원문: Recursive Language Models | arXiv 2025 | Alex L. Zhang, Tim Kraska, Omar Khattab
왜 이 논문이 중요한가
LLM의 컨텍스트 윈도우는 꾸준히 늘어왔다. GPT-4의 128K, Claude의 200K, Gemini의 1M 토큰. 그런데 윈도우가 커진다고 문제가 해결되는 건 아니다. 컨텍스트가 길어질수록 모델은 중간 정보를 놓치고(Lost in the Middle), 관련 없는 내용에 주의가 분산되며, 추론 정확도가 떨어진다. 이른바 "컨텍스트 부패(context rot)" 현상이다.
기존 접근은 두 갈래였다. 하나는 아키텍처를 바꿔 더 긴 컨텍스트를 직접 처리하는 방법. 다른 하나는 RAG처럼 외부 검색으로 필요한 정보만 가져오는 방법. 두 방법 모두 한계가 뚜렷하다. 아키텍처 변경은 재학습이 필요하고, RAG는 "어떤 정보가 필요한지"를 미리 알아야 한다.
MIT의 Alex Zhang, Tim Kraska, Omar Khattab(DSPy 창시자)이 제안한 Recursive Language Models(RLM)은 전혀 다른 발상에서 출발한다. 프롬프트 전체를 모델의 컨텍스트 윈도우에 넣는 대신, 파이썬 변수로 저장한다. 모델은 코드를 작성해 그 변수를 탐색하고, 필요한 부분만 잘라서 자기 자신을 재귀적으로 호출한다. 마치 프로그래머가 거대한 로그 파일을 grep과 분할 정복으로 분석하듯이.
결과는 놀랍다. RLM은 모델 컨텍스트 윈도우의 100배를 넘는 입력도 처리하며, 1,000개 문서에서의 멀티홉 추론에서 100% 정확도를 달성했다. 기존 방법들이 모두 실패한 규모다.
기존 장문 처리의 딜레마
LLM에 긴 문서를 처리시키는 기존 방법들을 정리하면 이렇다.
첫째, 컨텍스트 윈도우 확장. RoPE 스케일링이나 LongRoPE 같은 기법으로 모델이 처리할 수 있는 토큰 수 자체를 늘린다. 하지만 윈도우를 아무리 키워도 컨텍스트 부패 문제는 남는다. 10만 토큰짜리 문서에서 핵심 문장 하나를 찾는 작업을 생각해 보자. 모델은 전체를 "읽지만", 중간에 묻힌 정보를 놓칠 확률이 높다.
둘째, 검색 증강 생성(RAG). 질문과 관련된 문서 조각만 벡터 검색으로 가져온다. 효율적이지만, 여러 문서에 흩어진 정보를 종합해야 하는 멀티홉 추론에는 약하다. "A 회사의 2024년 매출이 B 회사보다 높은 분기는?"과 같은 질문은 단순 검색으로 답하기 어렵다.
셋째, 요약 기반 압축. 긴 컨텍스트를 작은 모델로 요약한 뒤 본 모델에 전달한다. 정보 손실이 불가피하다. 요약 과정에서 나중에 중요해질 세부사항이 잘려 나갈 수 있다.
RLM의 저자들은 이 세 가지 접근 모두 공통된 가정을 갖고 있다고 지적한다. 컨텍스트를 모델의 입력으로 "넣어야 한다"는 가정이다. RLM은 이 가정 자체를 뒤집는다.
