줄로 요약된다.
Y' = Y ⊙ σ(XWθ)
Softmax 어텐션의 출력 Y에 sigmoid 게이트를 element-wise로 곱한다. 이게 전부다.
그런데 이 단순한 변형이 2017년부터 트랜스포머가 안고 있던 구조적 문제, 어텐션 싱크(attention sink)를 46.7%에서 4.8%로 낮춘다. 30가지 모델 변형에서 일관되게 성능을 끌어올리며, 추론 지연은 2% 미만이다. NeurIPS 프로그램 위원회가 최고 논문으로 선정한 이유가 여기에 있다.
이 글은 어텐션 싱크가 왜 발생하는지, 기존 해법들이 어디서 막혔는지, 그리고 Gated Attention이 어떻게 이 문제를 비껴가는지를 순서대로 다룬다. Alibaba Qwen 팀이 실제 Qwen3-Next-80B에 적용한 배포 사례도 함께 살핀다.
Softmax의 함정: 합이 1이어야 한다는 강제
트랜스포머 어텐션의 동작 방식을 떠올려보자. 각 토큰은 자신과 관련 있는 토큰들에 어텐션을 분배한다. 직관적으로는 관련 있으면 높은 점수, 없으면 낮은 점수를 주면 된다.
문제는 Softmax가 어텐션 가중치의 합을 반드시 1로 맞춘다는 데 있다. 시퀀스 대부분이 현재 토큰과 관련 없는 상황에서도 가중치의 합은 1이어야 하므로, 남은 가중치를 어딘가에 배분해야 한다. 그 "어딘가"가 첫 번째 토큰(BOS 토큰)이 된다.
첫 번째 토큰은 실질적 의미와 무관하게 모든 헤드에서 관련 없는 어텐션을 받아내는 "쓰레기통"이 된다. 이것이 어텐션 싱크다.
2023년 MIT와 메타의 연구(StreamingLLM)가 이 현상을 처음 체계적으로 기록했다. LLM의 KV 캐시에서 첫 번째 토큰을 제거하면 성능이 급격히 떨어지지만, 다른 토큰을 제거하면 상대적으로 성능이 유지된다는 사실이다. 첫 번째 토큰은 의미 없이 어텐션 흐름의 핵심 노드가 되어 있었다.
Qwen 팀의 측정에 따르면, 표준 Softmax 어텐션에서 첫 번째 토큰이 받는 어텐션 가중치는 평균 46.7%다. 시퀀스 전체 어텐션의 절반 가까이가 쓸모없는 토큰 하나에 몰린다.
기존 해법 세 가지: 회피, 교체, 대체
어텐션 싱크를 다루는 접근법은 크게 세 방향으로 나뉜다.
첫 번째는 회피다. StreamingLLM이 대표적이다. 싱크를 없애려 하지 않고, 예측 가능하게 통제한다. KV 캐시에 첫 번째 토큰을 항상 유지하도록 설계해 싱크 위치를 고정하는 방식이다. 기존 모델에 추론 시점에 적용할 수 있다는 실용적 장점이 있지만, 어텐션의 절반이 낭비된다는 사실 자체는 달라지지 않는다.
두 번째는 교체다. Softpick 같은 방법이 여기에 해당한다. Softmax 대신 다른 정규화 함수를 써서 합-to-1 제약을 없앤다. 싱크 문제를 원칙적으로 해결하지만, 기존 훈련된 모델과의 호환성이 사라지고 사전 훈련을 새로 시작해야 한다.
세 번째는 아키텍처 대체다. GLA(Gated Linear Attention, ICML 2024)는 Softmax 자체를 선형 커널로 바꾸면서 게이팅을 도입했다. 계산 효율이 크게 높아지지만, Softmax 어텐션과의 직접 비교가 어렵고 일부 태스크에서 성능 격차가 남는다.
자연스럽게 질문이 생긴다. Softmax를 유지한 채로 이 한계를 극복할 수 있을까?
