AI 코드의 성적표
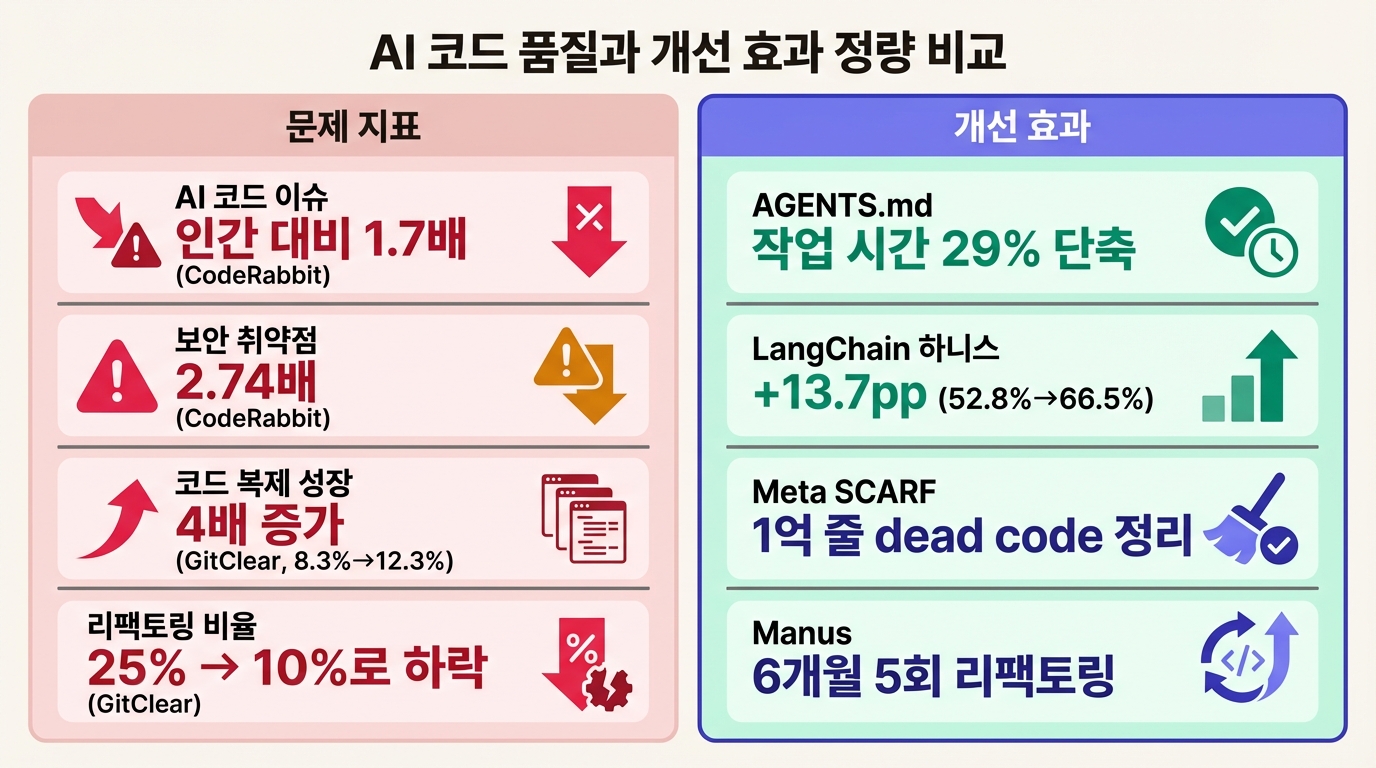
CodeRabbit이 470건의 GitHub PR을 분석했다. AI가 만든 코드의 PR당 이슈는 10.83건, 인간은 6.45건. 1.7배다. 보안 취약점은 2.74배, 가독성 문제는 3배 이상, 성능 이슈는 8배 가까이 벌어졌다. 그런데 OpenAI는 사람 코드 0줄로 100만 줄을 출하했고, Stripe는 주당 1,000건 이상의 PR을 에이전트로 머지한다.
코드를 잘 쓰는 게 아니라 코드를 계속 고치는 시스템이 있기 때문이다. 5편에서 워크플로우를 설계하는 것만큼 그 설계를 해체하고 재구축하는 일이 필요하다고 했다. 이번 편은 그 "재구축"의 구체적 방법론이다.