RLM이 제안하는 방법
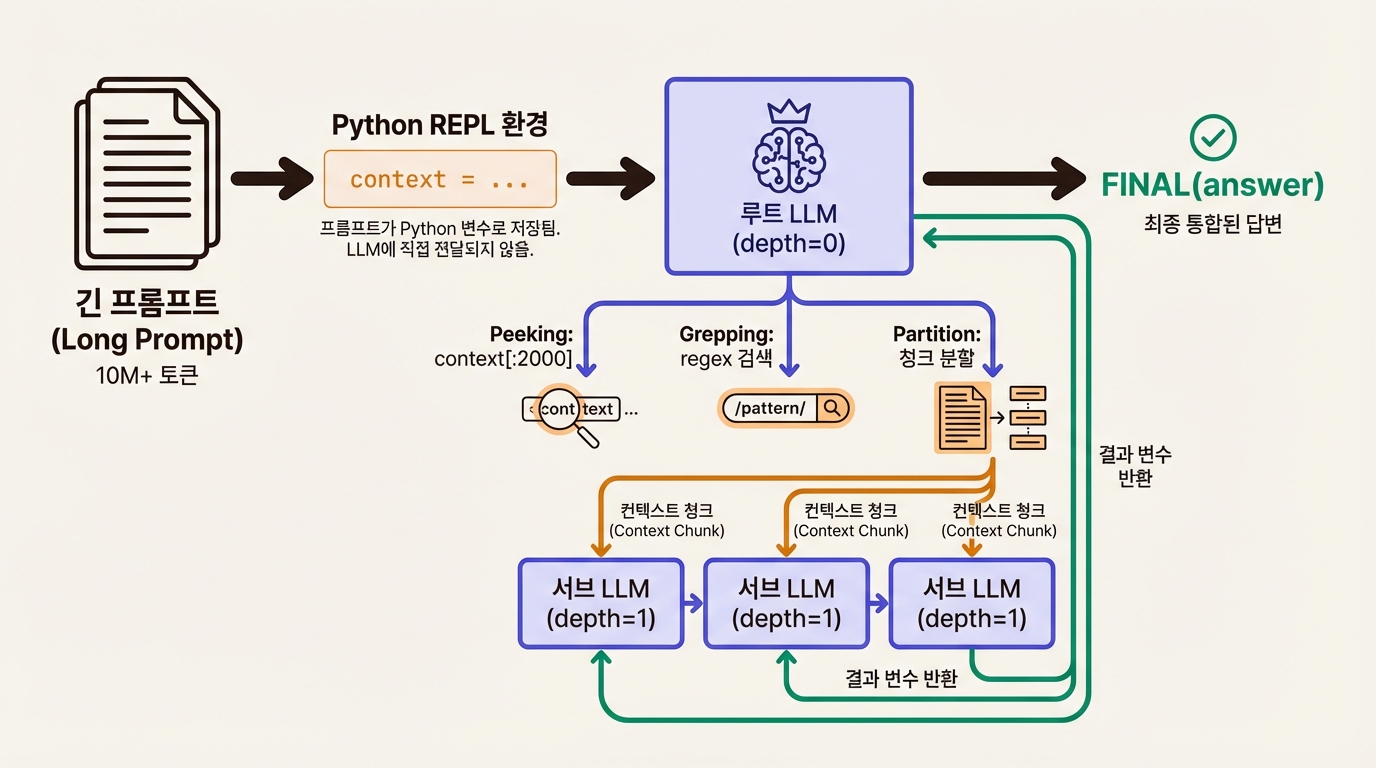
RLM의 핵심 아이디어는 단순하다. 프롬프트를 모델에 직접 넣지 않고, 파이썬 REPL 환경의 변수로 저장한다. 모델은 이 변수의 메타데이터(길이, 앞부분 미리보기, 접근 함수)만 받는다. 그리고 코드를 작성하여 컨텍스트를 탐색한다.
구체적으로 세 가지 설계 원칙이 있다.
원칙 1: 심볼릭 핸들. 프롬프트는 context라는 파이썬 변수에 담긴다. 모델은 전체 내용을 보지 않고, context[:2000]처럼 필요한 부분만 열람한다. 이렇게 하면 루트 LLM의 컨텍스트 윈도우 사용량이 천천히 늘어난다.
원칙 2: 무한 출력. 응답도 REPL의 변수로 구성한다. 모델의 출력 길이 제한에 걸리지 않으므로, 코드 생성이나 긴 분석 결과도 자유롭게 만들 수 있다.
원칙 3: 심볼릭 재귀. 핵심 중의 핵심이다. 모델이 REPL 안에서 llm_call(query, context_subset) 함수를 호출할 수 있다. 이 호출은 새로운 LLM 인스턴스를 생성하여, 원래 컨텍스트의 일부분만 갖고 동일한 방식으로 작동한다. 결과는 부모 환경의 변수로 돌아온다.
