문제의 출발점
DeepSeek-R1이 수학 추론에서 인상적인 성적을 거둔 뒤, Reinforcement Finetuning(RFT)은 LLM 훈련의 핵심 도구가 되었다. OpenAI도 자체 RFT를 도입했고, GRPO와 DAPO 같은 알고리즘이 빠르게 퍼지고 있다.
그런데 불편한 사실이 하나 있다. RFT로 추론 능력을 끌어올린 모델일수록 모르는 문제 앞에서도 자신만만하게 틀린 답을 내놓는다. 수학 점수가 오르면 hallucination도 따라 오른다. 추론 능력과 신뢰성이 반비례한다.
UT Austin의 Amy Zhang 연구팀은 이 현상의 원인을 짚어낸 뒤, loss function의 정규화 항 하나를 바꾸는 것만으로 해법을 내놨다. 그것이 CARE-RFT다.
RFT는 왜 신뢰성을 깎아먹나
RFT의 흐름
LLM 정렬 기법은 RLHF에서 출발해 PPO, DPO를 거쳐 GRPO로 이어져 왔다. GRPO(Group Relative Policy Optimization)는 별도의 critic model 없이 그룹 안에서 상대적 보상만으로 정책을 갱신한다. DeepSeek-R1의 핵심 훈련 기법이기도 하다. 이런 흐름을 통칭해 RFT라 부른다.
신뢰성이 무너지는 두 가지 경로
CARE-RFT 논문은 기존 RFT의 실패 지점을 두 갈래로 나눠 분석한다.
무차별 강화(Indiscriminate Reinforcement). 최종 답이 맞으면 중간 추론 과정 전체에 보상이 간다. 문제는 중간에 오류가 끼어 있어도 마찬가지라는 점이다. 잘못된 공식을 적용했는데 운 좋게 답이 맞았다면, 그 잘못된 단계까지 강화된다. 모델은 "틀린 근거로도 당당하게 답하는" 습관을 들이게 된다.
무차별 처벌(Indiscriminate Penalization). 반대로 최종 답이 틀리면 전체 과정에 패널티가 떨어진다. 중간에 올바른 추론 단계가 있었어도 함께 약해진다. base model이 원래 갖고 있던 "모르겠다"고 판단하는 능력, 즉 self-awareness가 여기서 깎여 나간다.
이 현상은 "Hallucination Tax of RFT"(arXiv: 2505.13988)에서도 독립적으로 보고되었다. 해당 연구는 훈련 데이터에 답할 수 없는 문제를 10% 섞는 데이터 차원의 해법을 제안했고, CARE-RFT는 알고리즘 차원에서 접근한다는 점이 다르다.
핵심 아이디어: 벌금에 천장을 달다
기존 방식: 끝없이 불어나는 패널티
GRPO 같은 RFT 알고리즘은 모델이 원래 정책(reference model)에서 너무 멀어지지 않도록 Reverse KL divergence를 정규화 항으로 쓴다. "원래 모델이 거의 쓰지 않던 토큰을 새 모델이 자주 쓰려 하면 패널티를 준다"는 장치다.
문제는 이 패널티에 상한이 없다는 데 있다. reference model이 확률을 거의 0으로 매긴 토큰을 새 모델이 쓰려 하면, 패널티는 무한대로 치솟는다. 모델은 reference model이 이미 아는 패턴만 되풀이하게 되고, 새로운 추론 경로를 탐색하지 못한다.
CARE-RFT의 해법: Skew Reverse KL
CARE-RFT는 정규화 항을 Skew Reverse KL divergence로 바꾼다. 바뀌는 부분은 간단하다. 패널티를 계산할 때 분모에 reference model만 넣지 않고, 현재 모델 자신의 확률도 일정 비율로 섞는다.