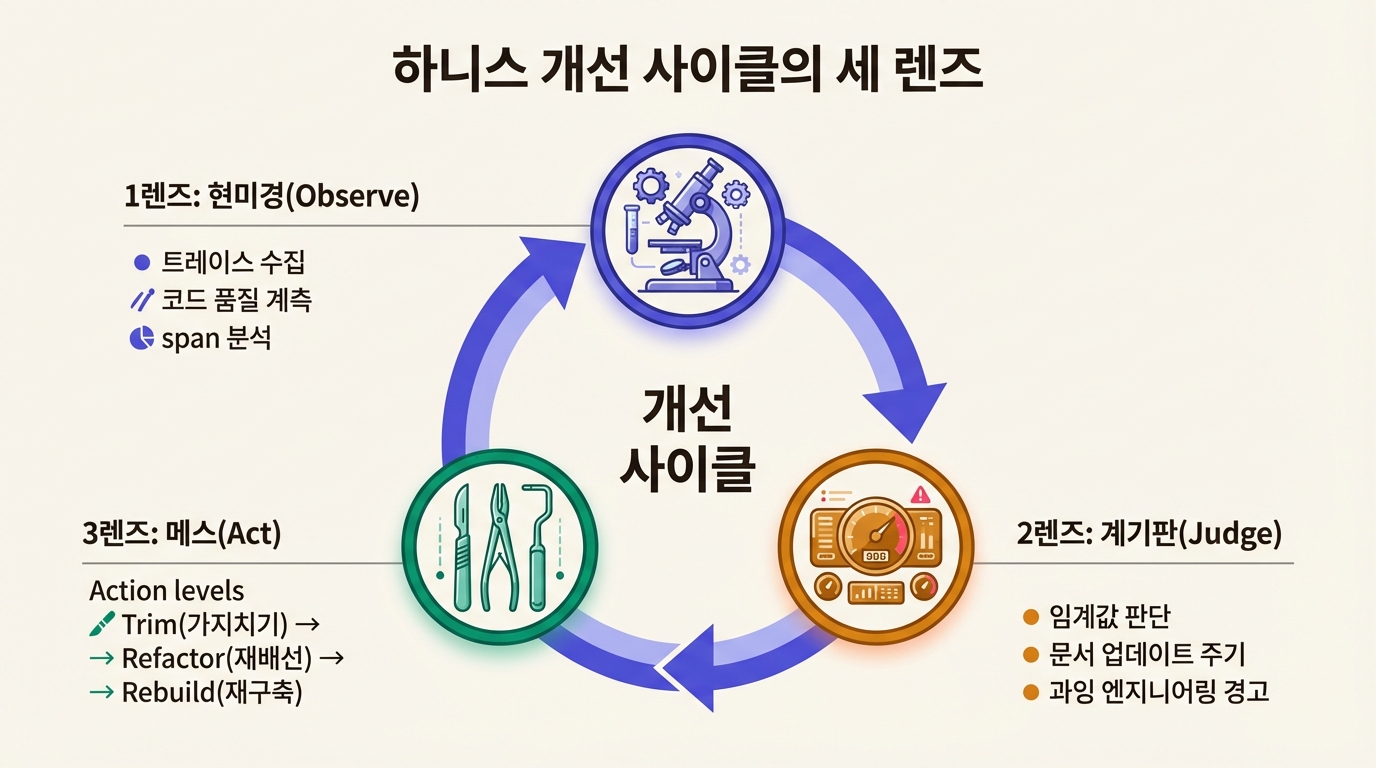
하니스 개선 사이클을 의료 진단에 빗대어 세 단계로 풀어본다.
| 단계 | 핵심 질문 |
|---|---|
| 현미경(Observe) | "지금 하니스에서 무슨 일이 벌어지고 있는가?" |
| 계기판(Judge) | "이 데이터가 말해주는 건 무엇이고, 언제 움직여야 하는가?" |
| 메스(Act) | "어디를 얼마나 잘라낼 것인가?" |
이전 편들이 "무엇이 있는가"를 분류했다면, 6편은 "어떤 순서로 무엇을 하는가"를 설계한다.
