원문: Enhancing Reasoning Capabilities of Small Language Models with Blueprints and Prompt Template Search | ICML 2025 Workshop (TTODLer-FM) | Dongge Han et al.
왜 이 논문이 중요한가
GPT-4나 Claude 같은 대형 모델은 "한 단계씩 생각해봐"라는 한 줄만 덧붙여도 복잡한 수학 문제를 풀어낸다. 그런데 Phi-3-mini(3.8B)나 Mistral-7B 같은 소형 모델에 같은 프롬프트를 넣으면 결과가 들쭉날쭉하다. 예시 하나의 위치만 바꿔도, 설명 한 줄을 앞에 놓느냐 뒤에 놓느냐에 따라 정확도가 10% 이상 요동친다.
이 논문은 그 문제에 정면으로 맞선다. 소형 모델이 추론을 못 하는 게 아니라, 추론을 이끌어내는 프롬프트 설계가 부실했던 것이라는 가설에서 출발한다. 마이크로소프트 리서치 팀은 두 가지 도구를 제안했다. 하나는 대형 모델이 만들어주는 "사고의 설계도(Blueprint)"이고, 다른 하나는 프롬프트 구성 요소의 최적 조합을 자동으로 찾아주는 "Template Search"다. 이 두 가지를 결합하자, 추가 학습 없이도 Mistral-7B의 코딩 성능이 20%포인트 뛰어올랐다.
모델을 키우지 않고, 파인튜닝도 하지 않으면서, 프롬프트만으로 소형 모델의 성능 천장을 높인다. 온디바이스 AI, 엣지 컴퓨팅, 그리고 API 비용에 민감한 실무 환경에서 이 접근법이 갖는 의미는 상당하다.
Background
소형 언어 모델의 딜레마
언어 모델의 추론 능력은 파라미터 수에 비례한다는 것이 오랫동안 통설이었다. Chain-of-Thought(CoT) 프롬프팅이 GPT-3(175B)에서 처음 효과를 보인 이후, "모델이 충분히 커야 사고 과정을 따라할 수 있다"는 관찰이 굳어졌다. 실제로 100B 미만 모델에서 CoT를 적용하면 오히려 성능이 떨어지는 경우도 보고되었다.
하지만 최근 흐름은 다르다. Phi-3, Mistral, Gemma 같은 소형 모델들이 데이터 큐레이션과 학습 기법 개선을 통해 자신의 체급을 넘어서는 성능을 보여주기 시작했다. EMNLP 2025에서 발표된 ThinkSLM 벤치마크는 72개 소형 모델을 체계적으로 평가한 뒤, "추론 능력은 규모보다 학습 방법과 데이터 품질에 더 크게 좌우된다"는 결론을 내렸다.
프롬프트 민감도 문제
소형 모델에는 대형 모델과 구별되는 고유한 약점이 있다. 프롬프트의 사소한 변화에 과도하게 반응한다는 점이다. 예시를 세 개에서 두 개로 줄이거나, 설명 문구의 위치를 옮기기만 해도 정확도가 크게 흔들린다. 이 논문의 저자들은 이 현상을 실험으로 직접 확인했다. Phi-3-mini의 경우, 같은 과제에서 프롬프트 구성만 바꿨을 때 정확도가 11%포인트까지 달라졌다.
이는 실무에서 치명적이다. 프롬프트 엔지니어가 하나의 과제에 맞춰 프롬프트를 최적화해도, 다른 유형의 질문이나 다른 모델에 적용하면 효과가 사라진다. 수작업 최적화의 한계가 명확한 지점이다.
자동 프롬프트 최적화(APO)의 등장
이 문제를 해결하려는 시도가 Automatic Prompt Optimization(APO)이다. 2023년 EMNLP에서 발표된 원조 APO(ProTeGi)는 "텍스트 그래디언트"라는 개념을 도입했다. 신경망에서 손실 함수의 기울기가 가중치 업데이트 방향을 알려주듯, LLM이 현재 프롬프트의 문제점을 자연어로 비평하고, 그 비평 방향의 반대로 프롬프트를 수정하는 방식이다. 이 논문은 APO를 소형 모델 환경에 맞게 확장하면서, 그 위에 Blueprint라는 새로운 레이어를 얹었다.
Problem Statement
핵심 질문은 이것이다: 추가 학습 없이, 프롬프트 설계만으로 소형 LLM의 추론 능력을 체계적으로 향상시킬 수 있는가?
