린터 에러 메시지가 열어젖히는 문
린터가 빨간 줄을 긋는다. "이 의존성을 허용된 레이어로 옮기려면 X 리팩토링을 수행하라." 에이전트는 그 메시지를 읽고, 코드를 고치고, 린터를 다시 돌린다. 통과. 다음 단계. 사람은 개입하지 않았다. 에러가 나오고, 에이전트가 읽고, 고치고, 확인하는 순환. 피드백 루프의 가장 단순한 형태다.
그런데 린터가 잡아주는 건 "방금 이 줄이 틀렸다" 수준이다. "지금까지의 접근 방식 자체가 잘못된 건 아닌가?"는 린터의 관할이 아니다. "지난주에도 같은 실수를 했는데 또 반복하고 있다"는 더더욱 관할 밖이다. 피드백 루프에는 시간 범위에 따라 층위가 있다.
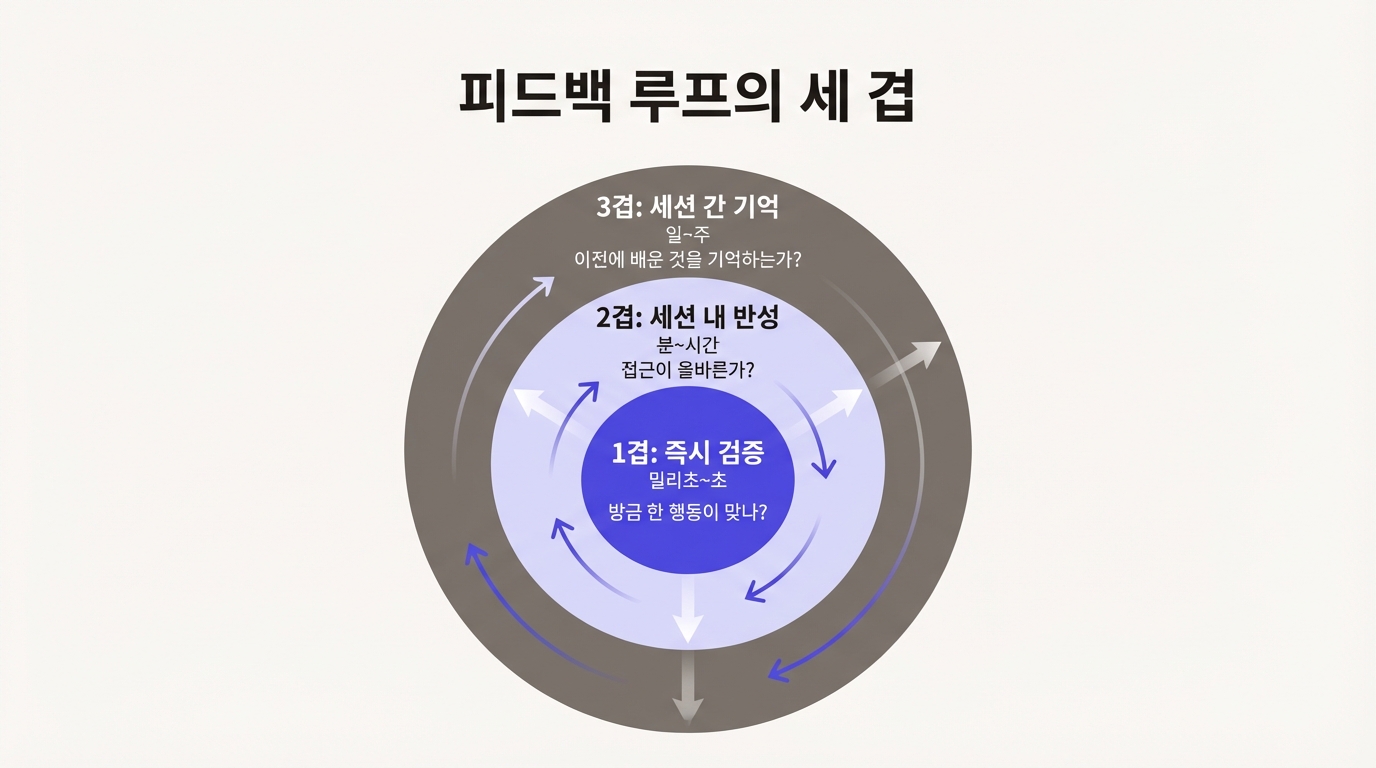
시간 범위로 나눠 보는 피드백
제약이 "무엇을 하지 말라"를 정의한다면, 피드백 루프는 "했는데 괜찮은가"를 묻는다. 이 질문의 시간 범위가 셋으로 갈라진다.