Gated Attention: Softmax는 그대로, 게이트만 추가
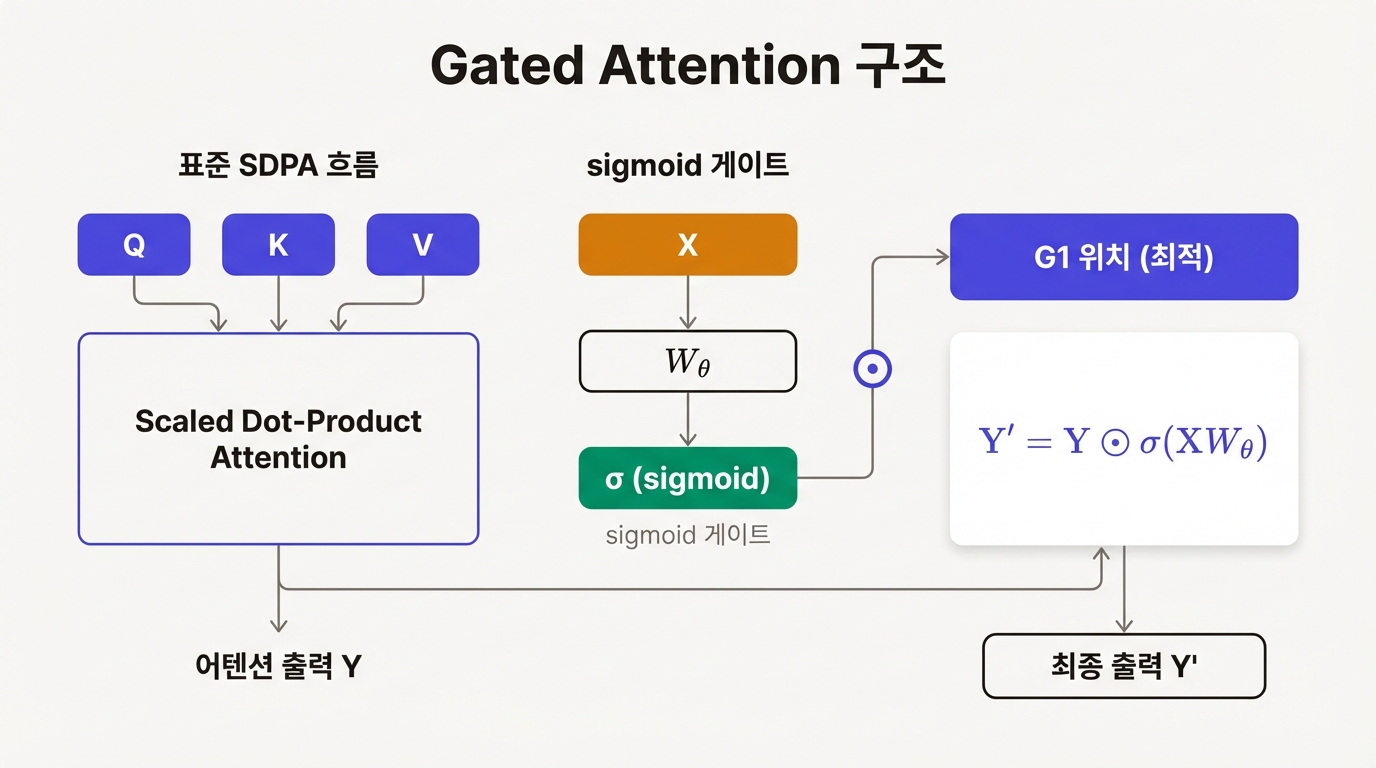
Qwen 팀의 답은 단순하다. Softmax 어텐션 출력 뒤에 sigmoid 게이트를 하나 붙이는 것이다.
Y' = Y ⊙ σ(XWθ)
각 항을 풀면 이렇다.
- Y: 표준 Scaled Dot-Product Attention의 출력. 기존 어텐션 결과 그대로다.
- σ: sigmoid 함수. 0과 1 사이 값을 출력한다.
- XWθ: 입력 X에 헤드별 선형 변환 Wθ를 적용한 결과. 각 어텐션 헤드가 자신만의 게이트 투영을 갖는다.
- ⊙: element-wise 곱셈.
직관적으로는 이렇다. 각 어텐션 헤드가 "내가 계산한 결과를 얼마나 신뢰할 것인가?"를 스스로 결정한다. 게이트 값이 1에 가까우면 출력을 그대로 통과시키고, 0에 가까우면 억제한다.