실제 작동 과정을 예로 들어보자. 1,000개의 문서에서 특정 질문의 답을 찾아야 한다고 하자.
- 루트 LLM이
context[:2000]을 열람하여 데이터 구조를 파악한다 (Peeking) - 키워드 검색으로 관련 문서를 좁힌다 (Grepping)
- 관련 문서들을 10개씩 묶어 서브 LLM에 보낸다 (Partition + Map)
- 각 서브 LLM이 자기 몫의 문서에서 관련 정보를 추출한다
- 루트 LLM이 서브 결과들을 종합하여 최종 답변을 구성한다
이 과정이 프로그래머의 분할 정복 알고리즘과 닮았다는 점에 주목하자. 차이가 있다면, 분할 전략을 모델이 스스로 결정한다는 것이다. 정형화된 데이터에는 regex 검색을, 비정형 텍스트에는 청크 분할을, 코드 저장소에는 파일별 분석을 택한다.
실험 결과
저자들은 네 가지 벤치마크에서 RLM을 평가했다. 각각 서로 다른 유형의 장문 처리 능력을 측정한다.
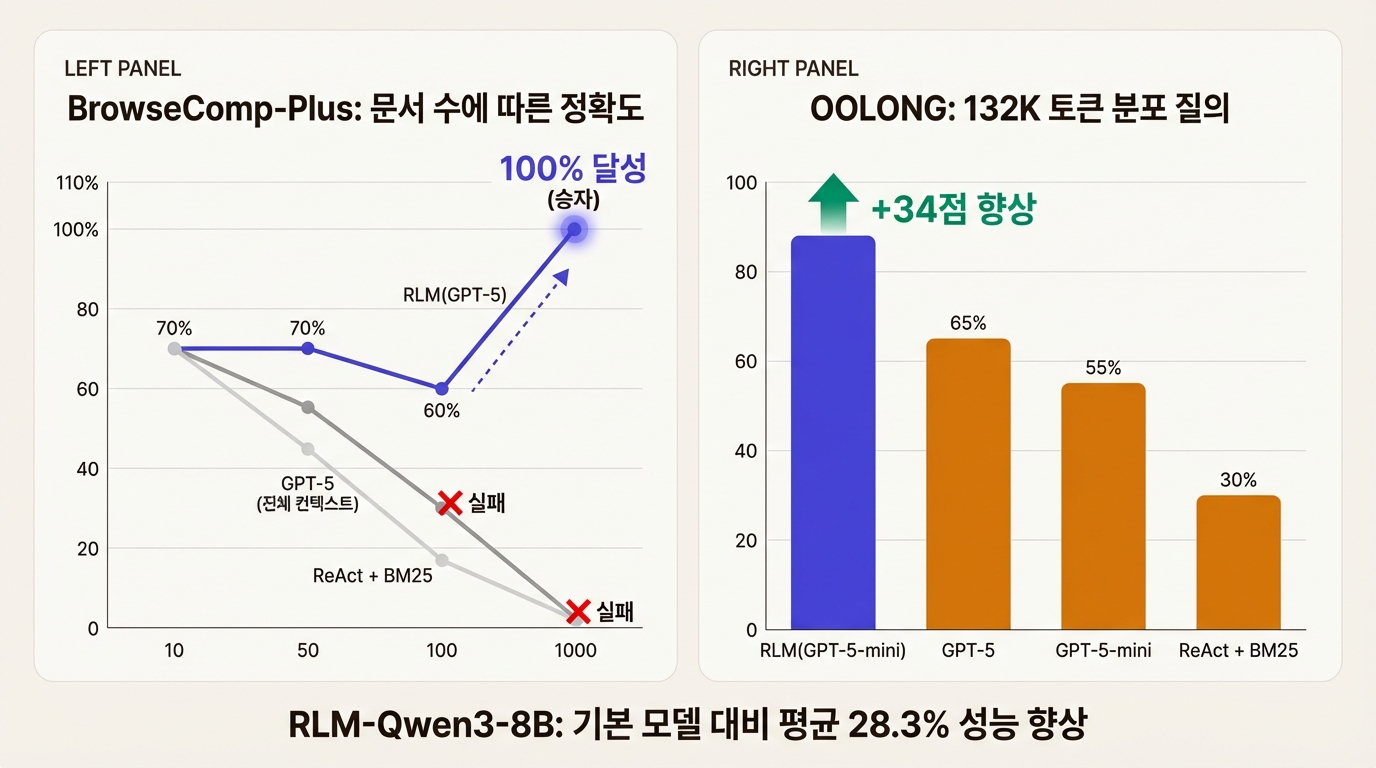
BrowseComp-Plus(멀티홉 추론): 10~1,000개의 문서에서 여러 출처에 걸친 정보를 종합해 답하는 과제다. 문서 수가 10개일 때는 모든 방법이 70% 안팎으로 비슷하다. 하지만 1,000개로 늘어나면 상황이 완전히 달라진다. RLM(GPT-5)은 100% 정확도를 유지한 반면, 전체 컨텍스트를 넣은 GPT-5는 크게 하락하고, BM25 검색 기반 에이전트는 사실상 실패했다. RLM이 유일하게 대규모에서도 성능을 유지한 방법이다.