구체적으로 세 가지 하위 문제를 다룬다.
첫째, 소형 모델은 단순한 CoT 프롬프트만으로는 복잡한 추론 과제를 안정적으로 수행하지 못한다. 대형 모델이 자연스럽게 따르는 추론 패턴을 소형 모델에게 더 명시적으로 안내할 방법이 필요하다.
둘째, 같은 과제라도 프롬프트 템플릿의 구성(예시 수, 설명 위치, CoT 포함 여부)에 따라 성능이 크게 달라진다. 최적 구성을 수작업으로 찾는 것은 비현실적이다.
셋째, 하나의 프롬프트 전략이 모든 모델과 과제에 통용되지 않는다. 모델별·과제별로 최적의 조합이 다르다는 점을 체계적으로 다룰 프레임워크가 필요하다.
Proposed Method
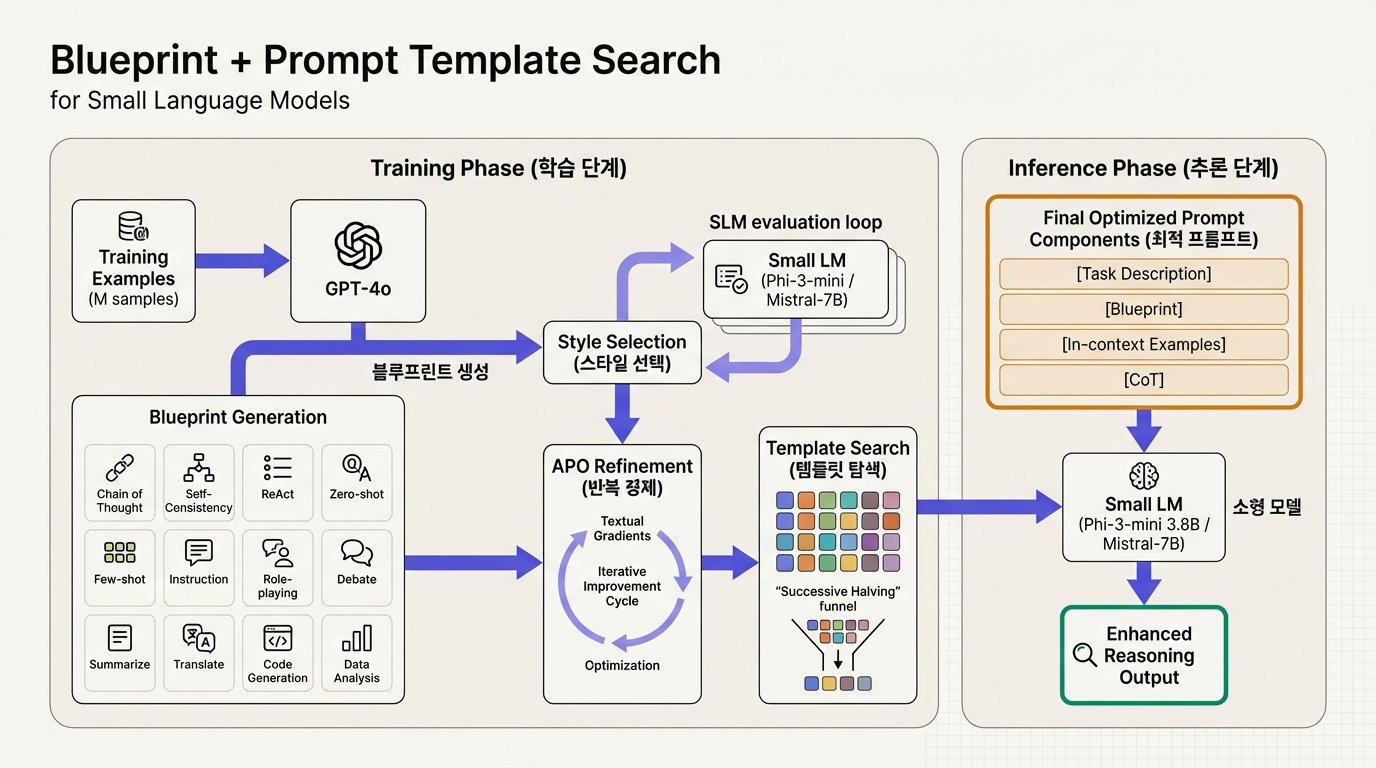
이 프레임워크는 크게 네 단계로 구성된다. 비유하자면, 경험 많은 선배(LLM)가 후배(SLM)에게 맞춤형 풀이 전략서를 만들어주고, 그 전략서를 어떤 형태로 전달할 때 가장 잘 알아듣는지까지 자동으로 찾아주는 시스템이다.
