원문: Differential Transformer | ICLR 2025 Oral | Microsoft Research
어텐션 노이즈, Transformer의 오래된 약점
Transformer의 self-attention은 모든 토큰에 softmax로 가중치를 매긴다. 그런데 softmax 출력의 합은 반드시 1이어야 하므로, 무관한 토큰에도 가중치가 분배될 수밖에 없다. 이른바 "어텐션 노이즈"다.
이 노이즈가 쌓이면 어떻게 될까. 모델이 긴 문맥에서 핵심 정보를 놓치고, 없는 내용을 지어내며(hallucination), 양자화 시 성능이 급락한다. 2023년 MIT Han Lab이 발견한 "attention sink" 현상(첫 번째 토큰에 의미 없이 어텐션이 몰리는 문제)도 같은 뿌리에서 비롯된다.
Microsoft Research의 Furu Wei 그룹이 제안한 Differential Transformer는 이 문제에 간결한 해법을 내놓았다. 어텐션 맵을 두 장 만든 뒤 빼는 것이다. 노이즈 캔슬링 헤드폰이 주변 소음의 역위상 파형을 만들어 상쇄하는 것과 같은 원리다. ICLR 2025 Oral로 선정됐고, V2까지 발표되어 실제 대규모 LLM 학습에 적용되고 있다.
Softmax 어텐션의 구조적 한계
Transformer의 표준 어텐션은 Query와 Key의 내적을 구한 뒤 softmax를 씌워 확률 분포로 만들고, 이를 가중치 삼아 Value를 합산한다.
softmax 출력은 모든 원소가 양수이고 합이 1이다. 바로 이 성질이 문제의 근원이다. 현재 Query와 전혀 무관한 토큰이라도 가중치가 정확히 0이 될 수 없다. 토큰 수가 늘어날수록 이 "잔여 가중치"가 누적되고, 정작 중요한 토큰의 어텐션이 희석된다.
실험 수치가 이를 뒷받침한다. 표준 Transformer 3B 모델에서 정답 구간에 할당되는 어텐션은 평균 0.03에 불과한 반면, 무관한 맥락에 0.51이 분산된다. 어텐션의 절반 이상이 노이즈인 셈이다.
이 구조적 제약은 여러 후속 문제로 이어진다. 긴 문맥에서 "바늘 찾기(needle-in-a-haystack)" 정확도가 떨어지고, 요약 시 원문에 없는 내용을 만들어내며, 활성화 값에 극단적 아웃라이어가 생겨 양자화 효율이 나빠진다.