결정적인 점은 이 게이트가 쿼리에 의존한다는 것이다. 현재 처리 중인 토큰의 표현에 따라 게이트 패턴이 달라진다. 같은 어텐션 헤드라도 어떤 토큰을 처리하느냐에 따라 출력을 통과시킬지 억제할지가 바뀐다.
어디에 붙일 것인가: G1~G5 실험
Qwen 팀은 어텐션 레이어 내 다섯 위치(G1~G5)에 게이트를 삽입하는 실험을 진행했다. 결론은 G1, 즉 SDPA 직후 위치가 가장 효과적이라는 것이었다. SDPA 출력이 아직 후처리 없이 "원형"에 가까운 상태에서 게이팅이 이루어질 때 비선형성 효과가 극대화된다는 해석이 가능하지만, 논문은 이론적 증명 대신 실험적 관찰에 기댄다.
성능이 오르는 이유 두 가지
Gated Attention이 성능을 높이는 메커니즘은 두 가지로 구분된다. 논문의 ablation study는 이 두 요인이 독립적으로 기여함을 보여준다.
비선형성: 저랭크 병목 해소
Softmax 어텐션의 Value→Output 매핑은 본질적으로 저랭크 선형 변환이다. 어텐션 출력 Y는 Value 행렬의 선형 결합, 즉 softmax 가중치로 Value 벡터들을 가중 평균한 것이다. 이 연산은 선형이고, 표현할 수 있는 함수의 공간이 제한된다.
sigmoid 게이트 σ(XWθ)는 비선형이다. 이것이 Y와 element-wise로 곱해지면 전체 연산이 비선형이 된다. FFN에서 GLU나 SwiGLU를 쓰는 이유와 정확히 같은 논리다. 비선형 게이팅이 표현력을 높인다는 원리는 FFN에서 이미 검증됐고, Gated Attention은 이를 어텐션 레이어에 옮겨 온 셈이다.
희소 게이팅: 어텐션 싱크 소멸
Softmax에서 어텐션 싱크가 발생하는 이유는 관련 없는 토큰에도 가중치를 배분해야 한다는 강제성이다. sigmoid 게이트는 이 강제성을 우회한다. 게이트가 0에 가까운 값을 출력하면, 해당 헤드의 출력이 통째로 억제된다. "이 헤드의 결과가 신뢰할 수 없으니 무시하겠다"는 결정이다.
결과적으로 모델이 첫 번째 토큰에 불필요한 어텐션을 몰아야 할 이유가 없어진다. 쓸모없는 어텐션을 싱크 토큰에 집중시키는 대신, 게이트가 해당 출력 자체를 막아버리면 그만이다. 논문은 이를 "희소 게이팅(sparse gating)"이라 부른다.
실험 결과
Qwen 팀은 15B 파라미터 MoE 모델과 1.7B dense 모델의 30가지 변형을 훈련해 검증했다. 훈련 데이터는 3.5조(3.5T) 토큰이다. 이 규모의 ablation study는 학술 논문에서 흔하지 않다.
주요 결과를 정리하면 이렇다.