OOLONG(분포 질의): 3,000~6,000개 항목에 대한 의미적 분류와 집계 과제로, 132K~263K 토큰 규모다. RLM(GPT-5-mini)은 GPT-5 단독 대비 34포인트(114%) 향상을 보였다. 8B 파라미터의 작은 모델이 재귀 구조 덕에 프론티어 모델을 압도한 것이다.
OOLONG-Pairs(쌍별 집계): 이차 복잡도를 요구하는 변형 과제다. RLM(GPT-5)은 58.0% F1을 기록했고, 기본 모델은 0.1%에 그쳤다. 재귀적 분할 없이는 사실상 풀 수 없는 문제임을 보여준다.
파인튜닝 결과: RLM-Qwen3-8B는 기본 Qwen3-8B 대비 평균 28.3% 성능이 향상되었으며, 세 가지 과제에서 GPT-5에 근접하는 품질을 달성했다. 1,000개의 학습 궤적만으로 이 수준의 개선이 가능하다는 점은 RLM의 학습 효율성을 보여준다.
비용 측면에서 RLM의 중위 비용은 기본 모델과 비슷하다. 다만 꼬리 분포의 분산이 크다. 일부 복잡한 질의에서는 재귀 깊이가 깊어지면서 비용이 급증할 수 있다.
RLM이 스스로 발견한 전략들
흥미로운 점은 이러한 탐색 전략을 연구자가 설계한 게 아니라 모델이 자발적으로 발견했다는 것이다. 저자들은 다섯 가지 창발적 행동 패턴을 관찰했다.
Peeking: 컨텍스트의 앞부분을 먼저 읽어 전체 구조를 파악한다. 프로그래머가 파일 헤더를 먼저 확인하는 것과 같다.
Grepping: 키워드와 정규표현식으로 관련 부분을 좁힌다. 의미적 검색이 아닌 패턴 매칭이므로 빠르고 정확하다.
Partition + Map: 컨텍스트를 균등 분할하여 각 조각에 서브 LLM을 할당한다. MapReduce의 Map 단계와 동일한 발상이다.
Summarization: 서브 호출 결과를 종합하여 상위 모델의 판단 재료로 쓴다.
코드를 통한 처리: diff 계산이나 집계처럼 LLM 추론보다 코드 실행이 정확한 작업은 REPL에서 직접 처리한다.
이 다섯 가지는 사실 숙련된 소프트웨어 엔지니어가 대규모 코드베이스를 분석할 때 쓰는 전략과 정확히 일치한다. RLM은 "LLM에게 프로그래머의 도구를 주면, LLM이 프로그래머처럼 행동한다"는 점을 실증한 셈이다.
에이전트 분해가 아닌, 컨텍스트 분해
RLM을 기존 에이전트 프레임워크와 혼동하기 쉽다. ReAct나 CodeAct 같은 에이전트도 코드를 실행하고 도구를 사용한다. 하지만 결정적 차이가 있다.
