같은 엔진, 다른 차
엔진이 똑같은 차 두 대가 있다. 한쪽은 서스펜션과 변속기, 공기역학까지 세밀하게 맞춘 차체에 얹혀 있고, 다른 한쪽은 프레임만 용접한 껍데기에 들어 있다. 당연히 결과가 다르다.
AI 코딩에서 지금 벌어지는 일이 딱 이렇다. 2026년 2월, Can Boluk이라는 개발자가 실험 하나를 공개했다. 15개 LLM을 두고 모델은 손도 안 댄 채 코드를 읽고 쓰는 "형식"만 바꿨다. 가장 극적인 경우, 정확도가 6.7%에서 68.3%로 뛰었다. 비용은 $300 남짓. 모델 재훈련 횟수는 0.
이 실험이 건드린 것을 "하니스(harness)"라 부른다. 모델 자체가 아니라, 모델을 둘러싼 모든 것이다. 어떤 도구를 쥐여주는지, 에러가 나면 어떤 메시지를 보여주는지, 코드를 어떤 포맷으로 주고받는지, 결과물을 자동으로 검증하는 장치가 붙어 있는지. 이 조각들의 총합이 하니스다.
Philipp Schmid(Hugging Face)의 비유가 알기 쉽다. 모델은 CPU, 컨텍스트 윈도우는 RAM, 하니스는 운영체제. CPU가 아무리 빨라도 운영체제가 허술하면 컴퓨터는 제대로 돌아가지 않는다. "2025년이 에이전트의 해였다면, 2026년은 에이전트 하니스의 해"라는 그의 선언은 이 맥락에서 나왔다.
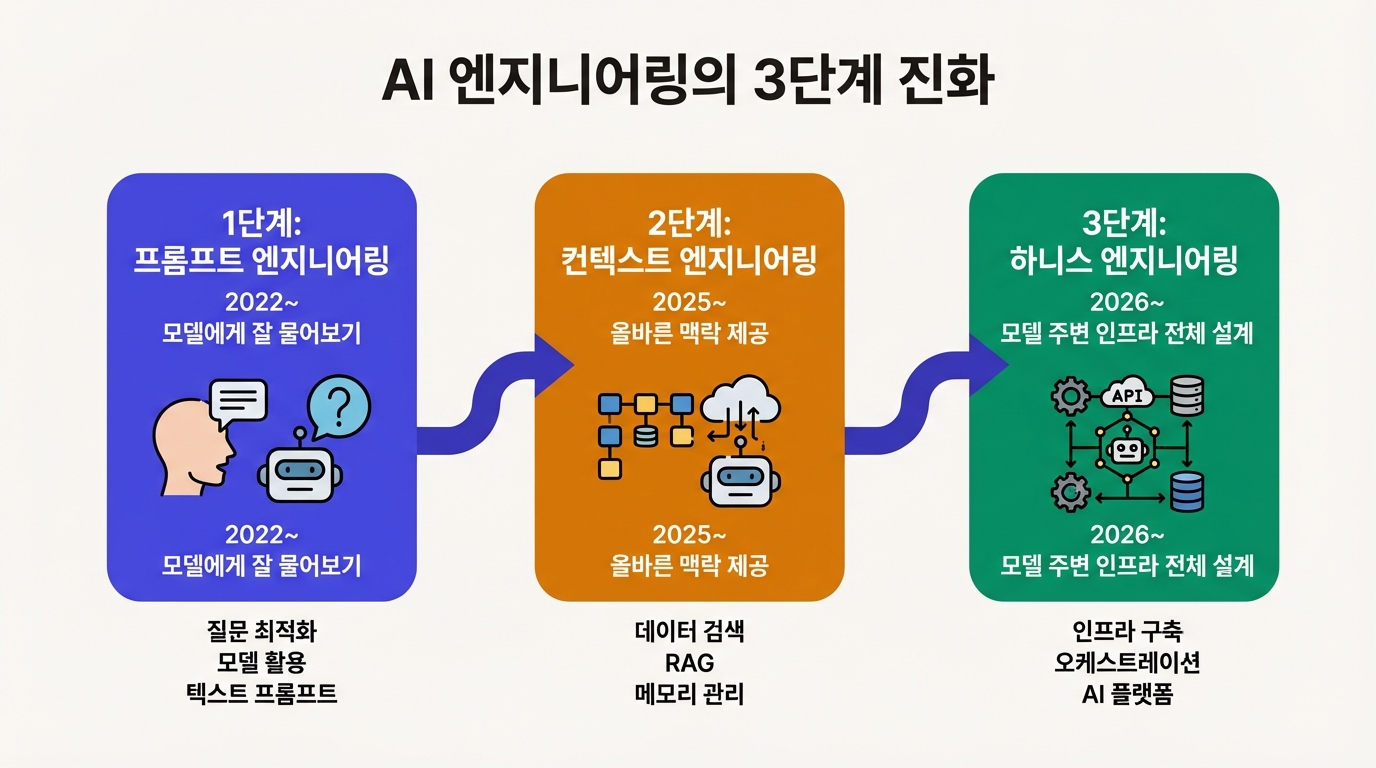
프롬프트에서 컨텍스트로, 컨텍스트에서 하니스로
이 흐름을 이해하려면 지난 4년을 한번 되짚어 볼 필요가 있다.