1. 보이지 않으면 고칠 수 없다
AI 코드는 다른 방식으로 썩는다
인간이 쌓는 기술 부채와 AI가 쌓는 기술 부채는 패턴이 다르다. GitClear가 2억 1,100만 줄의 코드 변경을 분석한 결과, AI 도구 보급 이후 코드 복제(clone)가 2021년 8.3%에서 2024년 12.3%로 뛰었다. "copy/paste"가 "moved" 코드를 역사상 처음 초과했다. 리팩토링 비율은 25%에서 10% 미만으로 쪼그라들었고, 신규 코드의 2주 내 수정률도 5.5%에서 7.9%로 올랐다. 빠르게 만들어지지만 빠르게 수정이 필요해지는 구조다.
이런 불량은 사람이 코드를 한 줄씩 읽어서 잡을 수 있는 종류가 아니다. 복제 비율, 수정률, 이슈 밀도 같은 지표를 깔아놓고 추이를 봐야 보인다.
트레이스가 문서를 대신한다
Arize AI가 이 관찰 구조를 5단계 자기 개선 루프로 정리했다. 에이전트가 태스크를 받고, 관련 코드에 계측을 심고, 변경을 실행하며 텔레메트리를 모으고, 트레이스를 쿼리해 동작을 검증하고, 평가와 피드백으로 반복한다.
Arize의 전제는 한 문장이다. "소프트웨어에서는 코드가 앱을 문서화하지만, AI에서는 트레이스가 문서화한다." 텔레메트리가 없으면 진실의 원천이 없고, 트레이스에 대한 평가가 없으면 "이 변경이 개선이다"라고 주장할 근거가 없다.
OpenAI Codex 팀이 이를 실전에 적용한 방식이 눈에 띈다. 에이전트에게 Query DSL로 트레이스 접근 권한을 주고, "서비스 시작 800밀리초 이내", "핵심 사용자 여정의 어떤 span도 2초 미만"처럼 성능 제약을 에이전트 지시문으로 변환했다. 관찰 기준이 곧 행동 지침이 되는 셈이다.
오픈소스 도구 Arize Phoenix가 진입 장벽을 낮춘다. OpenTelemetry 기반이라 특정 벤더에 묶이지 않고, CHAIN, LLM, TOOL, RETRIEVER 등 10종의 span kind를 지원한다.
어디부터 계측할 것인가
CodeRabbit 데이터를 다시 보면 우선순위가 보인다. 보안 취약점(2.74x)과 성능 이슈(약 8x)가 격차가 가장 큰 영역이다. 에러 핸들링(2x)과 동시성(2x)이 뒤를 따른다. 관찰 체계를 처음 깔 때 보안과 성능부터 계측하는 게 투입 대비 효과가 크다.
GitClear 데이터는 시간축의 필요성을 보여준다. 코드 품질은 한 시점의 스냅샷이 아니라 추이로 봐야 한다. 리팩토링 비율이 떨어지고 있는가, 복제 비율이 올라가는가, 2주 내 수정률이 높아지는가. 이런 추이 지표가 하니스의 활력 징후다.
2. 언제 움직일 것인가
관찰 데이터가 쌓이면 다음 질문이 생긴다. "이걸 보고 지금 뭘 해야 하는가?" 관찰은 필요조건이지 충분조건이 아니다. 데이터를 해석하고 행동 시점을 정하는 판단 체계가 필요하다.
22시간이라는 기준선
AGENTS.md를 분석한 학술 연구(arXiv 2601.20404)가 판단 빈도의 단서를 준다. 10개 리포지토리, 124개 PR을 분석한 결과, AGENTS.md가 있을 때 작업 완료 시간이 29% 줄었다(중앙값 70.34초 vs 98.57초). 출력 토큰도 17% 감소했다. 여기서 주목할 수치는 AGENTS.md의 중앙값 업데이트 간격인 22시간이다.