Differential Attention: 빼기의 힘
해법의 핵심은 한 줄로 요약된다.
DiffAttn(X) = (softmax(Q₁K₁ᵀ/√d) − λ · softmax(Q₂K₂ᵀ/√d)) V
Query와 Key를 각각 두 그룹(Q₁, K₁과 Q₂, K₂)으로 나눈다. 각 그룹으로 독립적인 softmax 어텐션 맵을 계산한 뒤, 두 번째 맵에 학습 가능한 계수 λ를 곱하고 첫 번째 맵에서 뺀다. 이 차이값이 최종 어텐션 점수가 된다.
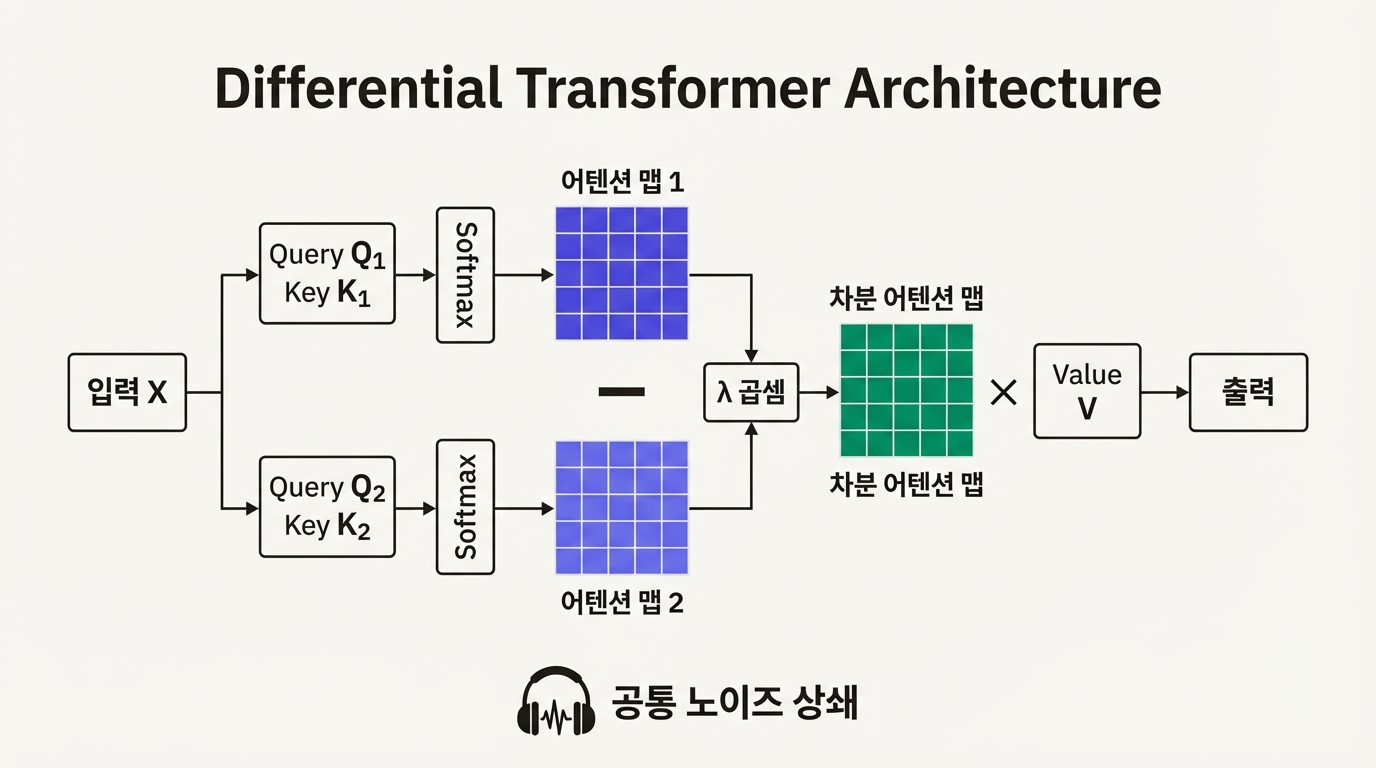
전자공학의 차동 증폭기(differential amplifier)를 떠올리면 직관적이다. 차동 증폭기는 두 입력 신호의 차이만 증폭하고 공통 모드 노이즈는 상쇄한다. Differential Attention도 마찬가지다. 두 어텐션 맵이 공유하는 "배경 노이즈"(무관한 토큰에 분산되는 잔여 가중치)는 빼기 연산으로 사라지고, 실제로 의미 있는 토큰에 집중된 신호만 남는다.
결과적으로 어텐션 분포가 희소(sparse)해진다. 무관한 토큰의 가중치가 0 근처로 떨어지면서, 모델이 정말 중요한 정보에 리소스를 집중할 수 있게 된다.
λ의 역할과 학습
계수 λ는 노이즈 상쇄의 강도를 조절하는 다이얼이다. V1에서는 레이어별로 다른 초기값을 설정했다.
λ_init = 0.8 − 0.6 × exp(−0.3 × (l−1))
초기 레이어(l이 작을 때)에서는 λ가 작아 상쇄를 약하게 하고, 깊은 레이어로 갈수록 λ가 커져 노이즈 제거를 강화한다. 학습 과정에서 각 레이어가 자체적으로 최적의 λ를 찾아간다. 흥미로운 점은 λ_init을 0.5로 설정하든 0.8로 설정하든 최종 성능 차이가 미미하다는 것이다(validation loss 3.065 vs 3.066). 모델이 스스로 적절한 균형점을 찾는다.
파라미터 효율성
Differential Attention은 헤드 수를 절반으로 줄여 사용한다. 표준 Transformer가 24개 헤드를 쓸 때 Diff Transformer는 12개 헤드를 쓴다. 각 헤드가 내부적으로 두 세트의 Q, K를 갖기 때문에 전체 파라미터 수와 연산량(FLOP)은 거의 동일하게 유지된다.
실험 결과
저자들은 830M부터 13.1B까지 다양한 크기의 모델을 학습시켜 체계적으로 검증했다.