2022년부터 2024년까지 업계의 화두는 프롬프트 엔지니어링이었다. 모델에게 좋은 질문을 하는 기술이다. "역할을 부여해라", "단계별로 생각하라고 시켜라" 같은 팁이 쏟아졌다. 대화창에서 개인이 할 수 있는 최적화였고 단순한 작업에서는 먹혔다. 문제는 복잡한 작업이었다. 프롬프트를 아무리 다듬어도 결과가 들쭉날쭉했다. 프롬프트 한 줄에 담을 수 있는 정보란 결국 한정돼 있으니까.
2025년, Andrej Karpathy가 "컨텍스트 엔지니어링"이라는 이름을 붙였다. "다음 단계에 필요한 정확한 정보를 컨텍스트 윈도우에 채우는 섬세한 기술이자 과학." 프롬프트 한 줄이 아니라 RAG로 가져온 문서, few-shot 예시, 도구 목록, 대화 이력, 장기 메모리까지 모델이 보는 모든 정보를 의도적으로 설계한다는 관점이다. Shopify CEO Tobi Lutke가 적극 채택하면서 업계에 퍼졌다. 프롬프트 엔지니어링이 "질문을 잘 쓰는 기술"이었다면, 컨텍스트 엔지니어링은 "모델이 볼 세계를 설계하는 기술"로 한 단계 올라간 셈이다.
그런데 여기에도 빈 곳이 있었다. 모델에게 좋은 정보를 줘서 좋은 결과를 내게 하는 데까지는 됐는데, 결과가 나온 뒤의 이야기가 빠져 있었다. 결과물이 맞는지 자동으로 검증하고, 틀리면 피드백을 돌려보내고, 에이전트의 행동을 구조적으로 제약하는 루프 전체를 설계하는 것. 이것이 2026년 "하니스 엔지니어링"이라는 이름으로 등장한 영역이다.
하니스 엔지니어링은 세 축으로 구성된다. 첫째는 컨텍스트 큐레이션으로 기존 컨텍스트 엔지니어링이 다루던 영역이다. 둘째는 아키텍처 제약인데, 린터나 테스트, LLM 기반 감시 같은 구조적 가드레일을 거는 것이다. 셋째는 엔트로피 관리다. 문서 불일치나 아키텍처 위반을 주기적으로 감지해서 자동 수정한다. 핵심 전환점은 하나다. "에이전트가 실패하면 사람이 고친다"에서 "에이전트가 실패하면 환경을 고친다"로 무게중심이 옮겨간 것.
OpenAI가 코드 0줄로 100만 줄을 만든 방법
2026년 2월, OpenAI가 내부 실험을 하나 공개했다. 제목은 "Harness Engineering: Leveraging Codex in an Agent-First World".
실험 내용은 이렇다. 소수의 엔지니어가 5개월 동안 Codex 에이전트만으로 100만 줄의 코드를 작성하고 배포했다. 사람이 직접 쓴 코드는 0줄이다. 사람의 역할은 코드 작성이 아니라 환경 설계, 의도 명세, 구조화된 피드백 제공 세 가지로 바뀌었다.
팀은 "Golden Principles"이라는 규칙 세트를 리포지토리에 직접 심어놓았다. 에이전트가 코드를 생성할 때 이 원칙을 자동으로 참조하게 한 것이다. 아키텍처 레이어 순서도 강제했다. Types, Config, Repo, Service, Runtime, UI. 이 순서를 어기면 코드가 자동으로 거부된다. 에이전트에게 자유를 주되 구조적 제약 안에서만 움직이게 한 것인데, 마치 볼링 레인에 범퍼를 세운 것과 비슷하다.
Karpathy가 말한 "에이전틱 엔지니어링"의 실체가 여기서 드러난다. "99%의 시간을 코드 작성이 아니라 에이전트 감독에 쓴다." 비유가 아니다. OpenAI 팀이 5개월간 실제로 한 일이 그것이었다.