대략 하루에 한 번. 하니스의 핵심 문서가 하루 단위로 갱신된다는 건, 판단과 수정도 하루 단위로 돌아야 효과적이라는 뜻이다. 대부분의 변경은 50단어 이하의 추가나 미세 수정이었다. 대대적인 개편이 아니라 작은 조율의 반복. Mitchell Hashimoto의 철학("에이전트가 Bad Thing을 할 때마다, 다시는 일어나지 않도록 진지하게 노력한다")이 이 주기에 대응한다.
벤치마크라는 계기판
LangChain이 Terminal Bench에서 보여준 사례는 계기판의 힘을 직접 보여준다. 모델을 바꾸지 않고 하니스만 개선해서 52.8%에서 66.5%로 13.7pp를 올렸다. Top 30 밖에서 Top 5로 뛴 것이다. 바꾼 건 시스템 프롬프트, 도구, 미들웨어 훅 세 가지뿐이었다.
더 흥미로운 건 "reasoning sandwich" 패턴이다. 최고 reasoning 예산(xhigh)을 전 단계에 때려넣으면 53.9%에 그쳤다. 타임아웃에 걸렸기 때문이다. 단계별로 배분하면(xhigh로 계획, high로 중간 작업, xhigh로 검증) 63.6%까지 올라갔다. 자원을 고르게 쏟는 게 최적이 아니라는 걸 계기판(Terminal Bench 점수)이 알려준 것이다.
수치 너머의 판단
수치만으로 판단할 수 없는 영역도 있다. Phil Schmid의 원칙이 여기서 등장한다. "모델이 좋아지는데 하니스가 복잡해지고 있다면, 과잉 엔지니어링일 가능성이 높다." 2024년에 복잡한 파이프라인이 필요했던 기능이 2026년에는 단일 프롬프트로 처리된다. 모델 세대가 바뀔 때마다 하니스의 복잡도를 재점검하라는 원칙이다.
Pre-Rot 모니터링도 같은 맥락이다. 컨텍스트가 128K 토큰 임계값에 가까워지면 성능이 실제로 떨어지기 전에 압축이나 요약을 건다. 현재 벤치마크 대부분이 50번째 도구 호출 이후의 행동을 거의 테스트하지 않는다는 점이 이 선제적 판단의 배경이다. 리더보드에서 1% 차이를 다투는 건, 모델이 50단계 후에 궤도를 이탈할 때 신뢰성을 잡아주지 못한다.
3. 세 수준의 개입
관찰하고 판단했으면 실행해야 한다. 실행의 강도에 따라 세 수준으로 나눈다.
수준 1: 일상적 정리(Trim)
가장 가벼운 개입이다. 매일, 매주 단위로 불필요한 것을 잘라낸다.
Meta의 SCARF(Systematic Code and Asset Removal Framework)가 이 수준의 최대 규모 사례다. 수억 줄을 분석해 5년간 1억 줄 이상의 dead code를 37만 건의 변경 요청으로 삭제했다. 파일 단위가 아니라 심볼 단위 분석이다. 함수 안의 미사용 변수까지 탐지한다.
OpenAI도 주기적 가비지 컬렉션 에이전트를 돌린다. 문서 불일치와 아키텍처 위반을 탐지하는 에이전트, stale 문서를 스캔해서 정리 PR을 자동 생성하는 에이전트를 분리 운영한다. Hashimoto의 AGENTS.md 공진화 철학도 이 수준에 해당한다. "Bad Thing이 생기면 다시는 안 되게" 문서를 고치는 건 하루 단위의 소규모 정리다.
수준 2: 구조적 개선(Refactor)
매주에서 매월 단위의 변경이다. 아키텍처의 일부를 재설계한다.
LangChain이 Terminal Bench에서 한 일이 전형적이다. 시스템 프롬프트를 재작성하고, 도구를 재구성하고, 미들웨어 훅을 손봤다. 모델은 그대로인데 순위가 30위 밖에서 5위로 뛰었다.
Vercel은 에이전트에게 제공하던 도구의 80%를 제거했다. 도구가 적어지니 선택 단계가 줄고 응답이 빨라졌고, 정확도가 80%에서 100%로 올랐다. "더 많이 주면 더 잘한다"는 직관의 반대다. Manus도 초기 100개 이상이던 도구를 3계층 구조(핵심 원자 도구 약 20개 + 샌드박스 유틸 + 코드/패키지)로 정리했다. 토큰의 약 30%를 지속적으로 재작성되는 태스크 파일에 낭비하고 있었다는 진단이 계기였다.