1단계: Blueprint 생성
Blueprint는 특정 유형의 문제를 풀기 위한 고수준 추론 가이드다. 수학 문제를 예로 들면, "먼저 주어진 조건을 정리하고, 적용할 공식을 결정하고, 단계별로 계산을 수행하라"는 식의 구조화된 지침이다.
생성 과정은 이렇다. 과제 유형별로 학습 데이터에서 M개의 예시를 추출한 뒤, GPT-4o에게 "이 문제들을 관통하는 공통 추론 패턴을 추출하라"고 요청한다. GPT-4o는 해당 유형의 문제를 풀 때 반복적으로 등장하는 사고 단계를 정리하여 Blueprint로 만들어낸다.
2단계: Blueprint 스타일 선택
같은 추론 전략이라도 표현 방식에 따라 소형 모델의 이해도가 달라진다. 연구팀은 12가지 스타일(간결한 개요형, 불릿 포인트형, 구체적 예시형, 의사결정 트리형 등)을 정의하고, 각 스타일로 Blueprint를 변환한 뒤 소형 모델에서 직접 테스트하여 최적 스타일을 선택한다.
흥미로운 점은 모델마다 선호하는 스타일이 다르다는 것이다. GPT-4o-mini는 어떤 스타일을 줘도 성능 차이가 3% 이내였지만, Phi-3-mini는 스타일에 따라 11%, Mistral-7B는 12%까지 차이가 벌어졌다. 모델이 작을수록 정보의 제시 방식에 민감하다는 것을 보여주는 결과다.
3단계: APO를 통한 Blueprint 정제
선택된 Blueprint를 반복적으로 개선한다. 소형 모델이 Blueprint를 따르면서도 틀린 문제들을 분석하여, LLM이 "텍스트 그래디언트"(개선 방향을 자연어로 서술한 것)를 생성한다. 이 그래디언트를 반영하여 Blueprint를 수정하고, 다시 평가하는 과정을 반복한다. 매 라운드마다 25개의 학습 예시로 평가하며, 가장 높은 정확도를 보이는 버전을 유지한다.
4단계: Prompt Template Search
마지막으로, Blueprint 외에 프롬프트를 구성하는 나머지 요소들의 최적 조합을 찾는다. 탐색 공간은 네 가지 축으로 구성된다.
- 인컨텍스트 예시 수: 0, 1, 2, 3개
- 과제 설명 위치: 예시 앞 또는 뒤
- Blueprint 포함 여부: 포함 또는 미포함
- CoT 포함 여부: 포함 또는 미포함
4 × 2 × 2 × 2 = 32가지 조합이 만들어진다. 이 중 최적 조합을 찾기 위해 Successive Halving 알고리즘을 적용한다. 32개 후보를 5개 샘플로 평가하고, 하위 절반을 탈락시킨 뒤, 남은 후보를 새로운 샘플로 재평가하는 과정을 반복한다. 과제 유형당 약 310회의 SLM 호출로 최적 템플릿을 결정할 수 있다.