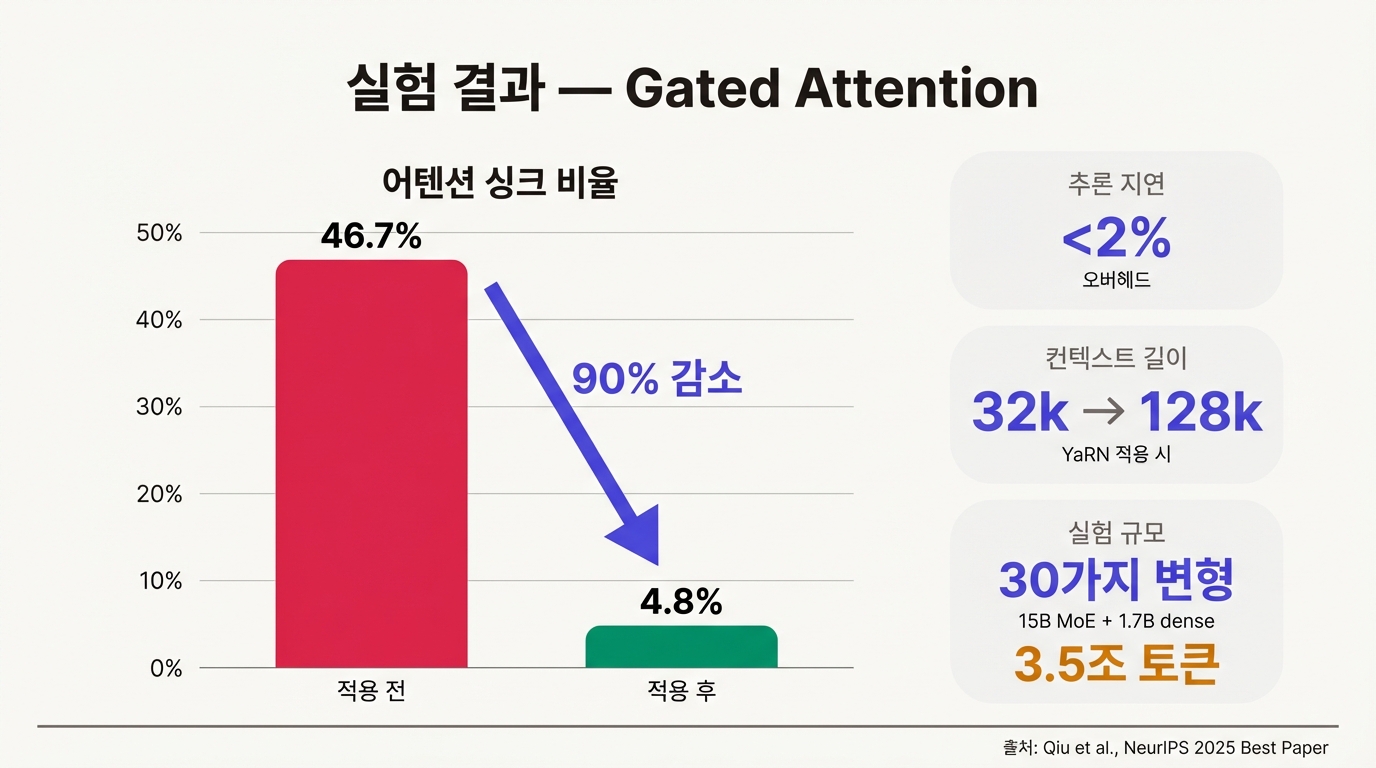
- 어텐션 싱크: 첫 번째 토큰의 어텐션 비율이 46.7% → 4.8%로 감소. 싱크 현상이 사실상 사라졌다.
- 추론 지연: 2% 미만. 게이트 연산을 위한 행렬 곱셈이 추가되지만, 전체 속도에 미치는 영향은 무시할 수 있는 수준이다.
- 장문맥: 표준 어텐션으로 훈련된 모델을 YaRN으로 컨텍스트 확장할 때 32k가 한계였으나, Gated Attention 적용 후 128k까지 안정적으로 동작했다.
- 훈련 안정성: Gated Attention 모델은 더 높은 학습률에서도 안정적으로 훈련됐다. 이는 실제 훈련 비용 절감 가능성을 시사한다.
헤드별 하나의 게이트 벡터를 쓰는 headwise gating과 원소별로 게이트를 다르게 하는 elementwise gating 두 방식을 모두 테스트했으며, 성능 차이는 크지 않았다.
Qwen3-Next-80B: 실전 배포
실험실 결과에 그치지 않는다. Qwen 팀은 이 방식을 플래그십 모델에 직접 적용했다.
2025년 9월 출시된 Qwen3-Next-80B-A3B는 Gated DeltaNet과 Gated Attention을 3:1 비율로 혼합한 하이브리드 아키텍처를 사용한다. 80B 파라미터, 3B active parameter의 MoE 모델이며 1M 토큰 컨텍스트 윈도우를 지원한다.
3:1 비율은 흥미로운 수치다. Gated DeltaNet(선형 어텐션 계열)이 주를 이루고, Softmax 기반 Gated Attention이 4분의 1을 차지한다. 이 비율이 어떻게 결정됐는지, 태스크나 모델 크기에 따라 달라지는지는 아직 열린 질문이다.
1M 토큰 컨텍스트가 가능하다는 사실은 128k 실험 결과가 프로덕션 스케일로 실제로 이어졌다는 증거다.