수식 박스
- 표준 Reverse KL: KL(π_θ ∥ π_ref), 분모가 π_ref만
- Skew Reverse KL: 분모가 α·π_θ + (1-α)·π_ref, 현재 모델 π_θ를 α 비율로 혼합
- 패널티 상한: log(1/α). α=0.8이면 최대 패널티 ≈ 0.22
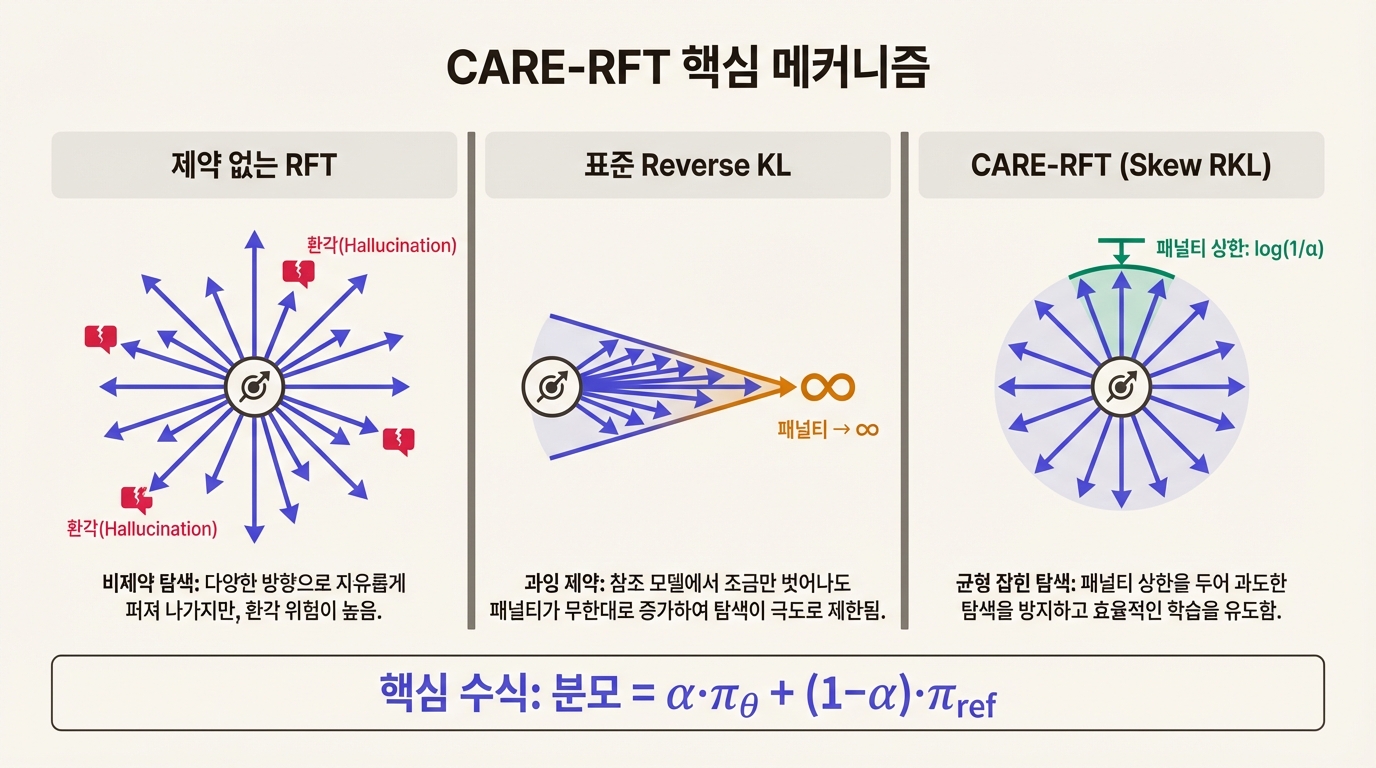
비유하면 이렇다. 기존 방식은 원래 길에서 벗어날수록 벌금이 기하급수적으로 불어나는 규칙이다. 새 길을 시도하는 것 자체가 억제된다. Skew Reverse KL은 벌금에 천장이 있는 규칙이다. 어느 정도까지는 새 길을 탐색하되, 완전히 엉뚱한 곳으로 빠지는 건 막아준다.
α가 이 천장의 높이를 결정한다. α가 클수록 천장이 낮아져서(패널티 상한이 작아져서) 탐색 여지가 넓어진다. 논문에서는 α=0.8이 최적이었다.
흥미로운 건 α가 고정값인데도 "confidence-adaptive"한 효과가 수학적으로 저절로 생긴다는 점이다. 모델이 특정 토큰에 높은 확률을 부여할수록 분모의 π_θ 항이 커지면서 패널티가 자동으로 줄어든다. 별도의 confidence estimator 없이도 확신이 강한 토큰에는 관대하고, 불확실한 토큰에는 엄격한 구조가 만들어진다.
기존 코드에 바로 적용 가능하다
CARE-RFT의 실용적 장점은 기존 RFT 파이프라인에 drop-in replacement로 들어간다는 것이다. KL 정규화 항만 교체하면 된다. 논문은 GRPO, DAPO, GSPO 세 알고리즘 모두에서 동일한 방식으로 적용되는 것을 실험으로 확인했다.