| 이름 | 시간 범위 | 핵심 질문 |
|---|---|---|
| 즉시 검증 | 밀리초에서 초 | "방금 한 행동이 맞나?" |
| 세션 내 반성 | 분에서 시간 | "지금까지의 접근이 올바른가?" |
| 세션 간 기억 | 일에서 주 | "이전에 배운 것을 기억하는가?" |
린터 에러 메시지는 즉시 검증이다. 에이전트가 같은 파일을 반복 수정하다가 "접근을 바꿔보라"는 경고를 받는 건 세션 내 반성이다. AGENTS.md에 쌓인 규칙이 다음 세션의 에이전트 행동을 바꾸는 건 세션 간 기억이다. 하나씩 들여다본다.
1. 밀리초 단위의 즉시 검증
Claude Code Hooks의 3계층 검증
Claude Code에는 "Hooks"라는 피드백 장치가 내장되어 있다. 에이전트가 도구를 호출하기 전, 호출한 직후, 작업을 끝내려 할 때 각각 끼어들어 검증을 수행한다.
훅의 유형이 세 가지로 나뉜다는 점이 흥미롭다.
command 훅은 셸 명령을 실행한다. 결정론적이다. Prettier 같은 포매터를 PostToolUse 시점에 걸어두면 에이전트가 파일을 수정할 때마다 자동으로 코드 스타일이 통일된다. 판단이 끼어들 여지가 없다. 규칙대로 돌아갈 뿐이다.
prompt 훅은 LLM에게 단일 턴으로 질문한다. "이 파일을 수정해도 되는가?" 같은 의미론적 판단을 맡기고 ok: true 또는 false를 반환받는다. 보호해야 할 파일(설정 파일, 마이그레이션 스크립트 등)에 대한 수정 시도를 PreToolUse 시점에서 차단하는 용도다.
agent 훅은 서브에이전트를 띄워 다중 턴 검증을 수행한다. 최대 50번의 도구 사용이 허용된다. 파일을 읽고, 코드를 검색하고, 셸 명령을 돌리면서 복합적인 판단을 내린다.
이 세 유형이 붙는 이벤트도 구분된다. PreToolUse는 도구를 쓰기 직전에 끼어들어 위험한 행동을 차단한다(allow/deny/ask). PostToolUse는 도구 실행 직후에 결과를 교정한다. Stop은 에이전트가 "끝났다"고 선언하는 순간에 작동한다.
Stop 훅이 특히 재미있다. 에이전트가 종료를 시도하면 Stop 훅이 테스트를 돌려본다. 실패하는 케이스가 있으면 {ok: false, reason: "테스트 3건 실패. auth 모듈의 토큰 검증 로직 확인 필요"} 같은 응답을 돌려보낸다. 에이전트는 종료하지 못하고 해당 문제를 해결한 뒤 다시 종료를 시도한다. "끝났다고 했는데 진짜 끝난 게 맞아?"를 기계적으로 되묻는 구조다.
3계층(command, prompt, agent)의 핵심은 피드백의 복잡도를 계단식으로 배치한다는 것이다. 포매팅처럼 판단이 필요 없는 건 command로 즉시 처리한다. 파일 접근 권한처럼 간단한 판단이 필요한 건 prompt로 처리한다. 테스트 통과 여부처럼 복합적인 확인이 필요한 건 agent로 처리한다. 가벼운 피드백을 앞에, 무거운 피드백을 뒤에 놓으면 불필요한 연산을 줄이면서도 검증의 빈틈을 막을 수 있다.
CodeScene의 3단계 품질 게이트
CodeScene이라는 코드 분석 도구는 피드백 시점을 세 곳에 설치한다.
첫째, Continuous Review. 에이전트가 코드를 생성하는 도중에 실시간으로 품질을 평가한다. 둘째, Pre-commit Safeguard. 커밋 직전에 스테이징된 파일을 검증한다. 셋째, PR Pre-flight Check. PR을 올리기 전에 베이스 브랜치 대비 전체 변경 세트를 검증한다.