수준 3: 전면 재구축(Rebuild)
분기에서 반기 단위의 전면 교체다. 기존 하니스를 버리고 처음부터 다시 만든다.
Manus가 6개월간 5회 리팩토링을 거쳤다. LangChain의 Open Deep Research는 1년간 3회 완전 재설계되었다. Phil Schmid의 "Build to Delete" 원칙이 여기서 실행 지침이 된다. 아키텍처를 모듈화하라. 새 모델이 현재 로직을 대체할 것이므로 코드를 뜯어낼 준비가 되어 있어야 한다.
Trim은 나뭇잎을 다듬는 일, Refactor는 가지를 치는 일, Rebuild는 나무를 뽑고 새로 심는 일이다. 셋 모두 필요하다. Trim만 하면 구조적 문제가 쌓이고, Rebuild만 하면 안정성이 깨진다.
관찰하는 사람도 달라진다
관찰, 판단, 실행을 다루면서 빠트리기 쉬운 게 있다. 이 세 단계를 수행하는 "사람"의 역할도 바뀌고 있다는 사실이다.
Arize가 이 전환을 한 문장으로 정리했다. "인간의 역할은 모든 변경을 리뷰하는 것에서, 검증 메커니즘 자체를 감사하는 것으로 바뀐다." 코드를 검사하는 게 아니라 코드를 검사하는 시스템을 검사한다.
이 전환은 세 단계를 거쳤다. 2024년(Autocomplete 시대)에 AI는 문서화나 유틸 함수 같은 단순 작업을 도왔고 사람이 주도권을 쥐었다. 2025년(Conductor 시대)에 엔지니어가 LLM에 지시하고 출력을 리뷰하는 지휘자 역할로 옮겨갔다. 2025년 말부터(Orchestrator 시대) 자율 에이전트가 동시에 작업하고 엔지니어는 배치와 통합에 집중한다. OpenAI에서 3명이 100만 줄을 출하하면서 한 일은 코드를 쓰는 게 아니라 "에이전트가 성공할 수 있는 아키텍처를 설계하는 것"이었다.
Anthropic의 2026 보고서에 따르면 개발자가 작업의 약 60%에 AI를 쓰지만, 완전히 맡길 수 있는 태스크는 0~20%에 불과하다. 80% 이상은 여전히 사람 손이 필요하다. 사라지는 게 아니라, 코드 한 줄의 품질에서 시스템 전체의 작동으로 시야가 이동하는 것이다.
"알고리즘 퍼즐을 좋아하는 엔지니어는 에이전트 네이티브 전환에 어려움을 겪고, 제품 출하를 좋아하는 엔지니어는 빠르게 적응한다"는 관찰이 이 전환의 성격을 요약한다. 개선 사이클에 필요한 역량은 출력 검증, 워크플로우 디버깅, 예산 관리다. 알고리즘을 직접 짜는 능력이 아니라 에이전트가 짠 결과를 평가하고 하니스를 조율하는 능력이다.
재귀하는 사이클
현미경으로 관찰하고, 계기판으로 판단하고, 메스로 실행하면 하니스가 개선된다. 그런데 이 사이클 자체도 고정이 아니다.
관찰 대상이 바뀐다. 새로운 유형의 실패가 등장하면 새로운 지표가 필요하다. 판단 기준이 바뀐다. 모델 세대가 교체되면 "복잡하다"의 기준선이 달라진다. 실행 수단이 바뀐다. 더 정교한 GC 에이전트가 나오면 Trim의 범위가 넓어진다. 개선 사이클이 자기 자신을 개선하는 재귀 구조다.
여섯 편에 걸쳐 하니스의 개념, 전체 지도, 아키텍처 제약, 피드백 루프, 워크플로우 제어, 개선 사이클을 다뤘다. 이제 관찰하고, 판단하고, 실행하는 사이클까지 갖췄다. 다음 편에서는 이 모든 것을 하나로 엮는다. 오늘 당장, 어떤 도구로, 어떤 파일부터 만들면 되는가. 팀 규모별 하니스 세팅 가이드로 시리즈를 마무리한다.