실험 결과
Qwen2.5-3B에 GRPO를 적용한 실험이 핵심 비교 대상이다.
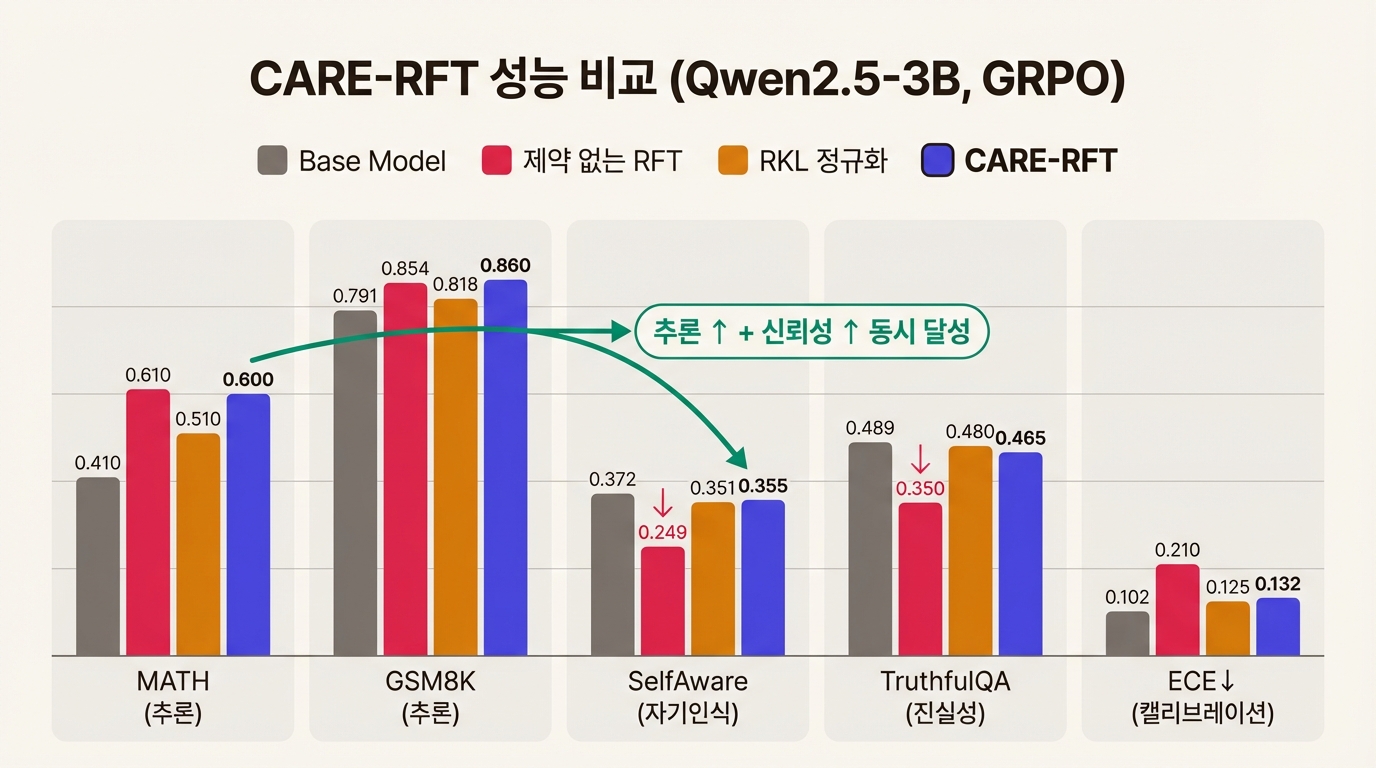
제약 없는 RFT는 MATH 정확도를 0.410에서 0.610으로 끌어올린다. 그 대가가 크다. SelfAware가 0.372에서 0.249로 떨어지고, TruthfulQA도 0.489에서 0.350으로 추락한다. 추론 점수를 올리는 만큼 신뢰성이 깎여 나간 셈이다.
표준 RKL 정규화를 걸면 신뢰성은 어느 정도 회복되지만, MATH가 0.510까지 내려앉는다. 추론 성능을 상당 부분 반납해야 한다.
CARE-RFT는 MATH 0.600을 유지하면서 SelfAware와 TruthfulQA를 base model에 근접한 수준으로 지켜낸다. 추론과 신뢰성 사이에서 양보 폭을 크게 줄인 것이다.