에이전트는 문제를 분해한다. "이 코드의 버그를 찾아라"를 "테스트를 실행하라 → 실패한 테스트를 확인하라 → 관련 코드를 수정하라"로 나눈다. 반면 RLM은 컨텍스트를 분해한다. 문제 자체는 그대로 두고, 입력 데이터를 조각내어 각 조각에 같은 질문을 던진다.
이 구분이 중요한 이유는, 문제 분해는 분해 전략을 사전에 정의해야 하지만, 컨텍스트 분해는 데이터의 구조에 따라 모델이 유연하게 결정할 수 있기 때문이다. MemGPT가 하나의 진화하는 컨텍스트를 관리하고, LADDER가 문제 중심 분해를 하는 것과 달리, RLM은 컨텍스트 자체를 모델이 조작할 수 있는 프로그래밍 객체로 전환한다.
한계와 남은 과제
RLM은 강력하지만 만능은 아니다.
속도 문제. 현재 구현에서 재귀 호출은 순차적으로 실행된다. 비동기 병렬 처리나 프리픽스 캐싱이 구현되어 있지 않아, 질의 하나에 수 초에서 수 분이 걸릴 수 있다. 실시간 응답이 필요한 서비스에는 아직 적합하지 않다.
비용 분산. 중위 비용은 기본 모델과 비슷하지만, 꼬리 분포에서 비용이 크게 튀는 경우가 있다. 재귀 깊이와 API 호출 횟수에 대한 예산 제어 메커니즘이 아직 없다.
얕은 재귀. 논문의 실험은 깊이 1(루트 → 서브 LLM)에서만 진행되었다. 깊이 2 이상의 재귀가 어떤 효과를 보이는지는 탐구되지 않았다.
평가 규모. BrowseComp-Plus 실험은 20개 질의로 수행되었다. 5개 인스턴스에서의 SWE-bench 결과와 함께, 더 대규모 평가가 필요하다.
이 논문에서 던질 질문 3개
-
재귀 깊이가 깊어지면 어떤 일이 일어날까? 현재 실험은 depth-1에 국한된다. depth-2 이상에서 모델이 컨텍스트를 더 세밀하게 분해할 수 있는지, 아니면 재귀 비용이 이득을 초과하는 지점이 있는지 검증이 필요하다.
-
RLM과 RAG는 상호보완적일까? RLM이 대규모 컨텍스트를 분해하는 "거시적 탐색"을 담당하고, RAG가 분해된 조각 내에서 "미시적 검색"을 담당하는 하이브리드 구조가 가능할까? 두 접근의 결합이 성능에 미치는 영향은 아직 연구되지 않았다.
-
모델 크기와 재귀 능력의 관계는? RLM-Qwen3-8B의 파인튜닝 결과가 인상적이지만, 더 작은 모델(1B~3B)에서도 재귀 전략을 학습할 수 있는지 궁금하다. 코드 생성과 재귀 추론 능력이 모델 크기의 어떤 임계점에서 나타나는지 밝혀야 한다.
추가로 읽으면 좋은 논문:
- ACON: Optimizing Context Compression for Long-Horizon LLM Agents, 에이전트 시나리오에서의 체계적 컨텍스트 압축 프레임워크
- Active Context Compression: Autonomous Memory Management in LLM Agents, 점균류에서 영감을 얻은 자율적 컨텍스트 관리
- MemGPT: Towards LLMs as Operating Systems, OS의 가상 메모리에서 착안한 LLM 메모리 관리
출처
- Zhang, A. L., Kraska, T., & Khattab, O. (2025). Recursive Language Models. arXiv:2512.24601.
- Prime Intellect. (2026). Recursive Language Models: the paradigm of 2026. Blog post.
- Khattab, O. et al. (2023). DSPy: Compiling Declarative Language Model Calls into State-of-the-Art Pipelines. arXiv:2310.03714.
- Packer, C. et al. (2023). MemGPT: Towards LLMs as Operating Systems. arXiv:2310.08560.
- Kang, M. et al. (2025). ACON: Optimizing Context Compression for Long-Horizon LLM Agents. arXiv:2510.00615.