실험 결과
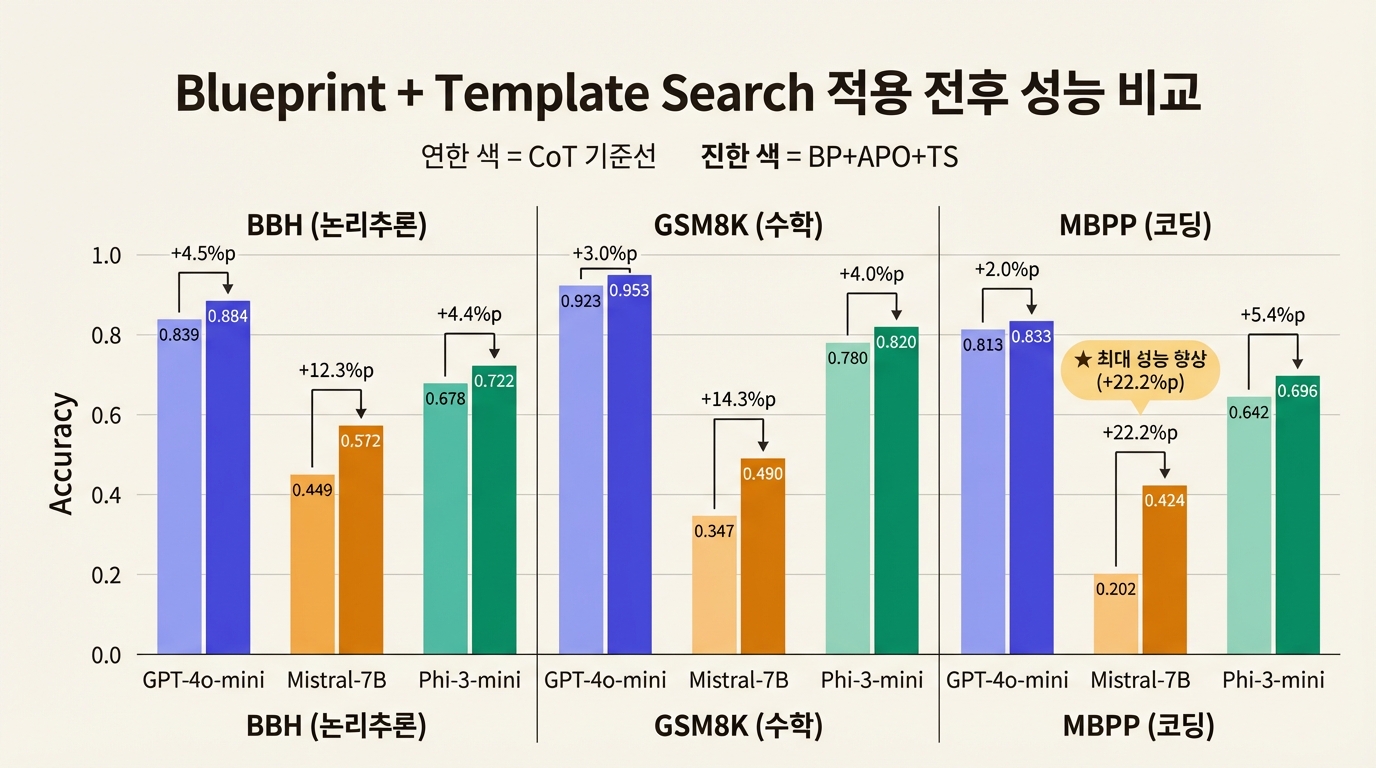
실험 설정
세 가지 모델(GPT-4o-mini, Mistral-7B, Phi-3-mini)을 세 가지 벤치마크(BBH 논리추론, GSM8K 수학, MBPP 코딩)에서 평가했다. 기준선은 표준 CoT 프롬프팅(1-shot, 3-shot)이다.
주요 결과
가장 눈에 띄는 성과는 Mistral-7B에서 나왔다. MBPP 코딩 벤치마크에서 CoT 3-shot 대비 정확도가 0.202에서 0.424로, 무려 22.2%포인트 상승했다. 같은 모델의 GSM8K 수학에서도 0.347에서 0.490으로 14.3%포인트 올랐다.
Phi-3-mini(3.8B)도 일관된 개선을 보였다. BBH에서 0.678→0.722(+4.4%p), GSM8K에서 0.780→0.820(+4.0%p), MBPP에서 0.642→0.696(+5.4%p). 모든 벤치마크에서 빠짐없이 성능이 올랐다.
상대적으로 큰 모델인 GPT-4o-mini에서는 개선폭이 작았지만, 이미 높은 기준선에서도 추가 개선이 있었다. GSM8K에서 0.923→0.953(+3.0%p), BBH에서 0.839→0.884(+4.5%p).
각 구성 요소의 기여
Blueprint만 추가해도(APO나 Template Search 없이) 대부분의 경우 CoT 기준선을 넘어선다. APO 정제는 보통 1-3%포인트의 추가 개선을 가져오지만, Mistral-7B의 GSM8K에서는 13%포인트라는 예외적인 도약을 만들어냈다. Template Search는 BBH에서 2-4%포인트의 개선을 보였으나, 일부 조합에서는 미미한 성능 저하도 관찰되었다. 이는 제한된 평가 샘플(라운드당 5개)에서 오는 노이즈로 추정된다.