7B 모델에서는 격차가 더 벌어진다. GSPO에 CARE-RFT를 적용했을 때 MATH가 0.498에서 0.776으로 55.8% 상승하면서도 캘리브레이션 오차(ECE)는 0.089에서 0.101로 거의 움직이지 않았다.
α에 따른 ablation 결과도 직관적이다. α=0.0(표준 RKL과 동일)일 때 MATH 0.510, α=0.4에서 0.562, α=0.8에서 0.600으로 최적, α=0.9에서는 0.592로 소폭 내려간다. 정규화가 너무 느슨해지면 탐색 이득이 줄어드는 구간이 나타나는 것이다.
아쉬운 점과 열린 질문
수학 밖에서도 통할까. 실험이 전부 MATH와 GSM8K, 즉 수학 추론 태스크에서 이루어졌다. 코드 생성이나 논리 추론, 자연어 추론에서도 같은 효과가 나는지는 아직 모른다. 수학은 정답이 명확하고 보상 신호가 깨끗한 편이라 보상이 noisy한 태스크에서는 α의 최적값이나 효과 자체가 달라질 수 있다.
검증한 모델이 Qwen2.5뿐이다. 3B와 7B 두 사이즈에서만 실험했다. LLaMA, Mistral 등 다른 아키텍처에서의 재현 결과가 없다. 아키텍처마다 base model의 확률 분포 특성이 다르므로 Skew RKL의 효과도 달라질 수 있다.
α 하이퍼파라미터의 범용성. α=0.8이 두 모델 크기와 세 알고리즘에서 일관되게 좋았다는 점은 긍정적이다. 다만 도메인이 바뀌면 재튜닝이 필요할 수 있다고 논문도 인정한다. α를 학습 가능한 파라미터로 만들거나 MC dropout, ensemble 기반 confidence estimation과 결합하는 방향이 자연스러운 후속 연구가 된다.
데이터 해법과 결합하면 어떨까. "Hallucination Tax" 논문의 데이터 보강(답할 수 없는 문제 10% 혼합)과 CARE-RFT의 알고리즘 해법은 서로 직교하는 접근이다. 둘을 합치면 시너지가 날 법하지만, 아직 그 실험은 없다.
학회 수용 이력. 이 논문은 ICLR 2026에서 reject된 뒤 AISTATS 2026에 재투고되어 수용되었다. 리뷰어의 구체적 우려는 공개되지 않았으나 위에서 짚은 일반화 범위의 한계가 영향을 미쳤을 가능성이 높다.
이 논문이 중요한 이유
RFT가 LLM 추론 강화의 표준 기법으로 자리 잡은 지금, 추론과 신뢰성 사이의 트레이드오프는 실전 배포의 걸림돌이다. 의료나 법률처럼 hallucination 비용이 큰 도메인에서는 특히 그렇다.
CARE-RFT는 loss function의 정규화 항 하나를 바꾸는 것만으로 이 트레이드오프를 크게 줄인다. 기존 코드에 최소한의 수정으로 적용할 수 있어서 쓰지 않을 이유를 찾기 어려운 안전장치다. 알고리즘 수준의 신뢰성 보장이 RFT 파이프라인의 기본 구성 요소로 자리 잡을 수 있음을 보여준 연구다.
이 논문에서 던질 질문 3개
-
α를 명시적 confidence estimation과 결합해야 하나? α는 고정 하이퍼파라미터다. MC dropout이나 ensemble로 토큰별 confidence를 추정해 동적으로 조절하면 성능이 더 오를까, 아니면 추가 복잡성 대비 효과가 미미할까?
-
데이터 해법과 알고리즘 해법을 합치면? "Hallucination Tax"의 데이터 보강(답할 수 없는 문제 10% 혼합)과 CARE-RFT의 Skew RKL을 동시에 적용했을 때, 시너지가 날까 아니면 중복 효과에 그칠까?
-
추론-신뢰성 트레이드오프는 근본적 한계인가? 이 트레이드오프가 RFT 최적화 경로의 문제여서 해법이 존재하는 건지, 정보 이론적으로 불가피한 제약인지?
관련 논문
- Hallucination Tax of Reinforcement Finetuning (arXiv: 2505.13988), 데이터 수준에서 RFT 신뢰성 문제를 다룬 연구
- Rethinking KL Regularization in RLHF (arXiv: 2510.01555), KL 정규화의 이론적 분석
- Beyond Reverse KL: Generalizing Direct Preference Optimization with Diverse Divergence Constraints (OpenReview), f-divergence 프레임워크로 정규화 일반화