왜 세 곳이 필요할까. 피드백이 늦을수록 낭비가 커진다. 코드를 생성한 지 30초 만에 문제를 발견하면 30초치 작업만 버리면 된다. 커밋 직전에 발견하면 몇 분치가 날아간다. PR 단계에서 발견하면 수십 분치 작업이 물거품이 된다. 즉시 검증의 핵심 원리는 피드백 지연을 0에 가깝게 줄이는 것이다.
CodeScene에서 한 가지 더 눈여겨볼 기능이 있다. 테스트 삭제 감지다. 에이전트에게는 "테스트를 통과시키는 가장 빠른 방법"이 "테스트를 지우는 것"인 경우가 있다. 커버리지 게이트가 이 시도를 즉시 포착한다. 문법적으로는 올바른 행동이지만 의도적으로는 완전히 잘못된 행동이다. 이 구분을 기계적으로 잡아내는 게 즉시 검증의 가치다.
코드 밖의 버그를 잡는 눈: 브라우저 검증
린터가 코드 수준의 검증이라면, 브라우저 검증은 사용자가 실제로 보는 화면 수준의 검증이다. 코드가 문법적으로 완벽해도 화면에서 버튼이 잘리거나, 모바일에서 레이아웃이 깨지거나, 폼 데이터가 유실되는 버그는 코드만 봐서는 잡을 수 없다.
alexop.dev의 개발자가 구축한 QA 에이전트 "Quinn"은 이 문제를 Playwright MCP로 풀었다. 설계의 핵심은 "블랙박스 테스트 강제"다. Quinn은 소스코드에 접근할 수 없다. 브라우저를 조작하는 도구 5개만 쓸 수 있다: navigate, click, type, take_screenshot, resize. 사용자와 동일한 조건에서 UI만 보고 테스트한다.
테스트는 4단계로 진행된다. 먼저 Happy Path, 기능이 설명대로 작동하는지 검증한다. 다음으로 Edge Case 탐색. 음수 입력, 극단적으로 긴 문자열, 빠른 반복 클릭 같은 경계 조건을 시도한다. 세 번째로 모바일 뷰포트(375x667)로 리사이즈해서 레이아웃을 확인한다. 마지막으로 관련 기능에 대한 회귀 테스트를 수행한다.
이 구조가 GitHub Actions와 통합되어 있다는 점도 짚을 만하다. PR에 qa-verify 라벨을 붙이면 자동으로 스테이징 환경에 배포되고, Quinn이 테스트를 돌린 뒤 결과를 마크다운 리포트로 PR 코멘트에 남긴다. 사람이 "테스트 돌려봐"라고 지시하지 않아도 라벨 하나로 피드백 루프가 돌아간다.
한계도 있다. Anthropic의 공식 가이드에 따르면 Puppeteer MCP는 브라우저 네이티브 alert 모달을 감지하지 못한다. alert에 의존하는 기능이 있다면 그 부분의 버그는 빠져나간다. 즉시 검증이 아무리 촘촘해도 커버하지 못하는 영역은 존재한다. 그래서 세션 내 반성이 필요하다.
2. 분 단위의 세션 내 반성
즉시 검증이 "방금 한 행동"에 대한 피드백이라면, 세션 내 반성은 "지금까지의 전체 접근 방식"에 대한 피드백이다. 린터를 통과한 코드 한 줄 한 줄이 모두 맞아도 전체 방향이 틀릴 수 있다. 나무는 맞는데 숲이 틀린 상황이다.
Reasoning Sandwich: 추론 예산을 어디에 몰 것인가
LangChain이 Terminal Bench 2.0에서 실험한 "Reasoning Sandwich" 전략의 성능 데이터를 자세히 들여다보면 직관에 반하는 결과가 나온다.