남은 질문들
강력한 실험 결과에도 불구하고, 논문이 답하지 않은 부분이 있다.
파라미터 공정성 문제: Wθ 행렬이 추가되므로 파라미터 수가 늘어난다. 동일한 파라미터 예산 하에서 모델 용량을 다른 방식으로 늘리는 것과 비교했을 때도 Gated Attention이 우월한지는 확인되지 않았다.
파인튜닝 비용 미평가: 사전 훈련에서의 이점은 명확하지만, 기존에 훈련된 모델을 Gated Attention으로 추가 훈련할 때의 비용과 효과는 분석되지 않았다.
G1 위치의 이론적 근거 부재: SDPA 직후 위치가 최적이라는 것은 실험으로 확인됐지만, 왜 그런지에 대한 이론적 설명은 없다. 사후 관찰에 그친다.
어텐션 싱크의 부수 효과: 싱크 현상이 100% 해롭기만 한지는 사실 불명확하다. "관련 없는 모든 것을 첫 번째 토큰에 모으는" 동작이 모델이 어떤 정보를 암묵적으로 저장하는 메커니즘으로 기능했을 가능성이 있다. 특히 RAG처럼 관련 없는 컨텍스트가 많은 설정에서 싱크 감소가 실제로 도움이 되는지, 아니면 오히려 성능을 떨어뜨리는지는 탐구되지 않았다.
게이팅의 계보: 1997년부터 2025년까지
Gated Attention은 갑자기 등장한 아이디어가 아니다. 딥러닝에서 게이팅 메커니즘의 역사는 길다.
LSTM(1997)이 입력·망각·출력 게이트로 시퀀스 모델에 게이팅을 도입했다. Highway Networks(2015)는 피드포워드 네트워크에 게이트를 적용했다. GLU(2017)는 언어 모델 FFN에 게이팅을 도입해 성능을 높였고, SwiGLU(2021)는 GLU를 Swish 활성화와 결합해 PaLM, LLaMA 등 현대 LLM의 표준이 됐다. GLA(ICML 2024)는 선형 어텐션에 게이팅을 도입했다.
그리고 Gated Attention(NeurIPS 2025)은 Softmax 어텐션에 게이팅을 적용했다. FFN에서 이미 표준이 된 원리가 어텐션에는 왜 이제야 도달했는가. 이 질문 자체가 이 논문의 위치를 설명한다.
세미나에서 던질 질문 3개
-
파라미터 공정성: Gated Attention은 Wθ 파라미터가 추가된다. 동일한 파라미터 예산 하에서 Gated Attention 대신 모델 용량을 다른 방식으로 늘리는 것과 비교했을 때도 Gated Attention이 우월한가?
-
싱크의 역할: 어텐션 싱크는 정말 순수하게 해로운가? "관련 없는 모든 것을 첫 번째 토큰으로 모으는" 동작이 모델이 어떤 정보를 저장하는 암묵적 메커니즘으로 기능했을 가능성은 없는가?
-
하이브리드 비율: Qwen3-Next가 3:1(DeltaNet:Attention) 비율을 선택했는데, 이 비율을 어떻게 결정했는가? 태스크 유형이나 모델 크기에 따라 최적 비율이 달라지는가?
관련 논문
- Gu & Dao, "Mamba: Linear-Time Sequence Modeling with Selective State Spaces" (ICLR 2024), SSM 기반 대안 아키텍처
- Sun et al., "Retentive Network: A Successor to Transformer for Large Language Models" (2023), Retention 메커니즘과 게이팅
- Yang et al., "Gated Linear Attention Transformers with Hardware-Efficient Training" (ICML 2024), GLA, Gated Attention의 직접적 선행 연구
- Xiao et al., "Efficient Streaming Language Models with Attention Sinks" (ICLR 2024), StreamingLLM, 어텐션 싱크 현상 발견
출처
- Qiu et al., "Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free," NeurIPS 2025 (Oral, Best Paper Award). arXiv:2505.06708
- Xiao et al., "Efficient Streaming Language Models with Attention Sinks," ICLR 2024
- Yang et al., "Gated Linear Attention Transformers with Hardware-Efficient Training," ICML 2024
- Dauphin et al., "Language Modeling with Gated Convolutional Networks," ICML 2017 (GLU)