비용 효율성
전체 최적화 과정에서 소형 모델 호출은 과제 유형당 약 310회에 불과하다. Blueprint 생성과 APO 정제에 필요한 GPT-4o 호출도 수십 회 수준이다. 파인튜닝에 필요한 GPU 시간과 데이터 준비 비용을 생각하면, 이 접근법의 비용 효율성은 압도적이다.
Discussion & Limitations
이 논문이 던지는 가장 강력한 메시지는 "소형 모델의 한계는 모델 자체가 아니라 프롬프트 설계에 있을 수 있다"는 것이다. 같은 3.8B 모델이 프롬프트 구성에 따라 10% 이상의 성능 차이를 보인다면, 모델을 키우기 전에 프롬프트부터 최적화하는 것이 합리적이다.
실용적 관점에서, 이 프레임워크는 모델 재학습 없이 작동한다. 새로운 과제 유형이 추가되면 해당 유형에 대한 Blueprint만 생성하면 된다. 엣지 디바이스에 배포된 모델의 성능을 서버 쪽에서 프롬프트만 업데이트하여 개선할 수 있다는 뜻이다.
그러나 한계도 분명하다. Blueprint 생성에 GPT-4o 같은 대형 모델이 필요하다. 대형 모델 없이 소형 모델만으로 자체적인 Blueprint를 생성할 수 있는지는 미탐구 영역이다. 또한 평가 대상이 세 개 모델, 세 개 벤치마크로 제한적이다. BBH 28개 하위 카테고리에서의 세분화된 분석이 있긴 하지만, 자연어 이해(NLU)나 대화, 요약 같은 생성 과제에서의 효과는 검증되지 않았다.
Template Search의 탐색 공간(32가지)도 현실적으로 충분한지 의문이 남는다. 프롬프트의 어조, 언어(영어 vs. 모델 학습 언어), 예시의 난이도 배열 같은 요소는 다루지 않았다. 더불어, 각 라운드에서 5개 샘플만으로 후보를 절반씩 탈락시키는 방식은 노이즈에 취약할 수 있고, 실험 결과에서도 이 문제가 간헐적으로 관찰되었다.
이 논문에서 던질 질문 3개
-
Blueprint의 자기 생성은 가능한가? 소형 모델이 자신의 추론 실패를 분석하여 자체 Blueprint를 점진적으로 구축하는 self-improving 방식이 가능할까? 대형 모델 의존성을 제거할 수 있다면 이 프레임워크의 실용성은 한 단계 더 올라간다.
-
다국어 환경에서의 Blueprint 전이: 영어로 생성된 Blueprint가 한국어나 일본어 프롬프트에서도 동일한 효과를 보일까? 소형 모델의 다국어 추론 능력과 프롬프트 언어 간의 상호작용은 별도의 연구가 필요한 영역이다.
-
Blueprint와 파인튜닝의 결합: Blueprint 기반 프롬프팅과 LoRA 같은 경량 파인튜닝을 결합하면 시너지가 발생할까, 아니면 중복될까? 두 접근법이 모델의 서로 다른 능력을 활성화한다면, 결합 효과는 상당할 수 있다.
관련 논문
- ThinkSLM: Towards Reasoning in Small Language Models (Srivastava et al., EMNLP 2025), 72개 SLM의 추론 능력 벤치마크
- PMPO: Probabilistic Metric Prompt Optimization for Small and Large Language Models (Zhao et al., 2025), 토큰 수준 교차 엔트로피를 활용한 프롬프트 최적화
- Automatic Prompt Optimization with "Gradient Descent" and Beam Search (Pryzant et al., EMNLP 2023), 텍스트 그래디언트 기반 자동 프롬프트 최적화의 원류
출처
- Han, D. et al. (2025). Enhancing Reasoning Capabilities of Small Language Models with Blueprints and Prompt Template Search. ICML 2025 Workshop (TTODLer-FM). arXiv:2506.08669
- Srivastava, G. et al. (2025). ThinkSLM: Towards Reasoning in Small Language Models. EMNLP 2025 Main. arXiv:2502.11569
- Pryzant, R. et al. (2023). Automatic Prompt Optimization with "Gradient Descent" and Beam Search. EMNLP 2023.
- Zhao, C. et al. (2025). PMPO: Probabilistic Metric Prompt Optimization for Small and Large Language Models. arXiv:2505.16307
- Wei, J. et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS 2022. arXiv:2201.11903