물론 의문도 있다. Martin Fowler의 블로그에서 Birgitta Bockeler가 OpenAI의 접근을 "가치 있는 프레이밍"이라 지지하면서도 한 가지를 짚었다. 기능 및 동작 검증이 빠져 있다는 것이다. 아키텍처 레이어를 강제하고 린터를 돌리는 건 구조적 정합성을 잡아주지만, "이 코드가 실제로 의도한 대로 동작하는가"를 확인하는 장치는 OpenAI가 공개한 내용에 없었다. 100만 줄이 돌아가긴 하는데 품질과 유지보수성에 대한 구체적 수치가 없다는 점도 약점이다.
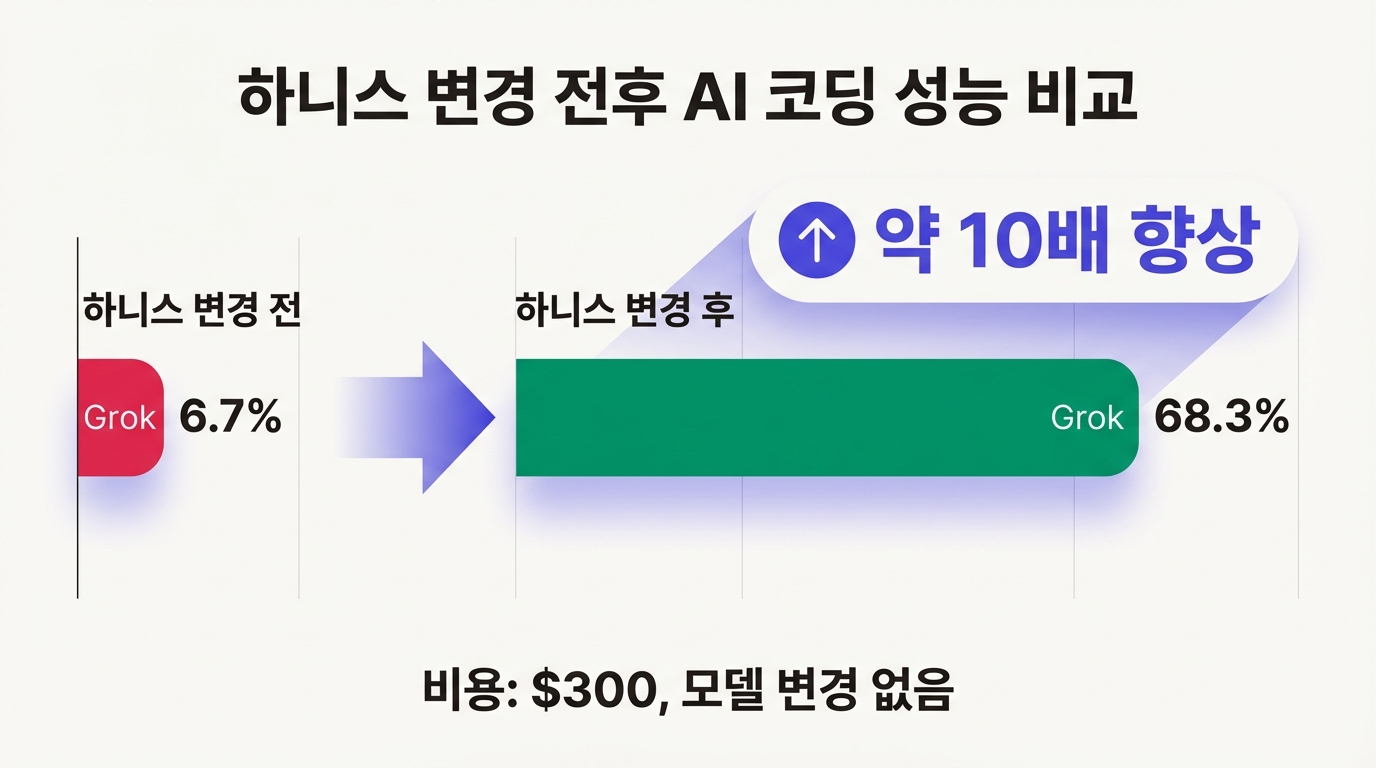
포맷 하나 바꿨더니 정확도가 10배
OpenAI의 실험이 대기업 규모의 이야기라면, Can Boluk의 실험은 정반대 끝에 있다. 개인 개발자 한 명, $300, 하루 오후.
Boluk은 "The Harness Problem"이라는 글에서 실험을 공개했다. 출발점은 단순했다. AI 코딩 도구들이 모델에게 코드 수정을 지시할 때 쓰는 Patch 포맷이 비효율적이라는 것이다. Patch 포맷은 원래 사람이 읽으라고 만든 것이라 모델에게는 불필요한 정보가 많고 정확한 위치 지정이 어렵다.