| 추론 강도 배분 | 점수 |
|---|---|
| 전 구간 xhigh (최대 추론) | 53.9% |
| 전 구간 high (보통 추론) | 63.6% |
| xhigh-high-xhigh (계획-구현-검증) | 66.5% |
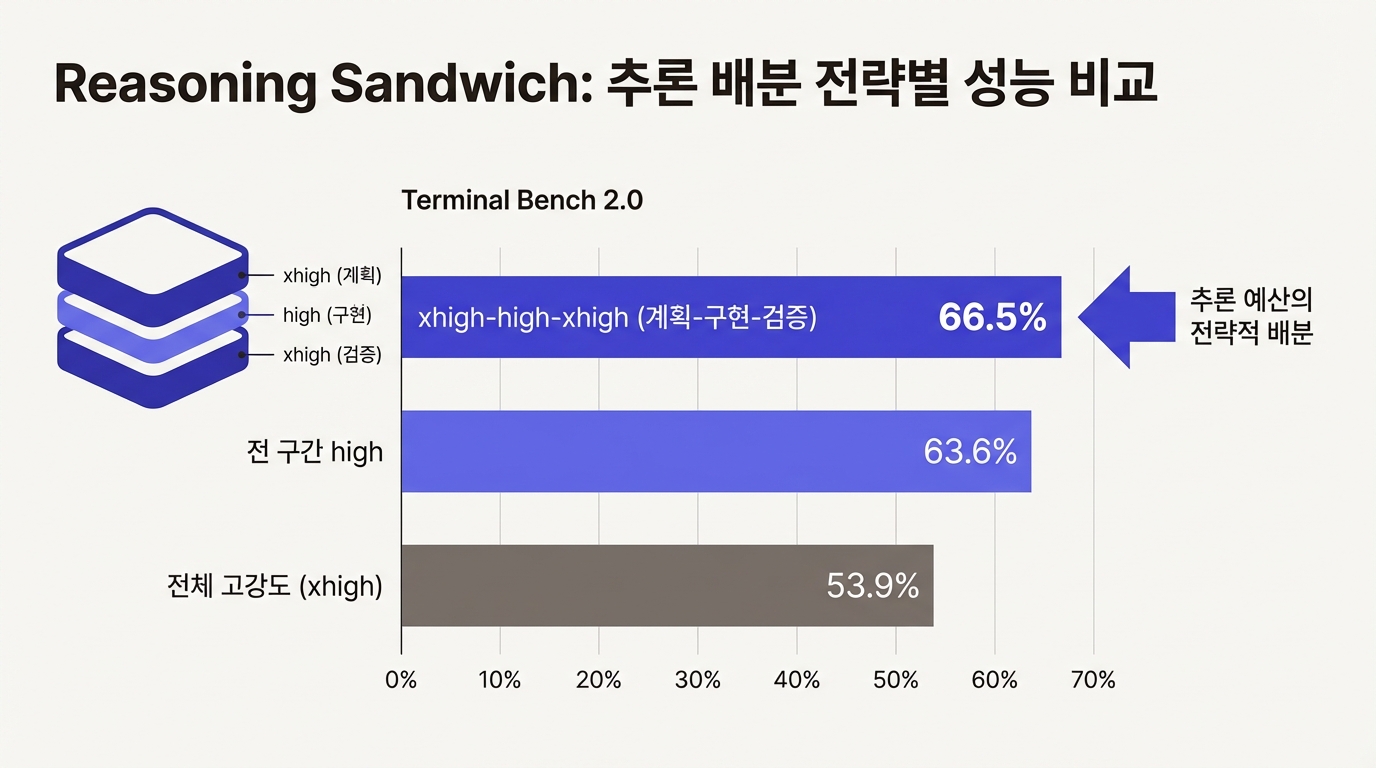
전 구간에 최대 추론을 적용한 53.9%가 가장 낮다. 왜? 타임아웃이다. 모든 단계에서 최대한 깊게 생각하려 하니 시간이 부족해진다. 89개 코딩 과제에는 시간 제한이 있고, 시간 안에 끝내지 못하면 0점이다.
Reasoning Sandwich는 추론 예산의 전략적 배분으로 이 문제를 풀었다. 계획 단계에서는 xhigh(최대 추론)로 방향을 잡는다. 구현 단계에서는 high(보통 추론)로 토큰을 아낀다. 검증 단계에서 다시 xhigh로 올려 결과를 꼼꼼히 확인한다. 구현 중에 추론을 줄이는 것이 타임아웃을 방지하면서 검증 품질을 유지하는 열쇠였다.
이 발견은 시간 예산 관리라는 더 넓은 주제로 연결된다. Addy Osmani는 명시적 중단 조건의 설계를 권고한다. 최대 반복 횟수 제한(예: 50루프), 시간 제한("3시간 넘으면 종료"), 유휴 감지("최근 5회 반복 동안 새 커밋이 없으면 중단"). Phil Schmid의 표현이 핵심을 찌른다: "예산에 도달하면, 그건 모델의 문제가 아니라 하니스의 문제다." 에이전트가 시간을 초과했다면 모델이 느린 게 아니라 하니스가 추론 자원을 잘못 배분한 것이다.