스케일링 효율
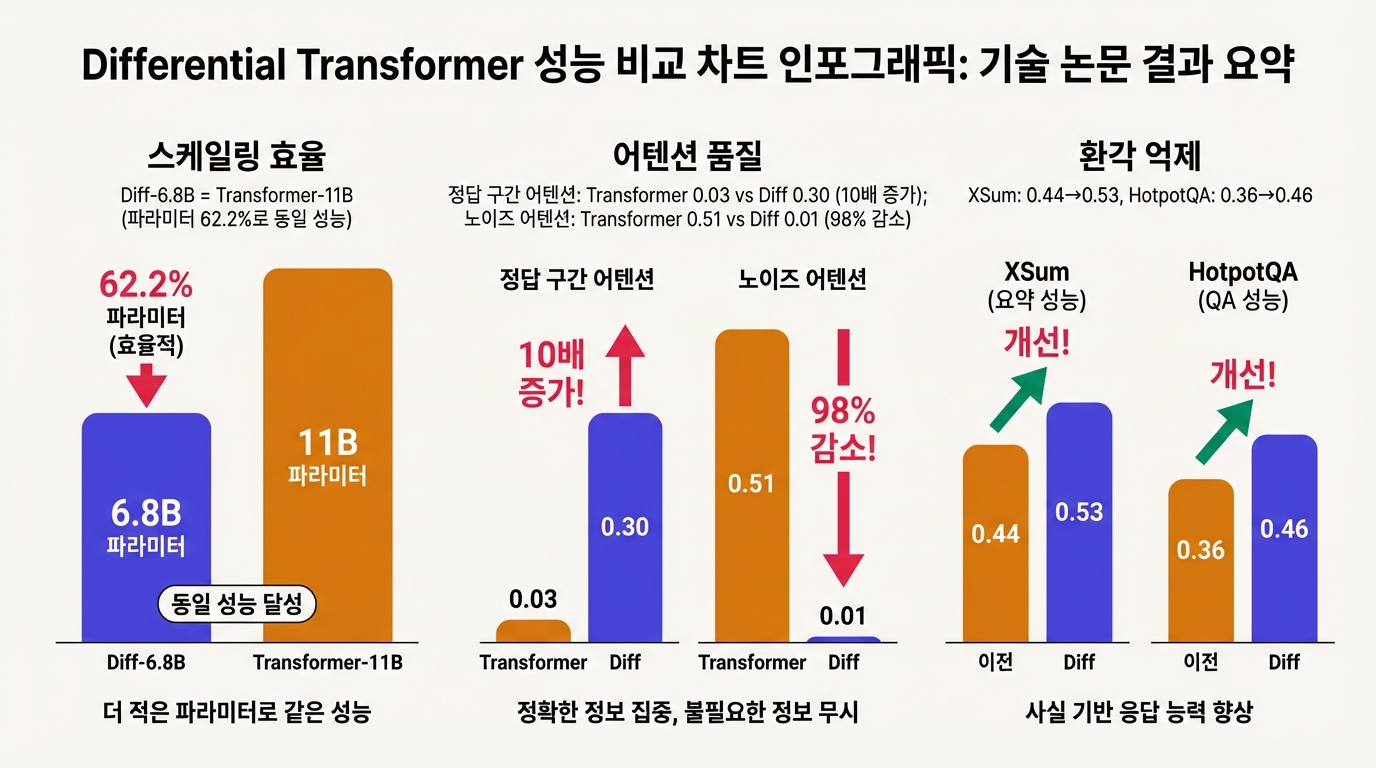
가장 눈에 띄는 결과는 스케일링 곡선에서 나온다. Diff-6.8B 모델이 표준 Transformer 11B 모델과 동일한 성능을 달성했다. 같은 성능을 62.2%의 파라미터로 도달한 것이다. 학습 토큰 관점에서도 Diff Transformer가 160B 토큰으로 달성하는 loss를 표준 Transformer는 251B 토큰에서야 도달했다. 학습 데이터를 36%가량 절약할 수 있다는 뜻이다.
정보 검색과 어텐션 품질
needle-in-a-haystack 실험에서 차이가 극명하다. 4K 문맥에 바늘 6개를 숨기고 2개를 찾아야 하는 세팅에서, 표준 Transformer의 정확도는 0.55인 반면 Diff Transformer는 0.85를 기록했다. 어텐션 맵을 직접 분석하면 이유가 보인다. 정답 구간에 할당되는 어텐션이 0.03에서 0.30으로 10배 증가하고, 무관한 맥락의 어텐션은 0.51에서 0.01로 급감한다.
환각 억제
텍스트 요약과 질의응답에서의 환각(hallucination) 실험도 주목할 만하다. XSum 요약에서 사실 정확도가 0.44에서 0.53으로, HotpotQA에서 0.36에서 0.46으로 올랐다. 어텐션 노이즈가 줄면서 모델이 "실제로 본 것"에 더 충실해진 결과다.
활성화 아웃라이어 감소
양자화 친화성도 크게 개선됐다. 어텐션 로짓의 최댓값이 318.0에서 38.8로 87.8% 줄었다. 이 덕분에 4비트 양자화된 Diff Transformer가 표준 Transformer의 6비트 양자화 성능과 맞먹는다. 실제 배포 환경에서 메모리 절약 효과가 크다.
비용: 처리량 감소
물론 공짜는 없다. 두 번의 softmax 연산과 빼기 연산이 추가되어 처리량이 5~12% 줄어든다. 3B 모델 기준으로 초당 6,635 토큰 대 7,247 토큰이다. 다만 FlashAttention-3 최적화로 격차를 줄일 수 있고, V2에서는 이 문제가 대부분 해결됐다.