Boluk이 만든 "Hashline" 포맷의 원리는 간단하다. 코드의 각 줄에 2~3자짜리 해시 태그를 붙인다. 모델이 "이 줄을 수정해"라고 할 때 줄 번호 대신 해시 태그로 위치를 참조한다. 줄 번호는 편집할 때마다 밀리지만 해시 태그는 해당 줄의 내용에 고정돼 있으니 오류가 줄어드는 구조다.
이 포맷 하나를 바꿔서 15개 LLM을 테스트한 결과가 놀랍다. Grok Code Fast 1의 정확도는 6.7%에서 68.3%로 뛰었다. 대부분의 모델에서 Hashline이 기존 Patch 포맷을 이겼고 토큰 사용량은 20%에서 61%까지 줄었다. 모델 재훈련은 없었다. 모델 코드에 손을 댄 적도 없다. 바꾼 건 오직 모델이 코드를 읽고 쓰는 형식뿐이다.
Anthropic의 Claude Code에서도 비슷한 현상이 확인된다. Claude Code의 하니스 최적화만으로 Opus의 벤치마크 점수가 다른 구현 대비 거의 2배로 올라갔다는 보고가 있다. 같은 모델인데 하니스가 다르면 결과도 달라진다.
새 술인가, 새 부대인가
당연히 이런 질문이 나올 수 있다.
"DevOps를 재포장한 거 아닌가?" 린터, CI/CD, 테스트는 원래 있던 것이 맞다. 하지만 기존 DevOps 도구들은 사람을 위해 설계됐다. 하니스 엔지니어링은 같은 종류의 도구를 에이전트 맞춤으로 재설계한다. 에러 메시지 하나를 예로 들어 보자. 사람에게는 "Line 42: syntax error"면 충분하다. 에이전트에게는 에러의 원인과 영향 범위, 수정 방향까지 구조화된 형태로 전달해야 효과가 있다. Boluk의 Hashline 실험이 정확히 이 지점을 찔렀다. 사람용 포맷을 에이전트용으로 바꿨더니 성능이 10배 뛴 것이다.
"벤치마크가 실무를 대변하나?" 이건 유효한 비판이다. Boluk의 실험은 코드 편집이라는 좁은 범위에서 진행됐다. 전체 소프트웨어 개발에서 이 개선이 차지하는 비중은 1% 미만일 수 있다. OpenAI도 100만 줄이라는 숫자만 내놓았을 뿐 코드 품질이나 유지보수성 지표를 공개하진 않았다. 하니스 엔지니어링의 효과가 프로덕션 환경에서 어느 정도인지는 아직 증명이 필요한 단계다.
"개인 프로젝트에도 이게 필요한가?" 솔직히 개인 프로젝트에 대규모 관찰 가능성 스택을 구축할 이유는 없다. 하니스가 반드시 거창할 필요도 없다. CLAUDE.md 파일 하나에 프로젝트 규칙을 적어두는 것도 하니스고, 커스텀 린터 규칙 하나를 추가하는 것도 하니스다. Boluk의 실험도 복잡한 인프라가 아니라 코드 포맷 하나를 바꾼 것이었다. 규모에 맞춰 적용하면 된다.
모델보다 환경에 투자하라
Philipp Schmid가 정리한 세 가지 원칙이 쓸 만한 출발점이 된다.
첫째, 단순하게 시작할 것. 복잡한 에이전트 오케스트레이션을 설계하기 전에 하나의 도구가 하나의 일을 확실히 해내도록 만드는 게 먼저다. 견고한 원자적 도구 하나가 복잡한 제어 흐름보다 낫다.
둘째, 삭제하기 쉽게 만들 것. 오늘의 모델에 필요한 가드레일이 내일의 모델에는 쓸모없을 수 있다. 하니스의 각 부분이 독립적이어야 필요없어졌을 때 걷어낼 수 있다. 모델이 6개월마다 세대교체되는 현실에서 특히 중요한 원칙이다.
셋째, 하니스를 데이터셋으로 활용할 것. 에이전트가 작업하는 과정을 캡처하면, 그 자체가 다음 세대 하니스를 설계하는 재료가 된다. Schmid는 이것이 장기적으로 가장 큰 경쟁 우위가 될 것으로 본다.
이 글 전체를 관통하는 사실은 하나다. 모델은 6개월마다 새로 나온다. 하지만 잘 설계된 하니스는 쌓인다. 모델을 교체해도 좋은 하니스는 그대로 쓸 수 있다. OpenAI가 Codex를 위해 설계한 아키텍처 제약은 다음 모델에도 적용되고, Boluk의 Hashline 포맷은 어떤 모델에든 붙일 수 있다. "모델보다 환경에 투자하라"는 말의 실질적 의미가 여기에 있다. 빠르게 감가상각되는 모델에 올인하기보다 축적 가능한 인프라를 쌓는 쪽이 합리적이다.