감독 없이 에이전트를 돌리면 세션 비용이 $20,000까지 치솟을 수 있다는 보고도 있다. 세션당 예산 제한을 설정하고 결정적 분기점에서는 사람의 승인을 받도록 설계하는 것이 실전에서의 안전 장치다.
자가 비평: Generate, Critique, Improve
에이전트가 출력을 낸다. 그 출력을 특정 기준으로 비평한다. 비평을 바탕으로 수정한다. 필요하면 이 순환을 반복한다. 자가 비평(self-critique) 루프의 기본 구조다. 가중치를 업데이트하지 않는다. 파인튜닝도 없다. 자연어 피드백만으로 에이전트의 행동을 교정한다. 연구자들은 이걸 "verbal reinforcement learning(언어적 강화학습)"이라고 부른다.
Reflexion 프레임워크(Shinn 외, 2023)가 이 패턴의 대표적 구현이다. Actor(LLM)가 태스크를 시도한다. 결과와 피드백을 받는다. Self-Reflection 프롬프트가 텍스트 형태의 비평을 생성한다. 이 비평이 메모리에 저장된다. 다음 시도에서 비평을 참고한다.
성능 데이터가 인상적이다. HumanEval(코딩 벤치마크)에서 GPT-4에 Reflexion을 적용하면 80%에서 91%로 올라간다. 같은 모델 그대로인데 텍스트 피드백 루프만 추가해서 11%포인트 상승. 모델을 바꾸지 않고 피드백 구조만 바꿔서 성능을 끌어올린 것이다. 하니스 엔지니어링의 핵심 논지가 여기서도 반복된다.
그런데 자기 눈으로 자기 오류를 발견하는 데는 한계가 있다. 결함 있는 자가 평가가 에이전트를 더 잘못된 방향으로 유도할 가능성이 존재한다. 사람도 자기가 쓴 글의 오탈자를 잘 못 찾는다. 에이전트도 마찬가지다.
그래서 multi-agent review가 등장한다. Hamel Husain이 만든 claude-review-loop 플러그인은 "독립적인 second opinion" 구조로 이 문제를 풀었다. Claude가 코드를 구현한다. Stop 훅이 작동하면서 OpenAI Codex를 독립 리뷰어로 스폰한다. Codex는 최대 4종의 리뷰를 병렬로 수행한다.
| 리뷰 유형 | 검토 항목 |
|---|---|
| Diff Review | 코드 품질, 테스트 커버리지, 보안 |
| Holistic Review | 전체 구조, 문서, 아키텍처 정합성 |
| Next.js Review | 프레임워크 특화 검증 (조건부 실행) |
| UX Review | 사용자 경험, 브라우저 E2E 포함 (조건부 실행) |
리뷰 결과는 중복 제거 후 reviews/review-<id>.md에 저장된다. Claude가 피드백을 반영한 뒤 다시 종료를 시도하고, 2차 Stop 훅에서 최종 종료가 허용된다. 구현 에이전트와 리뷰 에이전트가 다른 모델이라는 점이 핵심이다. 같은 모델이 자기 코드를 리뷰하면 같은 맹점을 공유할 가능성이 높다. 다른 모델이 보면 다른 관점에서 결함을 발견할 수 있다.
LangSmith 트레이스 분석: 반성에 데이터를 붙인다
LangChain은 자가 비평을 한 단계 더 체계화했다. LangSmith 플랫폼에서 에이전트의 모든 행동을 트레이스로 기록하고, 이 트레이스를 분석하는 파이프라인을 "Agent Skill"로 구현했다.
3단계 프로세스다. 먼저 LangSmith에서 실험 트레이스를 가져온다. 다음으로 병렬 에러 분석 에이전트를 스폰해서 실패 패턴을 분류한다. 추론 오류, 지시 미준수, 테스트 누락, 타임아웃 문제 같은 카테고리로 나뉜다. 마지막으로 메인 에이전트가 분석 결과를 종합하여 하니스 개선 제안을 생성한다.
이 접근이 머신러닝의 부스팅(boosting)과 닮았다는 지적이 있다. 부스팅은 이전 모델이 틀린 데이터에 가중치를 높여서 다음 모델이 그 부분에 집중하게 만드는 앙상블 기법이다. LangSmith 파이프라인도 이전 실행에서 실패한 패턴에 집중해서 하니스를 개선한다. 같은 원리가 다른 영역에서 반복되는 셈이다.