V2로의 진화
2026년 1월, 같은 연구팀이 Differential Transformer V2를 발표했다. 대규모 학습에 적용하면서 드러난 세 가지 실전 문제를 해결한다.
첫째, V1은 커스텀 어텐션 커널이 필요했다. V2는 Query 헤드 수를 2배로 늘리는 대신 KV 헤드 수는 유지하여 표준 FlashAttention을 그대로 쓸 수 있다. LLM 디코딩은 메모리 바운드이므로 Query 헤드가 늘어도 디코딩 속도는 표준 Transformer와 동일하다.
둘째, V1의 헤드별 RMSNorm이 대규모 학습에서 불안정을 일으켰다. 시퀀스 길이 8192 기준으로 약 100배의 그래디언트 증폭이 발생했다. V2는 이 정규화를 제거하고 λ를 sigmoid로 간소화하여 안정성을 확보했다.
셋째, softmax의 RMS 바운드가 [1/√n, 1)에서 (0, √2)로 확장됐다. 하한이 0이 되면서 attention sink 현상 자체가 원리적으로 사라진다. 같은 시기 발표된 Gated Attention 논문이 다루는 문제를 다른 각도에서 해결한 것이다.
같은 문제, 다른 접근
self-attention의 구조적 한계를 극복하려는 시도는 Differential Transformer만이 아니다.
Gated Attention(Qiu et al., NeurIPS 2025)은 softmax 출력에 sigmoid 게이트를 곱하는 방식을 택했다. 곱셈으로 불필요한 어텐션을 억제한다는 점에서, 뺄셈으로 노이즈를 상쇄하는 Differential Attention과 접근이 다르다. 두 논문 모두 softmax의 "합이 1" 제약에서 벗어나려 한다는 점에서 같은 문제를 바라보고 있다.
Mamba와 같은 State Space Model은 아예 어텐션을 쓰지 않는다. 선형 시간 복잡도로 시퀀스를 처리하는 대안 아키텍처다. Jamba처럼 SSM과 어텐션 레이어를 3:1 비율로 섞는 하이브리드 접근도 활발히 연구되고 있다.
Grouped Differential Attention(2025년 10월)은 Diff Transformer의 후속 연구로, 신호 추출 헤드와 노이즈 제어 헤드의 비율을 3:1이나 4:1로 비대칭 배분하면 성능이 더 올라간다는 것을 보여줬다.
논문에 던질 질문 3개
1. 빼기 연산은 어텐션의 표현력을 제한하지 않을까? 두 softmax 맵의 차이를 쓰면 음수 어텐션 가중치가 가능해진다. 표현력 확장일 수도 있고, 학습을 불안정하게 만드는 요인일 수도 있다. λ 값이 1을 넘으면 첫 번째 맵의 기여보다 두 번째 맵의 기여가 커지는데, 이때 모델이 어떻게 동작하는지는 추가 분석이 필요하다.
2. Differential Attention과 Gated Attention을 결합하면? 빼기(Diff)와 곱하기(Gate) 모두 softmax의 제약을 완화하는 방법이다. 결합하면 시너지가 날 수도 있고 중복될 수도 있다. V2의 설계가 Gated Attention과 점점 수렴하고 있다는 점이 흥미롭다.
3. SSM 하이브리드에서 Differential Attention의 역할은? Jamba 같은 하이브리드 모델에서 소수의 어텐션 레이어가 담당하는 역할은 장거리 의존성 포착이다. 이 레이어에 Differential Attention을 적용하면, 적은 수의 어텐션 레이어로도 더 정밀한 정보 검색이 가능할 수 있다.
추가로 읽으면 좋은 논문:
- Efficient Streaming Language Models with Attention Sinks (Xiao et al., ICLR 2024), attention sink 현상의 최초 체계적 분석
- Gated Attention for Large Language Models (Qiu et al., NeurIPS 2025), 곱셈 기반 어텐션 노이즈 억제
- Grouped Differential Attention (2025), Diff Transformer의 헤드 비율 최적화 후속 연구
출처
- Ye, T., Dong, L., Xia, Y., Sun, Y., Zhu, Y., Huang, G., & Wei, F. (2025). Differential Transformer. ICLR 2025 Oral. arXiv:2410.05258
- Ye, T., Dong, L., Sun, Y., & Wei, F. (2026). Differential Transformer V2. Microsoft Research Blog.
- Xiao, G., Tian, Y., Chen, B., Han, S., & Lewis, M. (2024). Efficient Streaming Language Models with Attention Sinks. ICLR 2024.
- Qiu, Z., Wang, Z., Zheng, B., Wen, K., Yang, S., & Lin, J. (2025). Gated Attention for Large Language Models. NeurIPS 2025.
- Grouped Differential Attention. (2025). arXiv:2510.06949