여기서 핵심은 "트레이스 없이는 반성이 인상론에 머문다"는 점이다. 에이전트가 "잘 안 되는 것 같다"고 느끼는 것과, 트레이스 데이터에서 "추론 오류가 전체 실패의 40%를 차지한다"를 확인하는 것은 완전히 다른 수준의 반성이다. Phil Schmid가 "모든 트레이스를 기록하라"고 강조하는 이유다.
3. 세션을 넘어 축적되는 기억
앞의 두 단계는 하나의 세션 안에서 작동한다. 세션이 끝나면 사라진다. 컨텍스트 윈도우가 초기화되기 때문이다. Phil Schmid의 비유를 빌리면 컨텍스트 윈도우는 RAM이다. 전원이 꺼지면 날아간다.
여기서의 질문은 이것이다. "이번 세션에서 배운 것이 다음 세션에 영향을 미치는가?" 기억이 없으면 매 세션이 첫 세션이다.
에이전트 메모리의 네 종류
CoALA(Cognitive Architectures for Language Agents)라는 연구에서 에이전트 메모리를 네 종류로 분류했다. 인지과학에서의 기억 분류를 에이전트 시스템에 대응시킨 것이다.
**Working Memory(작업 기억)**는 컨텍스트 윈도우 그 자체다. 지금 대화하고 있는 내용, 방금 읽은 파일, 직전에 실행한 도구 결과. 용량이 제한되어 있고, 세션이 끝나면 사라진다. 사람으로 치면 지금 머릿속에서 처리하고 있는 정보다.
**Semantic Memory(의미 기억)**는 사실 정보의 저장소다. "이 프로젝트는 TypeScript를 사용한다", "테스트 프레임워크는 vitest다", "API 엔드포인트 네이밍은 kebab-case를 따른다" 같은 지식. AGENTS.md나 CLAUDE.md에 축적된 규칙과 패턴이 대표적 구현이다.
**Episodic Memory(일화 기억)**는 과거 행동과 그 결과에 대한 기록이다. "어제 npm test를 돌렸더니 auth 모듈에서 3건 실패했다", "지난주에 레이어 의존성을 역방향으로 잡았다가 린터에 걸렸다" 같은 구체적 경험. progress.txt나 git commit history가 이 역할을 한다.
**Procedural Memory(절차 기억)**는 운영 지침이다. "작업을 시작하면 먼저 기존 테스트를 돌려라", "PR을 올리기 전에 빌드를 확인하라" 같은 행동 규칙. 시스템 프롬프트나 미들웨어에 내장된 규칙이 여기에 해당한다.
Addy Osmani는 이 분류를 실전 아키텍처로 옮겼다. 그가 제안하는 4채널 메모리 구성은 이렇다.
- Git Commit History: 영구적 코드 변경 기록. 에이전트가 diff를 읽어 "이 파일이 왜 이 형태인지"를 파악한다.
- Progress Log (progress.txt): 시도, 성공, 에러 메시지를 시간순으로 기록한다. "뭘 했고 뭐가 됐고 뭐가 안 됐는지"의 타임라인이다.
- Task State (prd.json): 완료된 태스크와 미완료 태스크를 JSON으로 추적한다. 이미 끝난 작업을 다시 하는 중복을 방지한다.
- Semantic Knowledge (AGENTS.md): 에이전트의 발견, 프로젝트 관습, 미래 에이전트를 위한 가이드가 축적된다.
네 채널이 있으면 충분한가? 아니다. 핵심은 채널 간 전환에 있다.
Episodic에서 Semantic으로: 경험이 규칙이 되는 순간
에이전트가 npm test를 세 번 돌린다. 세 번 다 실패한다. 이건 Episodic Memory, 구체적 경험이다. 여기서 한 단계 올라간다. "이 프로젝트의 테스트 러너는 vitest이고, npm test가 아니라 npx vitest를 써야 한다." 이 깨달음은 Semantic Memory, 일반화된 지식이다.
이 전환을 "통합(consolidation)"이라고 부른다. 개별 에피소드에서 패턴을 추출해 범용 지식으로 승격시키는 과정이다. 수면 중에 일어나는 기억 통합과 비슷한 원리다. 에이전트 시스템에서는 이 통합이 명시적으로 설계되어야 한다.
AGENTS.md가 이 통합의 실전 경로다. 에이전트가 실수한다. 그 실수를 방지하는 규칙이 AGENTS.md에 추가된다. 다음 세션의 에이전트가 이 규칙을 읽는다. 같은 실수를 반복하지 않는다. 3편에서 다룬 "아키텍처 제약"으로서의 AGENTS.md와, 이번 편에서 다루는 "기억 저장소"로서의 AGENTS.md는 같은 파일의 두 얼굴이다.
Addy Osmani가 소개한 실시간 개입 기법도 이 맥락에서 읽힌다. 에이전트가 작업 중인데 deprecated된 API 엔드포인트를 사용하고 있다면, 사람이 AGENTS.md에 "v1/users 엔드포인트는 deprecated. v2/users를 사용할 것"이라고 메모를 추가한다. 에이전트는 다음 반복에서 이 메모를 읽고 행동을 바꾼다. Semantic Memory에 대한 실시간 쓰기가 에이전트의 즉각적 행동 변화로 이어지는 것이다.
기억의 한계: 쌓기만 하면 노이즈가 된다
메모리가 쌓이기만 하면 문제가 생긴다. 3개월 전에 추가한 규칙이 현재 코드베이스에서는 더 이상 유효하지 않을 수 있다. 라이브러리 버전이 바뀌었거나, 아키텍처가 리팩토링되었거나, 해당 기능 자체가 삭제되었을 수 있다. 오래된 규칙이 남아 있으면 에이전트가 이미 해결된 문제에 대한 우회 경로를 불필요하게 적용한다.
자동으로 오래된 정보를 삭제하는 것은 까다로운 문제다. "이 규칙은 더 이상 유효하지 않다"를 판단하려면 현재 코드베이스 상태에 대한 이해가 필요하고, 그 판단 자체가 또 다른 에이전트 추론을 요구한다. 검색과 저장 작업의 오버헤드도 무시할 수 없다.
이 문제의 무게는 학계의 반응에서도 드러난다. ICLR 2026에서 "MemAgents"라는 에이전트 메모리 전용 워크숍이 열렸다. 에이전트의 기억 문제만으로 독립된 학술 행사가 성립할 정도로 미해결 과제가 많다는 뜻이다.
세 가지 시간 범위가 하나의 순환으로
셋을 따로 떼어놓으면 별개의 메커니즘처럼 보이지만, 실제로는 하나의 순환으로 연결된다.
즉시 검증이 잡지 못한 문제가 세션 내 반성으로 올라간다. 린터는 통과했지만 전체 방향이 틀린 경우, Reasoning Sandwich의 검증 단계나 자가 비평 루프가 이를 포착한다. 세션 내 반성에서 발견된 패턴이 세션 간 기억으로 축적된다. "이 유형의 작업에서는 접근 방식 A보다 B가 효과적이다"라는 발견이 AGENTS.md에 기록되고, 다음 세션의 에이전트가 처음부터 더 나은 접근을 취한다. 축적된 기억이 다음 세션의 즉시 검증 기준을 더 정밀하게 만든다. "이전에 이 패턴에서 실수가 잦았으니 이 부분의 린터 규칙을 강화하자."
Phil Schmid의 OS 비유를 확장하면 이렇게 된다. 모델이 CPU이고 컨텍스트 윈도우가 RAM이라면, 피드백 루프는 OS의 인터럽트 핸들러다. CPU가 작업을 처리하다가 예외가 발생하면 인터럽트 핸들러가 개입해서 상황을 교정한다. 즉시 검증은 하드웨어 인터럽트(즉각적, 결정론적)에 가깝고, 세션 내 반성은 소프트웨어 인터럽트(의미론적 판단 필요)에 가깝고, 세션 간 기억은 디스크에 기록된 로그(영구 저장, 다음 부팅에 참조)에 가깝다.
피드백 루프가 "했는데 괜찮은가"를 검증한다면, 다음 질문은 검증 대상인 작업 자체에 대한 것이다. 어떤 순서로 쪼개고, 어떤 단위로 실행하고, 어떤 에이전트에게 맡길 것인가. 작업 분해와 워크플로우 설계가 에이전트의 행동 자체를 결정한다. 다음 편에서 이 문제를 다룬다.